




- @weixin_54227557
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
3条都执行了,还有报错,看来layer有问题,明天解决一下。就可以体验jupyterlab环境了。prototype原型、最初形态。仔细看json文件,有不少怪异符号。benchmark基准检测。进入openvino专区。
参考:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/600alpha003/developmenttools/devtool/atlasprofiling_16_0090.html。【两个文件,各10分,共20分】通过profile对比,我们可以看到,耗时大的算子时间有了明显的减少,对比耗时情况,在语义相同的情况下
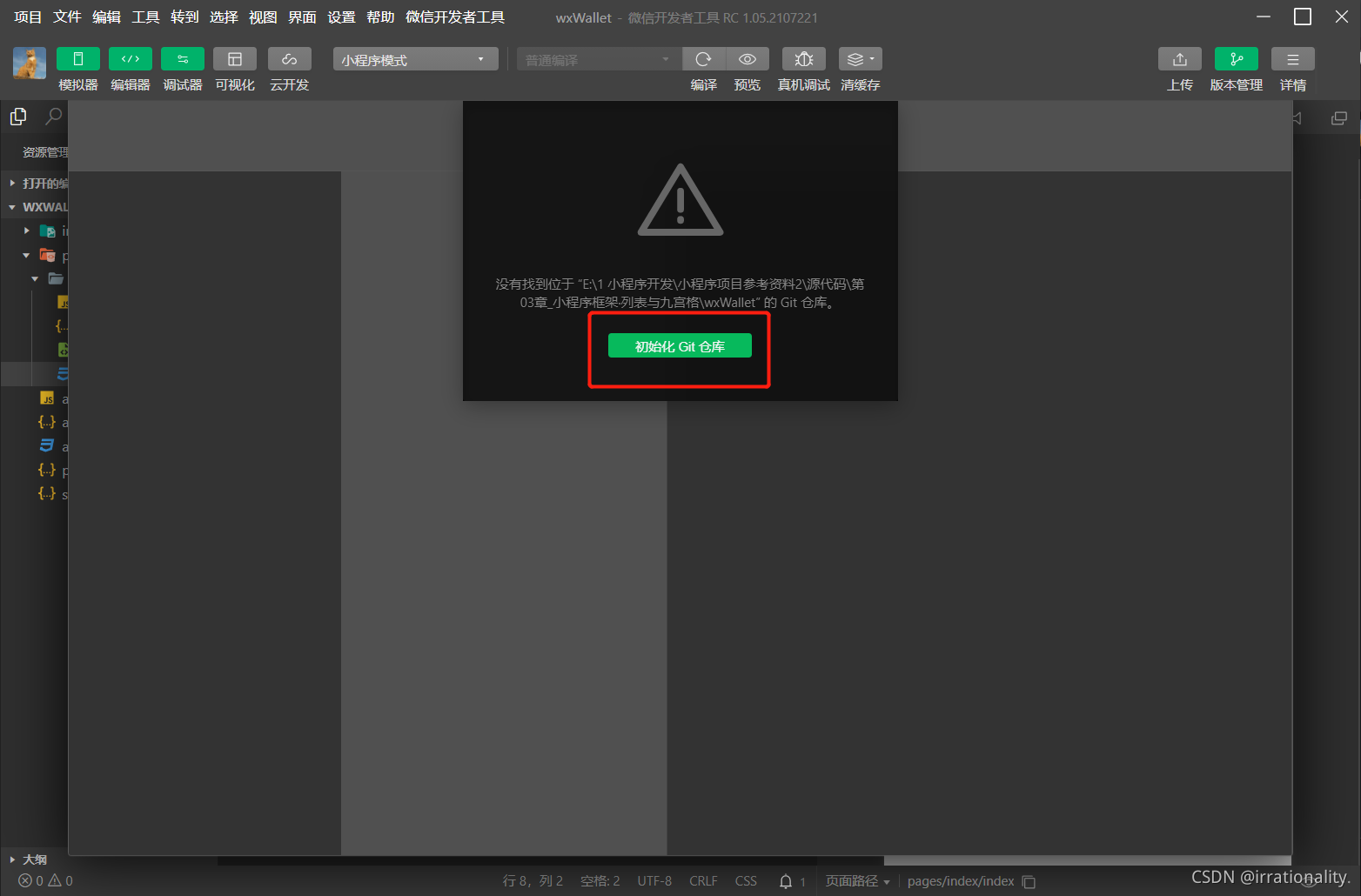
最近研究了一下微信小程序,感觉和vue思想几乎一致,自己也在写一些小Demo进行练习,但是考虑到需要进行版本控制,于是研究了一下将项目上传到github的步骤,网上也有很多其他博主写的相关文章,我也是踩了很多坑才成功,下面来和大家分享一下:Step1:点击开发工具右上角的版本控制按钮Step2:点击初始化仓库:等待初始化结束Step3:在github新建仓库:复制仓库地址:(HTTP)Step4:
大二下暑假的时候参加了中国科学院OSPP开源之夏活动,作品是在MindSpore开源代码仓提交一个PR,增加创建Tensor的方法。这是我第一次参加正式的开源活动,对开源的热情就此一发不可收拾。经过项目初次选拔后的两星期左右,我开始着手做本项目。由于之前对深度学习的了解仅限于构建网络进行训练和深度学习库的使用,很少接触深度学习框架一些底层代码的开发,中间也遇到了不少困难,但却能更好地体验开源世界带
题目:实现更丰富的数据预处理策略,穿插MindSpore预定义的数据增强API、以及自定义的python function操作。定义两个函数,一个是张量形状的推导函数(infer_shape),另一个是张量数据类型的推导函数(infer_dtype)。使用作业模板提供的测试代码测试基于上面函数的pyfunc类型自定义算子,并与MindSpore自带的Sin算子作为比较。题目:使用MindSpore
本项目中,我们使用MindSpore和GPT实现了情感分类模型,完成了IMDB数据集的加载、预处理、模型构建、训练和测试全过程。在单个epoch的训练过程中,我们达到了约90%的分类准确率。未来可以进一步尝试更复杂的预训练模型、多样化的超参数配置,以及更长的训练周期来提升模型性能。
经过模型训练和评估后,我们得到了最终的结果。该模型能够有效地对IMDB数据集中的文本进行情感分类,并输出相关的评估指标。通过上述步骤,我们使用MindSpore平台和GPT模型实现了情感分类任务,能够有效地对文本进行情绪分析,提供情感分类的预测结果。这一过程展示了GPT模型在自然语言处理任务中的应用,尤其是在情感分析方面的表现。
找到该python环境对应地pip位置,一般是xxx/bin/pip,然后使用xxx/bin/pip install package ,或者将该指令软连接到pip,这样再使用pip install package,就可以了。最后发现居然不知道是自己好久手抽,导致把transferPic.py的代码给改错了,现在终于对了。找到该python环境地位置,如/home/ls/nanconda3/bin/
直接在cann6.0测试即可。
经过非常简单的调整,我们就可以和强化学习下棋了。我又一次成功战胜了机器人,真不错。这样就可以直接跑起来了。