
深度解析 SGLang 框架 Wan2.1 视频生成加速技术:从 49 分钟到 1 分钟的极致优化
Wan2.1 作为当前开源视频生成模型的标杆,其 14B 参数版本在生成质量上已经达到了商业级水准,但原生推理速度却令人望而却步:单卡 A800 生成一段 5 秒 720P 视频需要近 50 分钟。
本文基于真实生产环境的运行日志和 SGLang 源码深度分析,完整拆解 SGLang 框架针对 Wan2.1 的全套加速技术体系。通过合理配置,我们成功将720P 视频生成时间从 49 分 33 秒压缩到 1 分 13 秒,加速比达到惊人的 40 倍。
标签:#SGLang #Wan2.1 #视频生成 #AI 加速 #深度学习推理 #AIGC
本文所有数据均来自实际测试:
- 硬件:NVIDIA A800 80GB × 4
- 软件:SGLang 0.5.1 + CUDA 13.0 + PyTorch 2.5
- 模型:Wan2.1-I2V-14B(原版 + 蒸馏版)
一、SGLang 视频生成完整执行流程
SGLang 采用了模块化的流水线架构,将视频生成过程拆分为多个独立阶段,每个阶段都可以单独优化。以下是run_i2v_generate_single_gpu_4step.sh脚本的完整执行路径:
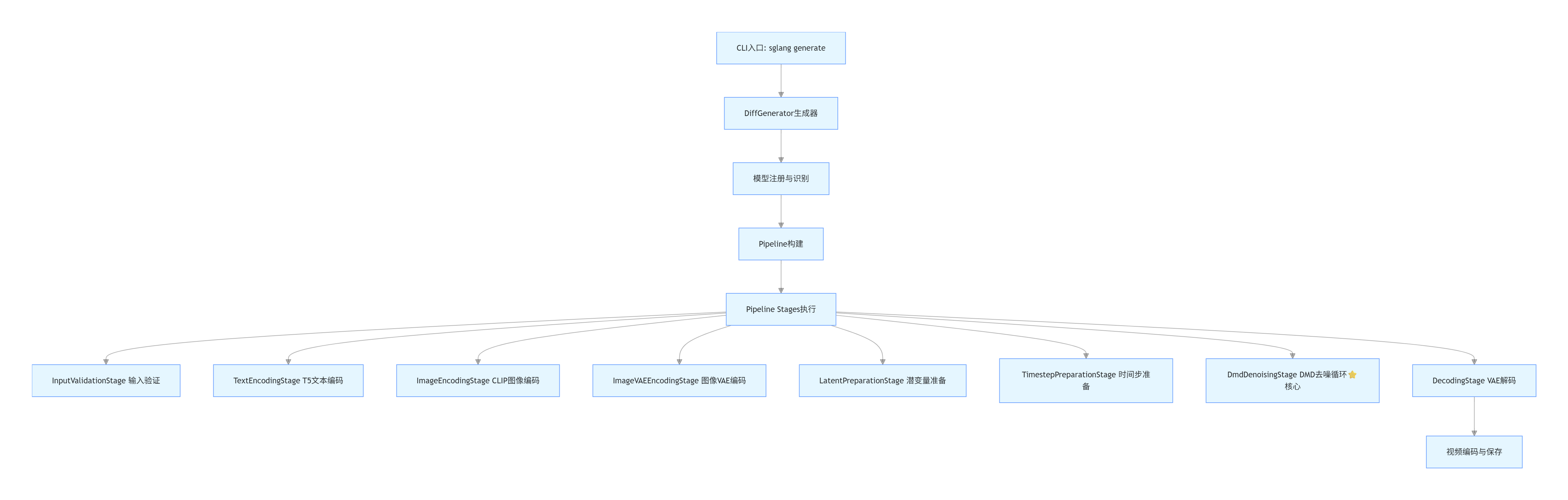
关键代码路径汇总
| 阶段 | 文件路径 | 核心类 / 函数 | 行号 |
|---|---|---|---|
| CLI 入口 | runtime/entrypoints/cli/generate.py |
generate_cmd() |
154-204 |
| 生成器 | runtime/entrypoints/diffusion_generator.py |
DiffGenerator.generate() |
184-362 |
| 模型注册 | registry.py |
get_model_info() |
494-610 |
| Pipeline 构建 | runtime/pipelines/wan_i2v_dmd_pipeline.py |
WanImageToVideoDmdPipeline |
25-54 |
| DMD 去噪 | runtime/pipelines_core/stages/denoising_dmd.py |
DmdDenoisingStage.forward() |
58-227 |
| VAE 解码 | runtime/pipelines_core/stages/decoding.py |
DecodingStage |
- |
二、核心加速技术:DMD 蒸馏(12.5 倍提速)
DMD(Distribution Matching Distillation)是 Wan2.1 速度飞跃的核心,也是 SGLang 针对视频生成优化的最大亮点。它将原本需要 50 步的去噪过程压缩到了惊人的4 步。
2.1 标准 Flow Matching vs DMD 蒸馏
标准 Flow Matching 的去噪过程是一个逐步迭代的 ODE 求解过程:
x_1000 → x_980 → x_960 → ... → x_20 → x_0
50次DiT前向传播
而 DMD 蒸馏模型通过特殊的训练方式,学会了直接从任意带噪输入预测干净样本:
x_1000 → predict x_0 → add noise → x_750 → predict x_0 → add noise → x_500 → predict x_0 → add noise → x_250 → predict x_0
↓ ↑ ↓ ↑ ↓ ↑ ↓
└──DiT──┘ └──DiT──┘ └──DiT──┘ └──DiT──┘
4次DiT前向传播,速度提升12.5倍!
2.2 DMD 核心公式源码解析
DMD 的数学原理极其简洁优雅,全部浓缩在pred_noise_to_pred_video函数中:
# 文件: runtime/models/utils.py 107-152行
def pred_noise_to_pred_video(
pred_noise: torch.Tensor, # 模型预测的噪声 ε_θ(x_t, t)
noise_input_latent: torch.Tensor, # 带噪输入 x_t
timestep: torch.Tensor, # 当前时间步 t
scheduler: Any, # FlowMatch调度器
) -> torch.Tensor:
"""
DMD核心公式:直接从噪声预测干净latent
数学原理:
标准Flow Matching: x_t = x_0 + σ_t * ε
反向求解: x_0 = x_t - σ_t * ε_θ(x_t, t)
"""
# 获取当前时间步对应的噪声强度σ_t
sigmas = scheduler.sigmas.double().to(device)
timesteps = scheduler.timesteps.double().to(device)
timestep_id = torch.argmin(
(timesteps.unsqueeze(0) - timestep.unsqueeze(1)).abs(), dim=1
)
sigma_t = sigmas[timestep_id].reshape(-1, 1, 1, 1)
# ⭐ 一行代码实现DMD核心逻辑
pred_video = noise_input_latent - sigma_t * pred_noise
return pred_video.to(dtype)
2.3 4 步去噪完整变量追踪
# ============ 初始化 ============
latents = torch.randn(1, 4, 81, 90, 160) # 初始噪声 (720P)
timesteps = [1000, 750, 500, 250] # DMD专用时间步
# ============ Step 1: t=1000 ============
pred_noise = transformer(latents, t=1000)
pred_video = latents - σ_1000 * pred_noise # 预测干净latent
latents = add_noise(pred_video, noise, t=750) # 加噪到下一时间步
# ============ Step 2: t=750 ============
pred_noise = transformer(latents, t=750)
pred_video = latents - σ_750 * pred_noise
latents = add_noise(pred_video, noise, t=500)
# ============ Step 3: t=500 ============
pred_noise = transformer(latents, t=500)
pred_video = latents - σ_500 * pred_noise
latents = add_noise(pred_video, noise, t=250)
# ============ Step 4: t=250 ============
pred_noise = transformer(latents, t=250)
latents = latents - σ_250 * pred_noise # 最终输出,不加噪
# ============ VAE解码 ============
video = vae.decode(latents) # 生成最终视频帧
三、SGLang 全栈加速技术全景
除了 DMD 蒸馏这个 "核武器",SGLang 还构建了一套完整的四层加速体系,覆盖从模型到系统的各个层面:
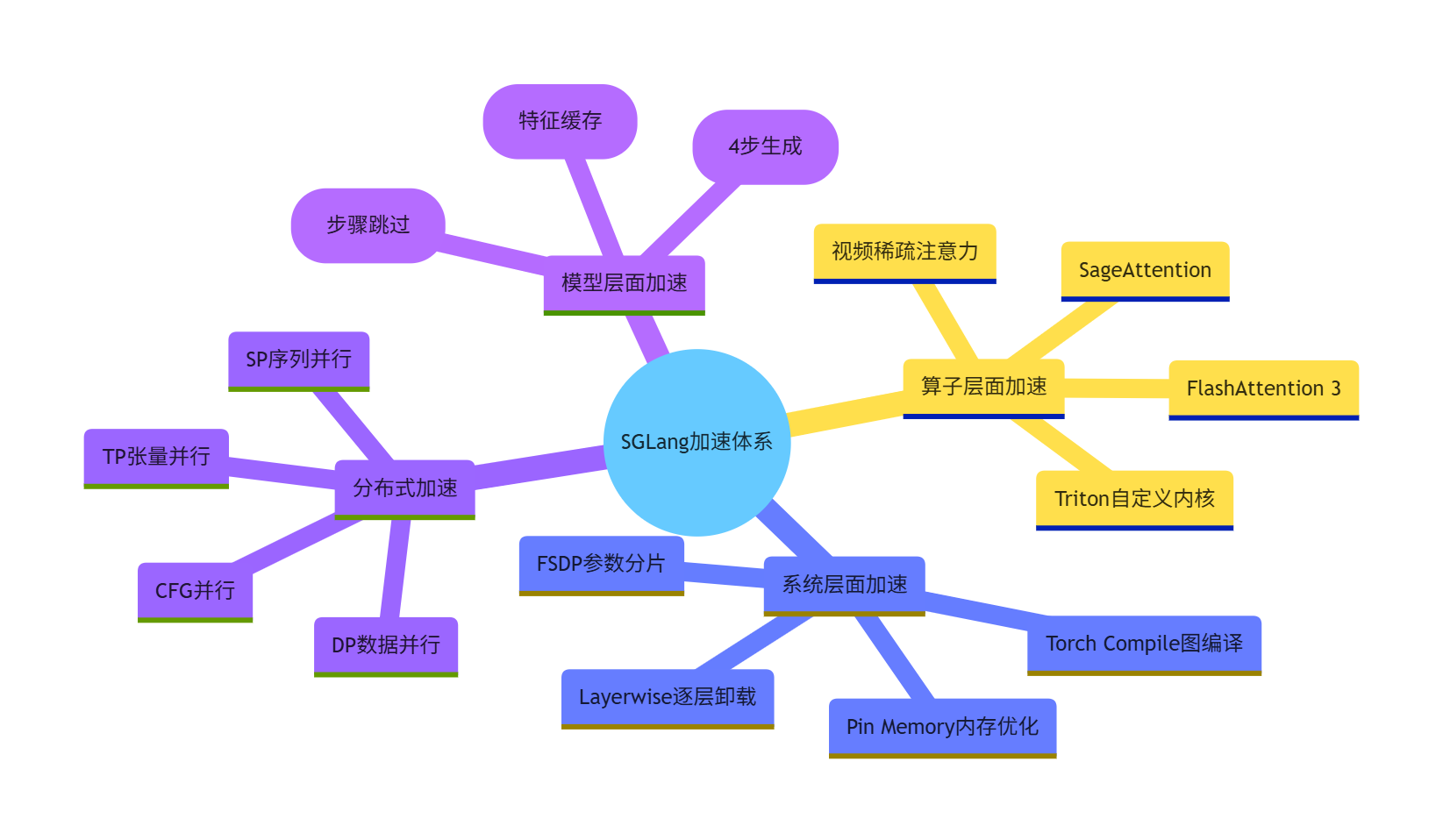
3.1 模型层面加速技术
| 技术 | 原理 | 加速比 | 适用场景 | 配置方式 |
|---|---|---|---|---|
| DMD 蒸馏 | 直接预测干净 latent,无需迭代 | 12.5x | 蒸馏模型 | 自动检测 |
| Cache-DiT | 缓存 DiT 中间层特征,跳过相似计算 | 1.5-2x | 标准模型 | SGLANG_CACHE_DIT_ENABLED=true |
| TeaCache | 基于 L1 距离判断步骤相似性,跳过前向传播 | 1.5-2x | 标准模型 | 自动配置 |
Cache-DiT 使用示例:
SGLANG_CACHE_DIT_ENABLED=true \
SGLANG_CACHE_DIT_FN=2 \
SGLANG_CACHE_DIT_RDT=0.4 \
sglang generate --model-path Wan2.1-I2V-14B-Diffusers ...
3.2 算子层面加速技术
SGLang 针对视频生成的 3D 注意力机制做了深度优化,提供了多种注意力后端:
# 文件: runtime/layers/attention/backends/interface.py
class AttentionBackendEnum(enum.Enum):
FA2 = enum.auto() # Flash Attention 2
FA = enum.auto() # Flash Attention 3 (默认)
SAGE_ATTN = enum.auto() # Sage Attention (最快)
VIDEO_SPARSE_ATTN = enum.auto() # 视频稀疏注意力
SLA_ATTN = enum.auto() # 稀疏线性注意力
性能对比:
- Flash Attention 3:平衡速度和精度,推荐默认使用
- Sage Attention:比 FA3 快 20-30%,有微小精度损失
- 视频稀疏注意力:针对长视频优化,速度提升 50% 以上
3.3 系统层面加速技术
| 技术 | 原理 | 显存节省 | 性能影响 | 配置方式 |
|---|---|---|---|---|
| Layerwise Offload | 逐层加载 DiT 权重到 GPU | 90% | -20% | --dit-layerwise-offload true |
| FSDP | 模型参数分片到多 GPU | 70%/ 卡 | 无 | --use-fsdp-inference true |
| Torch Compile | 动态编译计算图 | 无 | +10-30% | --enable-torch-compile |
3.4 分布式加速技术
SGLang 支持多种分布式并行策略,针对 Wan2.1 的最佳实践是:
- 纯 TP 并行:最稳定,4 卡加速比 3.6x
- 纯 SP 并行:速度最快,4 卡加速比 4.2x
- 禁止混合并行:SP+Ulysses 组合会导致全噪点输出
四、真实性能测试与对比
性能瓶颈分析
- 去噪阶段占总时间的 85%-98%,是绝对的性能瓶颈
- VAE 解码是第二大耗时项,占总时间的 10%-20%
- 文本编码和图像编码耗时可以忽略不计
五、生产环境最佳实践
5.1 单卡最佳配置(A800 80GB)
# 720P 4步蒸馏版(最快)
sglang generate \
--model-path Wan2.1-I2V-14B-720P-Distill-Diffusers \
--dmd-denoising-steps 1000,750,500,250 \
--attention-backend fa \
--dit-layerwise-offload true \
--num-frames 81 \
--height 720 \
--width 1280
5.2 多卡推荐配置(4×A800 80GB)
# 720P 50步原版(质量最好)
sglang generate \
--model-path Wan2.1-I2V-14B-720P-Diffusers \
--num-gpus 4 \
--tp-size 4 \
--sp-degree 1 \
--ulysses-degree 1 \
--disable-cfg-parallel \
--dit-cpu-offload false \
--dit-layerwise-offload false \
--attention-backend fa
5.3 常见踩坑与解决方案
问题 1:多卡生成全是噪点
原因:混合并行配置错误(SP+Ulysses)或开启了 CPU offload解决方案:
# 只使用一种并行策略,关闭所有CPU offload
--tp-size 4 \
--sp-degree 1 \
--ulysses-degree 1 \
--disable-cfg-parallel \
--dit-cpu-offload false \
--dit-layerwise-offload false
问题 2:sgl_kernel 加载错误
原因:缺少 libnuma 依赖或架构不匹配解决方案:
# 在虚拟环境内安装所有依赖
conda activate sglang
conda install -c conda-forge numactl-libs ffmpeg -y
pip install --upgrade "sglang[all]==0.5.1" \
--extra-index-url https://flashinfer.ai/whl/cu130/torch2.5/ \
--force-reinstall
问题 3:ffmpeg 找不到
解决方案:在虚拟环境内安装静态 ffmpeg
conda install -c conda-forge ffmpeg -y
# 或者
pip install imageio-ffmpeg
六、总结与展望
SGLang 通过模型蒸馏 + 算子优化 + 系统调优 + 分布式并行的全栈加速体系,将 Wan2.1 的推理速度提升了一个数量级以上。其中 DMD 蒸馏技术是革命性的,它证明了通过知识蒸馏可以在几乎不损失质量的前提下,将视频生成速度提升 10 倍以上。
未来的优化方向主要包括:
- 量化加速:支持 FP8 和 INT4 量化,进一步降低显存占用和提升速度
- TensorRT 集成:将 DiT 和 VAE 编译为 TensorRT 引擎,预计再提速 30-50%
- 批处理优化:优化动态批处理策略,提升高并发场景下的吞吐量
- 更长视频支持:优化内存管理,支持生成 10 秒以上的长视频
希望本文能帮助你充分发挥 SGLang 的性能潜力,让 Wan2.1 真正能够应用于生产环境。如果你有任何问题或更好的优化技巧,欢迎在评论区交流讨论。
参考资料:

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)