




- @weixin_46788581
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
点击下方卡片,关注「计算机视觉工坊」公众号选择星标,干货第一时间送达作者:Jian Liu |编辑:计算机视觉工坊添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门.
综上所述,DrivingWorld通过利用GPT风格框架,生成了更长、更高保真度且具有更好泛化能力的视频预测,从而解决了自动驾驶中先前视频生成模型的局限性。与在传统方法中难以处理长序列连贯性或严重依赖标记数据的情况不同,DrivingWorld能够生成逼真的、结构化的视频序列,同时实现精确的动作控制。与经典的GPT结构相比,我们提出的时空GPT结构采用了下一个状态预测策略来建模连续帧之间的时间连贯

多模态大语言模型的兴起刺激了其在自动驾驶中的应用。最近基于MLLM的方法通过学习从感知到动作的直接映射来执行动作,忽略了世界的动态以及动作和世界动态之间的关系。相比之下,人类拥有世界模型,使他们能够基于3D内部视觉表示来模拟未来状态,并相应地计划行动。为此,我们提出OccLLaMA,一个占据-语言-动作生成世界模型,它使用语义占据作为一般的视觉表示,并通过自回归模型统一视觉-语言-动作(VLA)模
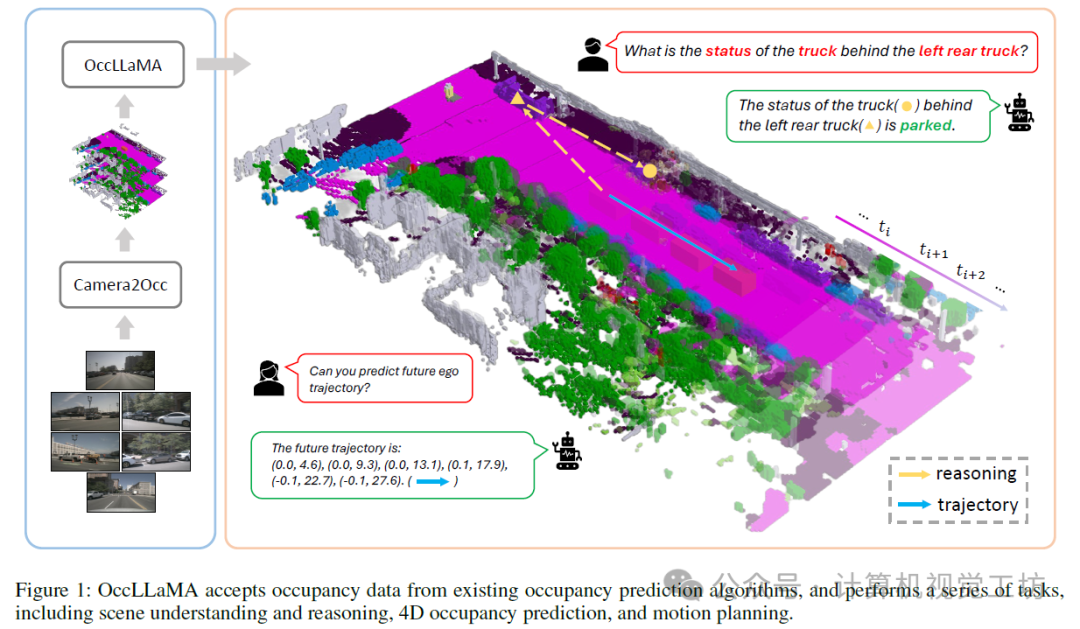
点击下方卡片,关注「3D视觉工坊」公众号选择星标,干货第一时间送达来源:计算机视觉工坊添加小助理:cv3d008,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。扫描下方二维码,加入「3D视觉从入门到精通」知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研
点击下方卡片,关注「3D视觉工坊」公众号选择星标,干货第一时间送达来源:计算机视觉工坊添加小助理:cv3d008,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。扫描下方二维码,加入「3D视觉从入门到精通」知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研

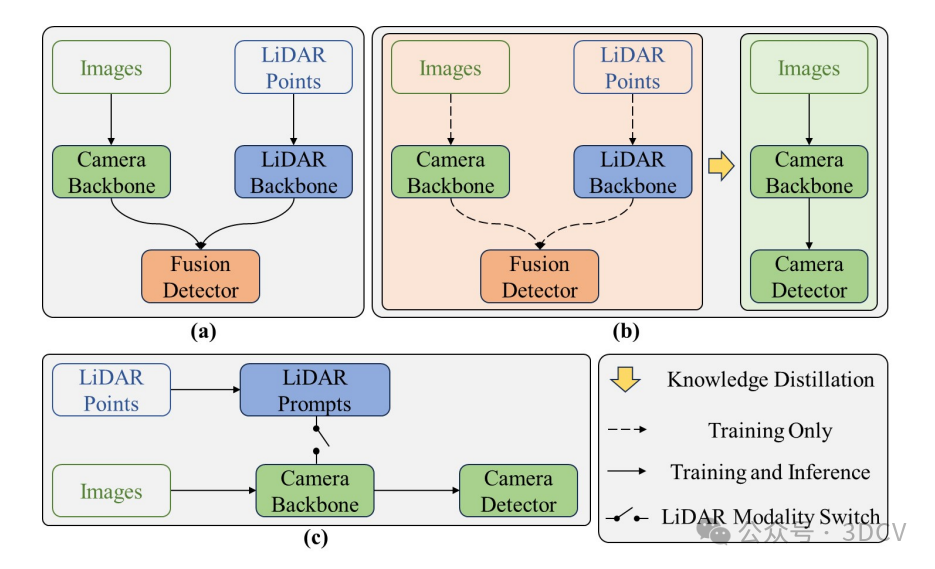
在这篇论文中,我们提出了一种轻量级的3D物体检测框架,名为PromptDet,它由一个相机检测器和激光雷达辅助的Prompter组成。PromptDet通过AHA进行激光雷达和相机的融合,如果同时有图像和激光雷达点,它是一个轻量级的多模态检测器。由于CMKl,PromptDet仍然优于仅以图像为输入的基线。AHA和CMKI构成了即插即用的激光雷达辅助Prompter,整个框架的训练非常简单只需少量

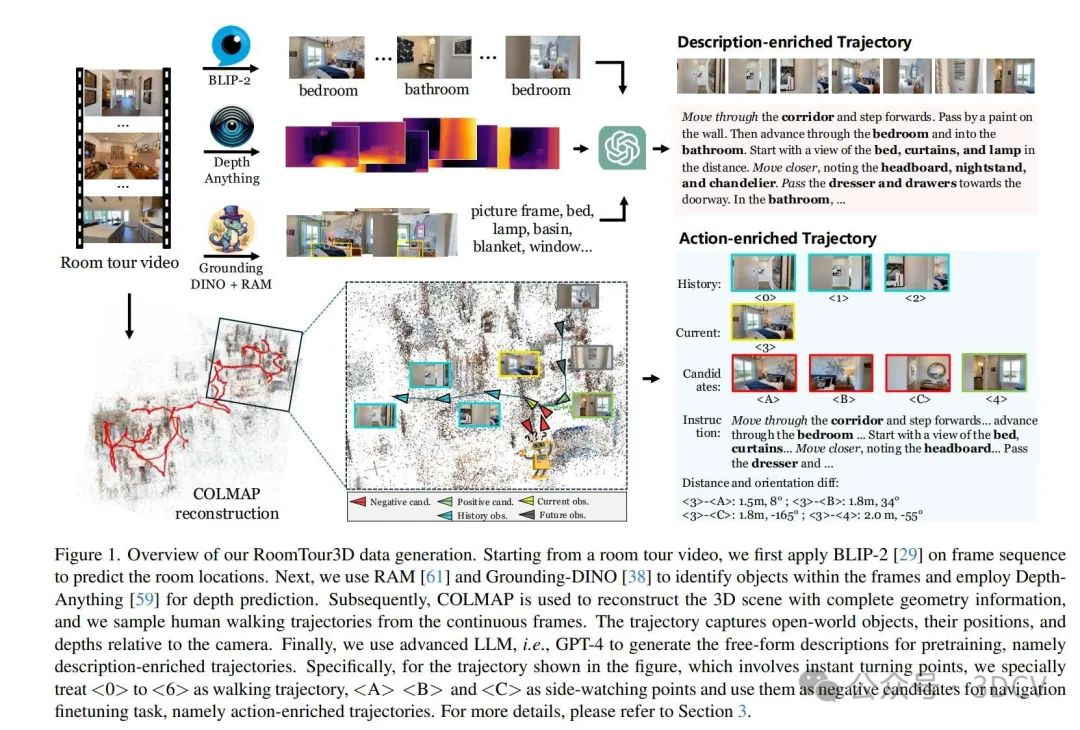
在本文中,我们提出了RoomTour3D,这是一个从房间参观视频自动整理得到的新型数据集,用于视觉语言导航(VLN)任务。通过利用视频数据的丰富性和顺序性,并结合物体多样性和空间感知,我们从1847个房间参观场景中生成了20万条导航指令和1.7万条动作丰富的轨迹。此外,我们还从视频帧和重建的3D场景中生成了可导航轨迹,这显著提升了性能,并在SOON和REVERIE基准上创造了新的最先进结果。这种方
3DGS技术是近年来计算机视觉领域最具突破性的研究成果之一。它不仅在学术界引起了广泛关注,成为计算机视觉、SLAM等领域的研究热点,而且每天都有大量基于Gaussian Splatting的新研究问世。此外,3DGS技术在商业应用方面也取得了显著进展,许多商业公司正在积极推动3DGS技术的商业化落地。随着3DGS技术的商业化进程加速,与之相关的计算机视觉岗位也如雨后春笋般涌现。
