




- @weixin_51097521
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
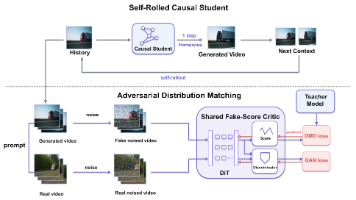
本文深度解析2026年最新视频生成技术One-Forcing,这是一种革命性的一步自回归视频生成方法。传统方法面临三大核心挑战:一致性蒸馏在高噪声区域轨迹曲率集中导致动态信息丢失、纯DMD方法存在自回归误差累积、对抗自蒸馏判别器易坍塌。One-Forcing创新性地提出"零成本寄生式GAN"架构,通过共享fake-score主干和轻量判别头设计,在不增加计算成本的前提下,实现了
本文基于真实生产环境的运行日志和 SGLang 源码深度分析,完整拆解 SGLang 框架针对 Wan2.1 的全套加速技术体系。通过合理配置,我们成功将720P 视频生成时间从 49 分 33 秒压缩到 1 分 13 秒,加速比达到惊人的 40 倍
本文详细解析了NVIDIA TensorRT-LLM对Wan系列视频生成模型的加速实现方案。该系统采用7层分布式架构,通过14项核心技术实现高效推理,包括FP8/NVFP4量化、TRT注意力后端、Ulysses/Attention2D并行、CFG并行、TeaCache/Cache-DiT缓存等。文章深入剖析了各项技术在PipelineLoader加载流程和推理主循环中的具体实现位置,并提供了不同版
本文将从最基础的交叉熵损失(CE)和 L1 损失讲起,逐步深入到 Focal Loss(FL)、Generalized Focal Loss(GFL)及其核心组件 Distribution Focal Loss(DFL),最后结合 YOLOv8 的工业级代码实现,帮你彻底搞懂目标检测损失函数的演进脉络与实际应用。
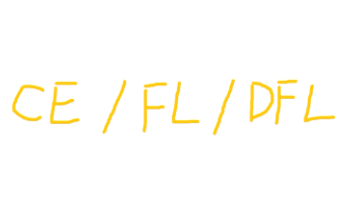
SoulX-LiveAct突破实时数字人生成瓶颈,提出NeighborForcing和ConvKVMemory两大创新技术。通过同扩散步对齐解决了传统AR扩散模型训练不稳定和误差累积问题,采用轻量1D卷积实现KV缓存恒定压缩。仅需双H100 GPU即可实现20FPS小时级实时生成,在唇同步精度、视频质量和硬件成本上全面超越现有方案,将数字人技术推向大规模落地应用阶段。

《FlowMatching深度解析:下一代生成模型的核心原理》摘要 FlowMatching(FM)彻底革新了生成模型范式,解决了DDPM扩散模型的三大痛点:1)通过均匀时间目标消除时间偏好问题;2)直接学习速度向量场避免采样转换误差;3)实现10-40步高效采样。FM核心在于Conditional Flow Matching定理,证明通过训练样本条件向量场可以间接学习边缘向量场,无需复杂积分计算

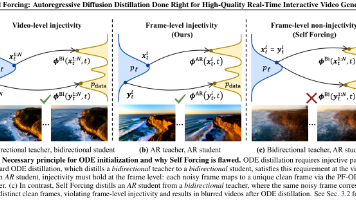
清华大学朱军团队提出CausalForcing技术,突破实时交互式视频生成瓶颈。该技术通过解耦架构转换与速度蒸馏,重构自回归扩散蒸馏流程,在保持17FPS实时推理速度的同时,较此前SOTA方法实现动态度+19.3%、视觉奖励+8.7%、指令遵循+16.7%的提升。CausalForcing从理论根源解决帧级单射性问题,使综合表现超越原始双向模型,为实时视频生成开辟新方向。
PyTorch生态中两大核心加速技术——torch.compile和Triton,通过系统性优化实现了2-10倍的性能提升。torch.compile作为全局优化器,通过计算图捕获、算子融合等技术消除90%的GPU空转等待;Triton则专注于内核级优化,自动管理内存层次结构并最大化TensorCore利用率。两者协同工作时,torch.compile自动处理90%的普通算子,剩余10%的关键算子

摘要: 本文系统梳理了生成式AI从扩散模型到FlowMatching的技术演进。扩散模型(如SD1.5)基于SDE框架,通过概率流ODE实现采样兼容性,传统采样器(DPM-Solver等)通过优化数值方法将步数压缩至10-20步。少步生成技术(LCM、SDXLTurbo)通过修改模型向量场实现1-4步生成,本质是模型蒸馏而非采样器。2024年FlowMatching革命性突破,RectifiedF

摘要: 本文系统梳理了生成式AI从扩散模型到FlowMatching的技术演进。扩散模型(如SD1.5)基于SDE框架,通过概率流ODE实现采样兼容性,传统采样器(DPM-Solver等)通过优化数值方法将步数压缩至10-20步。少步生成技术(LCM、SDXLTurbo)通过修改模型向量场实现1-4步生成,本质是模型蒸馏而非采样器。2024年FlowMatching革命性突破,RectifiedF