- @weixin_52286364
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
《GPU性能优化实战:Nsight工具与Profiling技术解析》 本文系统介绍了GPU性能分析(Profiling)的核心方法和NVIDIA Nsight工具套件的使用。文章首先解释了Profiling的概念,即通过性能指标分析找出程序瓶颈的技术。然后详细介绍了Nsight家族三大工具:系统级分析的Nsight Systems、核函数级分析的Nsight Compute和图形渲染分析的Nsig
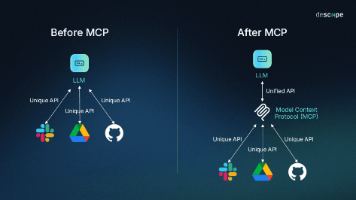
本文系统梳理了大模型领域的四大关键技术:Prompt(提示词工程)、AIAgent(智能体)、FunctionCalling(函数调用)和MCP(模型上下文协议)。Prompt是与大模型交互的语言,AIAgent是具备感知-决策-执行能力的数字员工,FunctionCalling让模型能调用外部工具,而MCP则统一了工具调用的通信标准。文章通过关系图谱阐明四者的层级关联,并提供了5分钟搭建MCPS
本文提供了一份完整的YOLOv8目标检测模型训练教程,涵盖从环境配置到模型训练的完整流程。教程详细介绍了PyCharm安装、conda环境搭建、GPU驱动配置(CUDA/cuDNN)、LabelImg数据标注工具使用,以及如何准备自定义数据集和训练YOLOv8模型。特别针对Windows系统用户,给出了详细的路径设置和常见问题解决方案。文章还包含了模型验证和推理方法,并提供了训练参数调整建议。本教
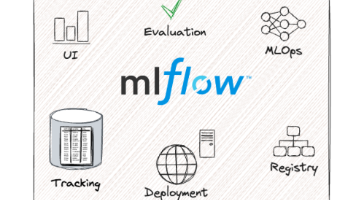
MLflow是一款开源机器学习生命周期管理工具,可解决实验追踪、模型管理和部署难题。核心功能包括:实验追踪记录参数和指标、模型注册中心集中管理版本、标准化模型打包格式,以及一键部署为REST API。通过代码示例演示了从训练Sklearn模型到注册部署的全流程,配合UI界面直观展示运行记录和版本管理。该工具将机器学习开发的实验结果可追溯、模型可管理、部署可复现三大需求整合为统一平台,适合个人研究者
大模型训练是典型的资本密集型技术,以GPT-4为例需要2.5万张A100显卡连续运行百天,算力成本超6300万美元。核心成本构成包括:1)硬件投入(单张A100售价超10万元);2)海量数据清洗(GPT-3消耗45TB数据);3)惊人能耗(万卡集群功耗达4MW);4)复杂工程调试。推理阶段同样面临显存挑战,70B参数模型加载需140GB显存,长文本处理更需额外32GB。为降本增效,业界采用知识蒸馏

本文提供了一份完整的YOLOv8目标检测模型训练教程,涵盖从环境配置到模型训练的完整流程。教程详细介绍了PyCharm安装、conda环境搭建、GPU驱动配置(CUDA/cuDNN)、LabelImg数据标注工具使用,以及如何准备自定义数据集和训练YOLOv8模型。特别针对Windows系统用户,给出了详细的路径设置和常见问题解决方案。文章还包含了模型验证和推理方法,并提供了训练参数调整建议。本教
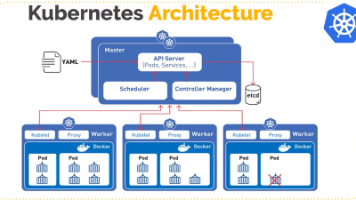
Docker与Kubernetes核心解析 Docker通过镜像打包应用及环境,实现"一次构建,到处运行",解决开发与生产环境差异问题。其轻量化容器启动快、隔离性强,适合微服务架构。Kubernetes(K8s)作为容器编排系统,管理大规模容器集群,提供自动扩缩容、服务发现、滚动升级等能力。两者关系互补:Docker负责单容器运行,K8s调度集群资源。典型应用场景包括微服务部署
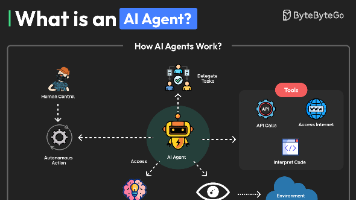
本文系统梳理了AIAgent(智能体)的核心概念与发展趋势。AIAgent是基于大语言模型(LLM)的智能决策单元,具备感知环境、规划任务、执行行动等能力,可调用工具、访问知识库完成复杂任务。其核心架构包括感知、推理、工具调用、记忆、执行和反馈等模块。主要类型有单智能体、多智能体协作和人机协作模式。关键能力包括检索增强、记忆机制、任务拆解等。文章分析了Auto-GPT等典型案例,提出角色定义、监测
大模型训练是典型的资本密集型技术,以GPT-4为例需要2.5万张A100显卡连续运行百天,算力成本超6300万美元。核心成本构成包括:1)硬件投入(单张A100售价超10万元);2)海量数据清洗(GPT-3消耗45TB数据);3)惊人能耗(万卡集群功耗达4MW);4)复杂工程调试。推理阶段同样面临显存挑战,70B参数模型加载需140GB显存,长文本处理更需额外32GB。为降本增效,业界采用知识蒸馏
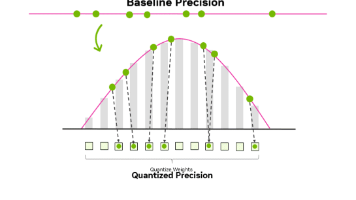
pass对称量化:零点为 0,计算快,适合权重。非对称量化:零点可调,适合非零中心分布(如 ReLU 激活)。TensorRT 提供 Calibrator,支持两种量化方式,可灵活选择。💡下一课预告:带大家搞懂直方图校准 + KL 散度—— 把极端值(outlier)踢出去,scale 选得更聪明。👉 如果文章帮到你,记得点个「赞」👍 支持一下,评论区欢迎贴代码/交流问题,我会在线答疑~#