




- @weixin_51702416
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
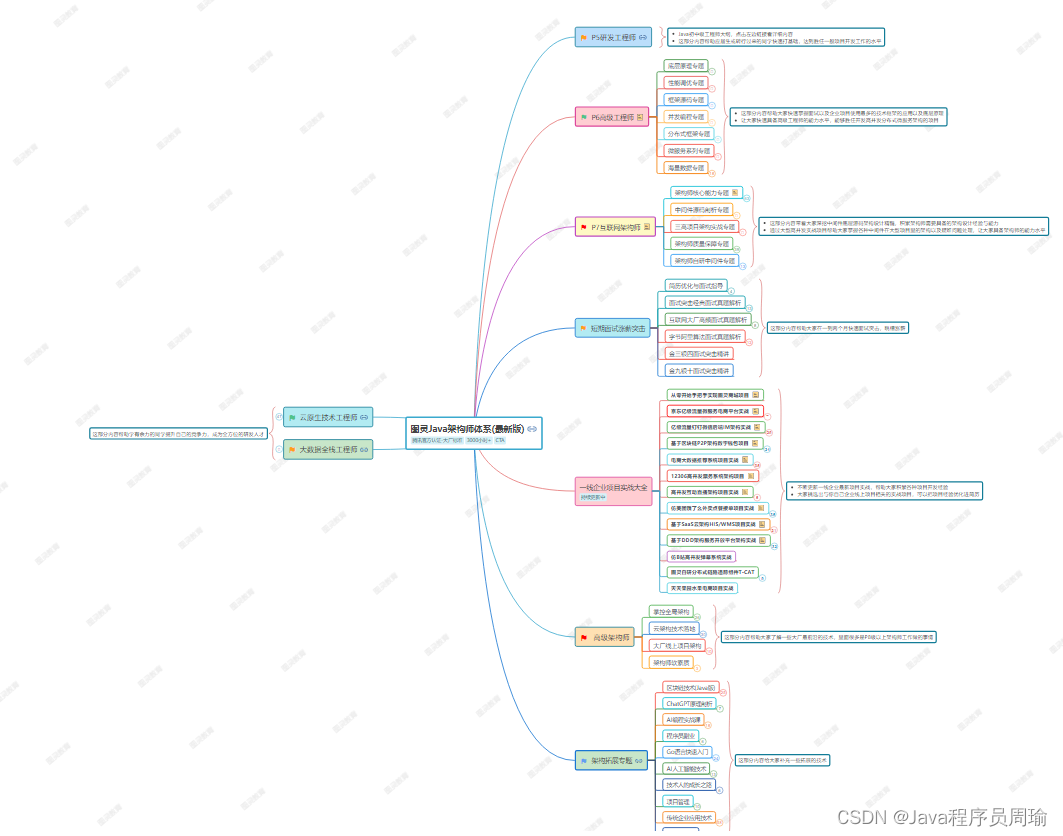
网上虽然教学资料、路线非常多,我们也不否认有些确实有可取之处,但是我们认为一个好的路线,不仅仅只是一条线,应该是点——线——面,三重结合,应该具有系统、规划、全面、细致这四个特性,而这也是网上资源所缺失的,我们本着这个原则,给大家整理了一份2023年系统全面、具有规划的Java学习路线图。我们深知,有很多同学对于培训费用、是否适合、怎么学等等有着各种各样的顾虑,在网上各大平台搜寻着学习方法资料等等
FlowGram 的开源,无疑为开发者社区带来了一份厚礼。它不仅仅是一个可视化流程工具,更是字节跳动在探索 AI 时代应用构建模式的一次重要成果分享。其双布局模式带来的灵活性、AI 辅助功能的智能化、以及底层高性能架构的支撑,让它在标准化流程和自由探索性任务中都能游刃有余。对于想要构建自动化流程、特别是涉及 AI 逻辑的应用,或者对低代码/无代码平台感兴趣的开发者和企业来说,FlowGram 提供

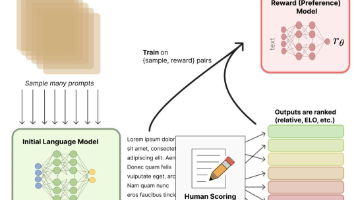
Reinforcement Learning for all Scenarios,二次强化学习阶段,旨在提高模型的有用性和无害性,同时优化其推理能力,对于推理数据,用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。deepseek 方案最重要的步骤是 DeepSeek-R1-Zero,用了一个 cot 的 prompt 模板,然后一堆基于规则的 reward 模型,强化学习用的 GRPO,

本文主要探讨了在预训练模型瓶颈显现的背景下,后训练和推理计算的重要性,并建议从模型服务(serving)入手,因为这是模型应用的第一步。文章比较了SGLang和vLLM两个框架,它们分别来自斯坦福和UC伯克利,功能相似,但各有特色。SGLang提供了丰富的服务功能,如chunkedprefill、speculativedecoding、radixattention和structured
RAG(Retrieval-Augmented Generation)检索增强生成是一种将外部知识检索与大语言模型生成能力结合的混合架构。其核心思想是通过检索外部知识库(如文档、数据库、网页等),弥补大模型静态训练数据的局限性;在生成答案时直接依赖检索到的证据,减少模型凭空编造内容的可能性,降低幻觉风险。RAG无需重新训练模型,仅需更新知识库即可适配不同专业领域(如医疗、法律)。类似将大模型视为一
01大模型微调初步尝试:多位数乘法本文记录了本人在大模型微调任务上的初步尝试,其任务为让大模型学会多位数(实际上是 3 位数及以内)的乘法,并且按照给定的步骤输出过程(Chain of Thought)。LoRA 微调的原理LoRA 的原理网上已经有很多资料给了说明,这里稍作讲解:LoRA = Low Rank Adaption,也就是用一个低秩矩阵去拟合参数。有一些说法认为 LoRA 可以避免模

网上虽然教学资料、路线非常多,我们也不否认有些确实有可取之处,但是我们认为一个好的路线,不仅仅只是一条线,应该是点——线——面,三重结合,应该具有系统、规划、全面、细致这四个特性,而这也是网上资源所缺失的,我们本着这个原则,给大家整理了一份2023年系统全面、具有规划的Java学习路线图。我们深知,有很多同学对于培训费用、是否适合、怎么学等等有着各种各样的顾虑,在网上各大平台搜寻着学习方法资料等等
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模

• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模

网上虽然教学资料、路线非常多,我们也不否认有些确实有可取之处,但是我们认为一个好的路线,不仅仅只是一条线,应该是点——线——面,三重结合,应该具有系统、规划、全面、细致这四个特性,而这也是网上资源所缺失的,我们本着这个原则,给大家整理了一份2023年系统全面、具有规划的Java学习路线图。我们深知,有很多同学对于培训费用、是否适合、怎么学等等有着各种各样的顾虑,在网上各大平台搜寻着学习方法资料等等