
写文章




- @weixin_56956615
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
【PyTorch深度学习实践】03_反向传播
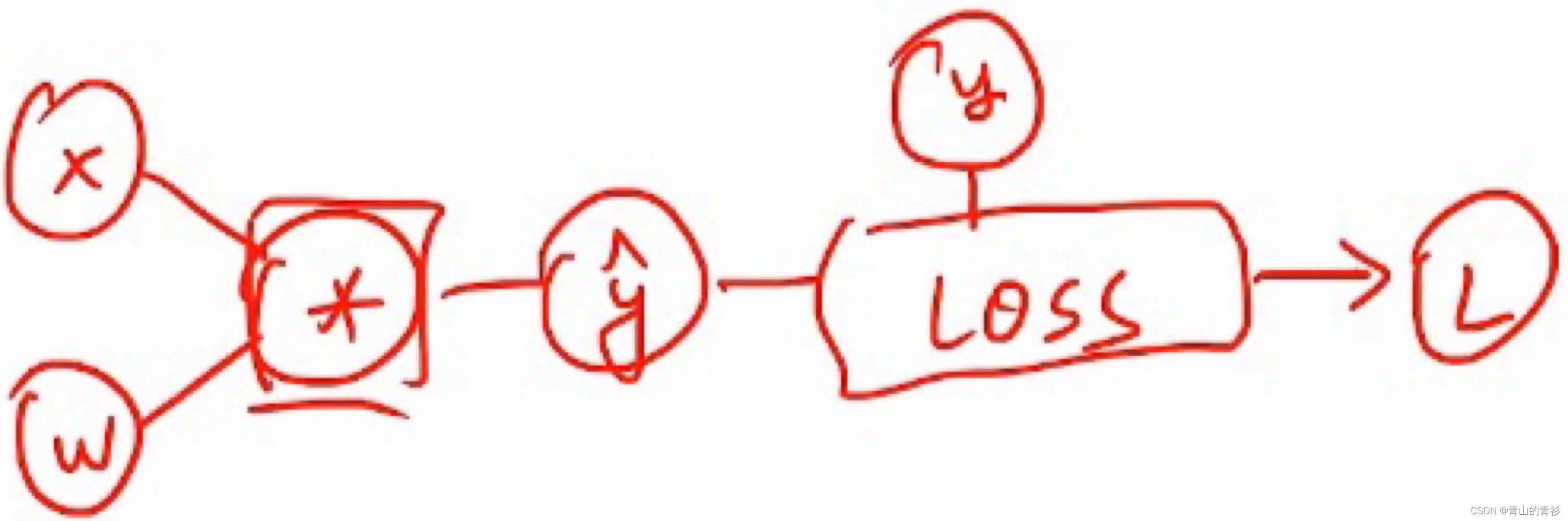
在PyTorch中,torch.Tensor类是存储和变换数据的重要工具,相比于Numpy,Tensor提供GPU计算和自动求梯度等更多功能,在深度学习中,我们经常需要对函数求梯度(gradient)。里面包含两个比较重要的成员data(比如权重值)和grad(损失函数对权重的导数)有两个重要的成员,一个是data(保存权重w),一个是grad(保存损失函数对权重的导数)。对于简单的模型,梯度变换
【PyTorch深度学习实践】03_反向传播
在PyTorch中,torch.Tensor类是存储和变换数据的重要工具,相比于Numpy,Tensor提供GPU计算和自动求梯度等更多功能,在深度学习中,我们经常需要对函数求梯度(gradient)。里面包含两个比较重要的成员data(比如权重值)和grad(损失函数对权重的导数)有两个重要的成员,一个是data(保存权重w),一个是grad(保存损失函数对权重的导数)。对于简单的模型,梯度变换
【数学建模】优劣解距离法(TOPSIS法)
评价类问题,充分利用原始数据的信息,精确反应各个评价方案之间的差距。公式不唯一公式不唯一(但我也没想到更好的)不唯一不唯一,这只是前人论文中用的较多的一种标准化方法。未完待续…...
【PyTorch深度学习实践】04_用PyTorch实现线性回归
1.准备数据集 dataset和dataloader 2.设计模型 3.构造损失函数和优化器4.训练过程前馈(算损失)、反馈(算梯度)、更新(用梯度下降更新)
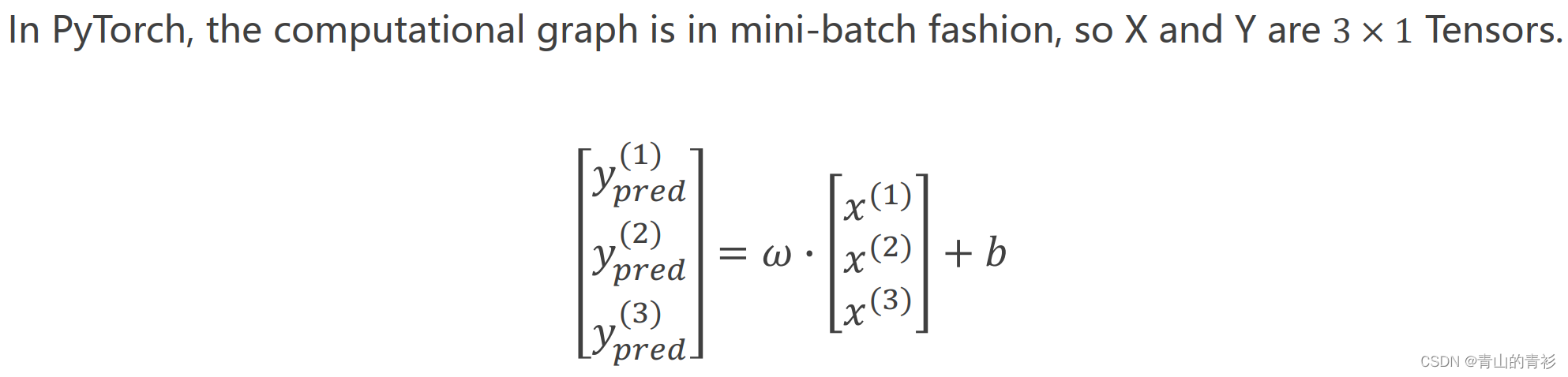
【PyTorch深度学习实践】08_Softmax分类器(多分类)
当需要多分类的时候,会输出一个分布,这些分布需要满足`P(y = i) >=0 和 所有的P值加起来=1`,使用softmax可以实现。
到底了