- @weixin_45662399
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
数据驱动方法使用具有不同类别和标签的数据集,然后使用机器学习去训练一个分类器,使用该分类器去识别新的图片。训练数据集会会给定类别和对应的类别标签,分类器要识别的类从可以选的标签中进行选择第一个分类器:最近邻分类器(Nearest Neighbor)def train(images,labels):#一系列机器学习算法return modeldef predict(model,test_images
参考 : MMDetection全流程实战指南:手把手带你构建目标检测模型2. 安装GPU版本的PyTorch这里如果安装失败了需要去官网 pytorch官网 找对应的版本下载;先输入nvidia-smi命令查看可下载的cuda的最高版本我的可下载的最高CUDA版本为12.0,因此我选择11.8的这个下载命令进行下载下载后进行检验是否安装成功可以看到输出为true,安装成功。使用 OpenMMLa

现在多使用小批量随机梯度下降算法来进行梯度的更新。

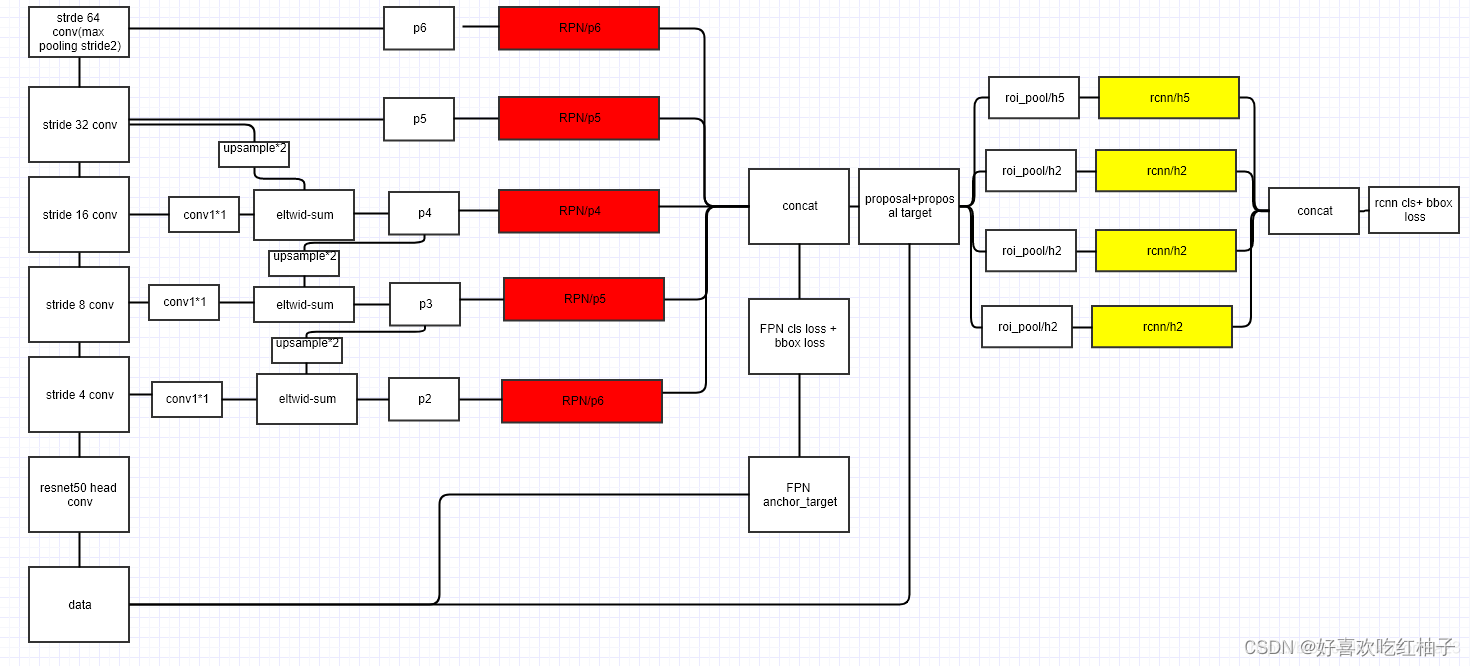
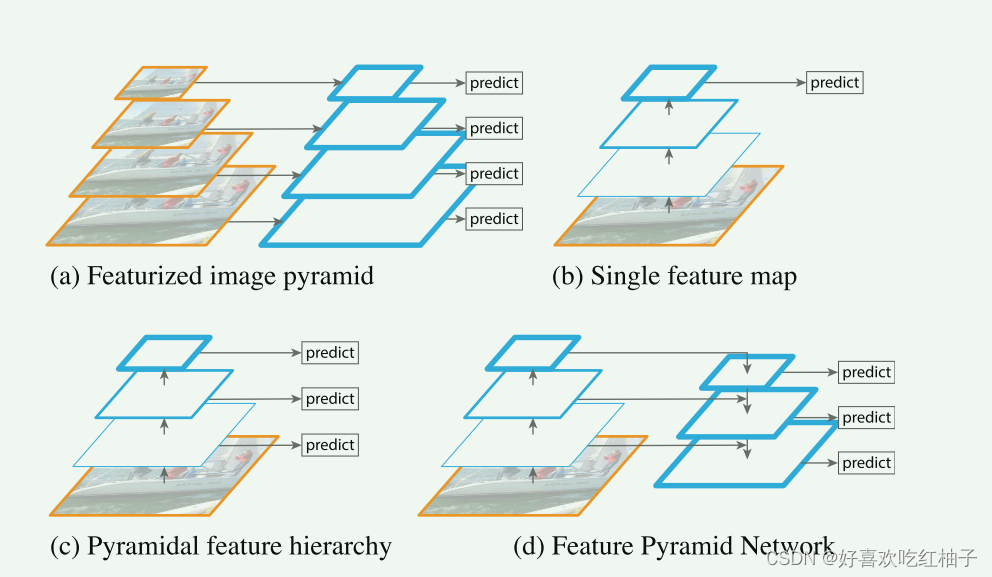
特征金字塔介绍
概念:数据有输入变量x和输出变量y,找到输入变量和输出变量的关系 Y=F(X)不一定是函数,只代表输入到输出的一种关系机器学习分类:监督学习、无监督学习、强化学习监督学习分类:分类问题和回归问题分类:输出变量为有限个离散值(判断好坏/判断种类)回归:输出变量为连续性变量(预测房价/预测产量)MATLAB中(分类学习器和回归学习器)无监督学习:数据全部作为输入变量,没有输出变量,希望得到数据中蕴含的
彩色图像中的每个像素颜色由R、G、B三个分量来决定,而每个分量的取值范围都在0-255之间,这样对计算机来说,彩色图像的一个像素点就会有256*256*256=16777216种颜色的变化范围!在下图的路径中,我们可以看到需要xml文件,这些都是OpenCV中自带的分类器,根据文件名我们可以看到有识别眼睛的,身体的,脸的,等等。彩色图片的信息含量过大,而进行图片识别时,其实只需要使用灰度图像里的信

教你如何缝合代码模块
在配深度学习环境每次想要训练模型都出现nvrtc: error: invalid value for --gpu-architecture (-arch)这个问题,换了无数个方法都没解决,一开始下载的torch和cuda版本是1.12.0+11.3,后来查了GitHub发现4090框架不支持还是怎么着,最后把torch版本卸掉重新下了1.13+11.6的版本,终于跑通了呜呜太感人了!
分层结构的设计使得神经网络具有灵活性和可扩展性,可以根据不同的任务和数据集进行调整和修改。通常,骨干网络是由预训练模型提供的,而颈部网络和头部网络则可以根据具体的任务进行调整和定制。