




- @weixin_52263647
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在使用SGLang部署Qwen3 Reranker系列模型时,由于模型架构差异会出现API不兼容问题。本文将基于生成式架构的Qwen3ForCausalLM转换为二分类模型Qwen3ForSequenceClassification,通过提取yes,no token的权重向量构建新的分类器,最终使用classify接口实现模型部署。该方法借鉴了VLLM的解决思路,成功实现了SGLang部署Qwen

VLLM部署Qwen3 重排模型时会出现不支持Score、rerank API错误,原因是vllm 目前没有办法允许单个架构同时支持嵌入和重排,解决方法是将( Qwen3ForCausalLM)模型转换为序列分类架构(Qwen3ForSequenceClassification),提取yes和no token的权重差异作为分类器向量。通过修改模型架构并替换分类头,可实现与原始模型相同的评分功能,从

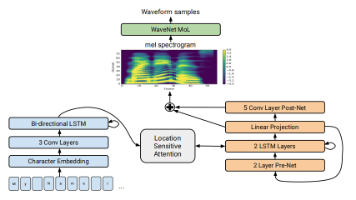
本文概述了语音合成技术的发展历程,从早期拼接式合成和HMM方法,到近年来基于深度学习的模型演进。重点介绍了WaveNet(2016)的因果卷积和膨胀卷积结构、Tacotron(2017)的编码器-解码器架构、FastSpeech(2019)的非自回归并行化设计、VITS(2021)融合VAE/GAN/Flow的混合模型,以及最新的Bark(2023)和SoundStorm(2023)多任务音频生成
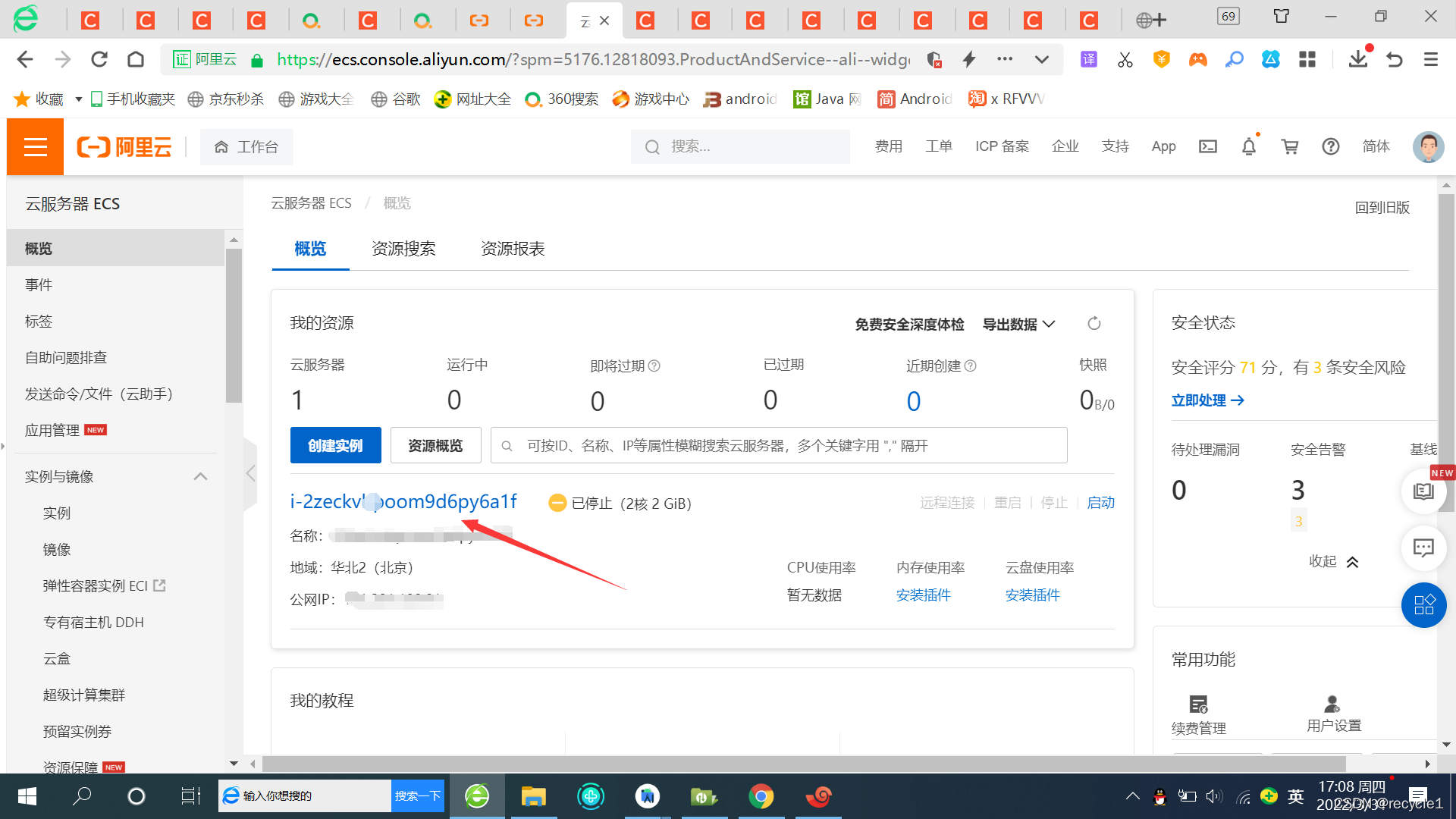
最近申请了一个阿里云服务器,想学习一下云服务器网站的搭建,用宝塔面板的话能很方便的安装各种应用,部署自己的网站。如果在购买服务器的时候已经勾上了宝塔面板的选项,那就可以直接使用,如果没有,就需要更改一下配置打开阿里云服务器的控制台点击实例(如果实例正在运行,要停止运行)点击三个圆点选项点击更换操作系统点击镜像市场,从镜像市场获取更多选择搜索宝塔,选择相应的宝塔面板,点击使用确认订单完成宝塔面板的安
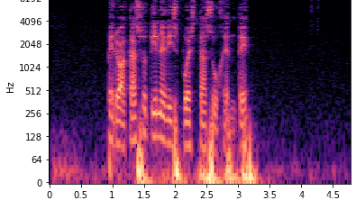
本文介绍了四种音频表示方法:波形图(Waveform)直接显示振幅随时间变化;频谱图(Spectrogram)通过STFT转换到时频域;梅尔谱图(Mel Spectrogram)将频率压缩到接近人耳感知的Mel刻度;梅尔倒谱(MFCC)对梅尔谱图进行DCT变换提取共振峰特征。每种方法各有优劣:波形图信息完整但难以建模,频谱图易建模但维度高,梅尔谱图接近人耳感知但会丢失信息,MFCC计算高效但无法还
VLLM部署Qwen3 重排模型时会出现不支持Score、rerank API错误,原因是vllm 目前没有办法允许单个架构同时支持嵌入和重排,解决方法是将( Qwen3ForCausalLM)模型转换为序列分类架构(Qwen3ForSequenceClassification),提取yes和no token的权重差异作为分类器向量。通过修改模型架构并替换分类头,可实现与原始模型相同的评分功能,从
本文介绍了四种音频表示方法:波形图(Waveform)直接显示振幅随时间变化;频谱图(Spectrogram)通过STFT转换到时频域;梅尔谱图(Mel Spectrogram)将频率压缩到接近人耳感知的Mel刻度;梅尔倒谱(MFCC)对梅尔谱图进行DCT变换提取共振峰特征。每种方法各有优劣:波形图信息完整但难以建模,频谱图易建模但维度高,梅尔谱图接近人耳感知但会丢失信息,MFCC计算高效但无法还
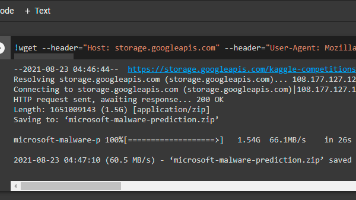
本文介绍使用CurlWget浏览器插件直接在Google Colab中加载数据集的方法,避免传统方式需先下载到本地再上传的低效流程。该插件通过捕获浏览器下载链接,生成wget命令,用户只需在Colab单元格粘贴命令即可快速下载数据。具体步骤包括:安装插件、取消实际下载获取链接、复制wget命令到Colab执行。这种方法显著提升了数据加载效率,尤其适用于处理大型公开数据集.
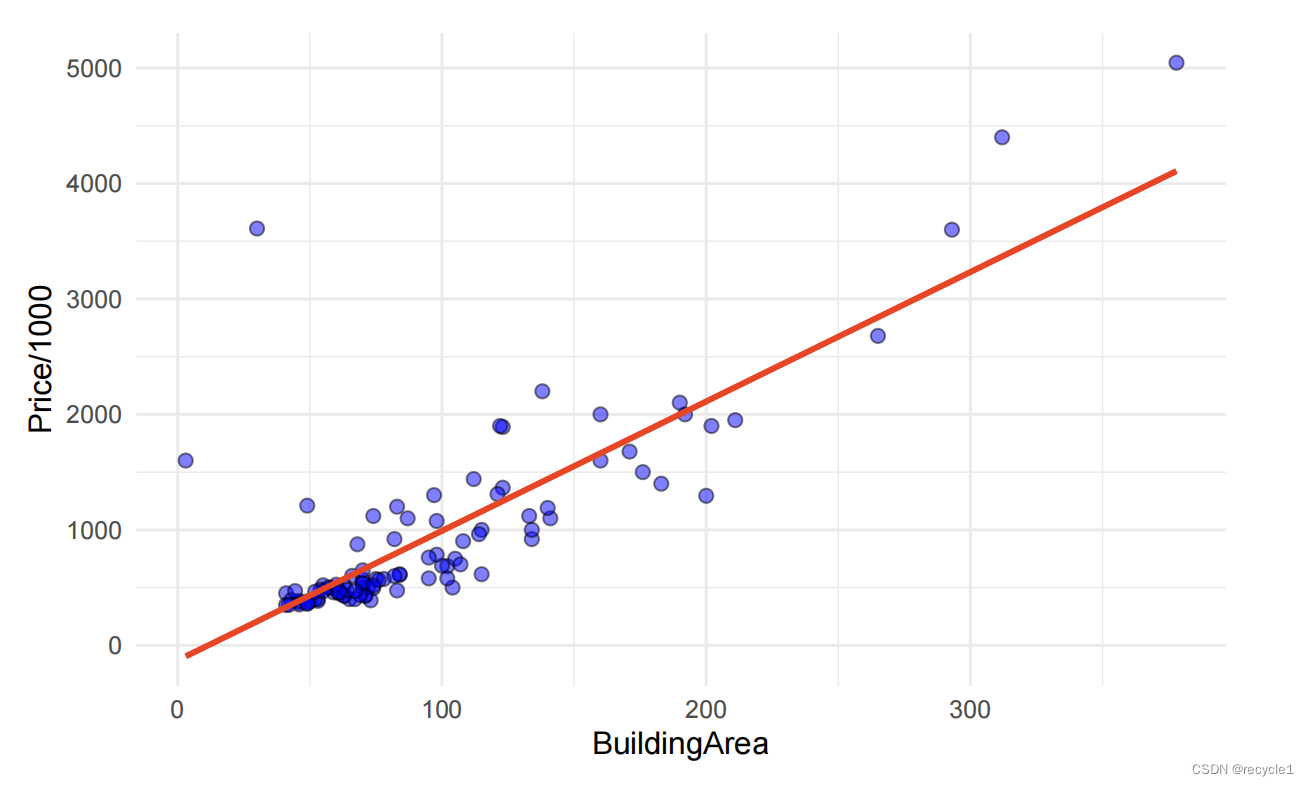
线性回归是一个或多个自变量与因变量之间的关系模型,它通过找到一条直线来拟合数据。逻辑回归是线性回归的拓展,可以解决分类问题。
本文介绍了四种音频表示方法:波形图(Waveform)直接显示振幅随时间变化;频谱图(Spectrogram)通过STFT转换到时频域;梅尔谱图(Mel Spectrogram)将频率压缩到接近人耳感知的Mel刻度;梅尔倒谱(MFCC)对梅尔谱图进行DCT变换提取共振峰特征。每种方法各有优劣:波形图信息完整但难以建模,频谱图易建模但维度高,梅尔谱图接近人耳感知但会丢失信息,MFCC计算高效但无法还