




- @weixin_45131680
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
点击开始节点,再点击加号可选择后续节点,本章后续添加节点也是如此操作,后续不再赘述。注意复制提示词后需点击{x}选择文档提取器的输出,否则读取不了上下文。选中文档提取器,在右侧配置的输入变量中填写开始节点命名的变量名。点击右上角预览按钮,上传文件并输入请将文件内容生成思维脑图。在右侧回复框中点击{x}选择http节点的body输出。在开始节点点击右上角的+号,开始配置输入信息。大模型不能直接处理文
默子的960M是肯定不支持BF16的,目前支持BF16的显卡有很多,比较大众化的应该就是NVIDIA。具体是如何加速的,以及具体会加速多少,这个涉及到CUDA和Tensor核心的底层原理与深度学习相关知识。啦,哈哈哈(友情提示:如果电脑是多GPU的,上述代码只能列出第一个GPU设备的部分信息,并不能列出全部GPU的信息。在官方给出的文档中,如果进行神经网络的训练,建议GPU此数值在 5.0 以上(

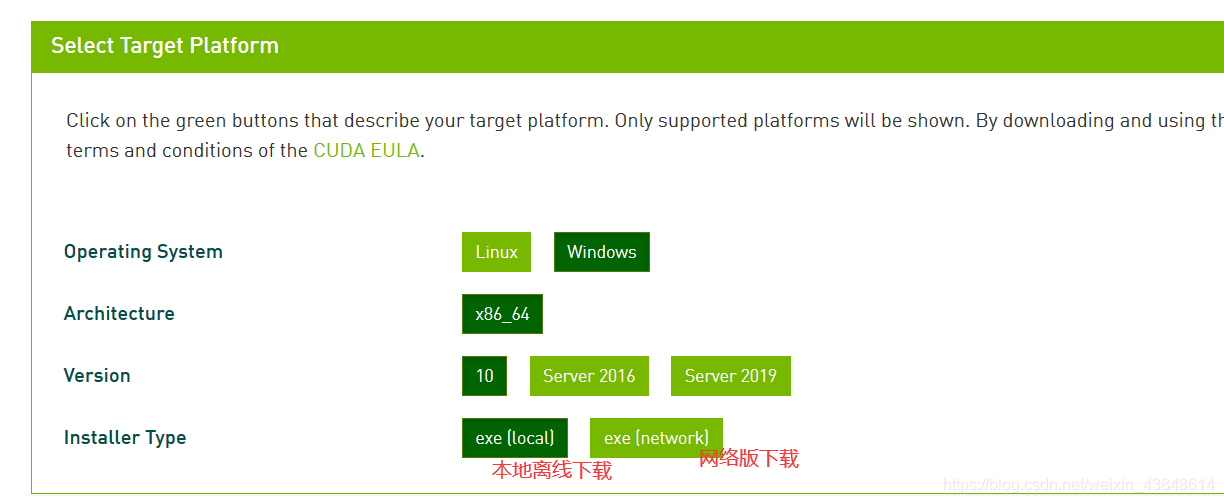
windows10 版本安装CUDA,首先需要下载两个安装包CUDA toolkit(toolkit就是指工具包)cuDNN注:cuDNN 是用于配置深度学习使用官方教程。
持续集成是一个开发的实践,需要开发人员定期集成代码到共享存储库。这个概念是为了消除发现的问题,后来出现在构建生命周期的问题。持续集成要求开发人员有频繁的构建。最常见的做法是,每当一个代码提交时,构建应该被触发。互联网软件的开发和发布,已经形成了一套标准流程,假如把开发工作流程分为以下几个阶段:编码 --> 构建 --> 集成 --> 测试 --> 交付 --> 部署正如你在上图中看到,[持续集成(

导师配了一个台式机,便着手配置PyTorch环境。根据台式机的显卡驱动(472.12)、CUDA、cuDNN版本安装好PyTorch之后,调用torch.cuda.is_available()函数,可以发现PyTorch-GPU版本已经安装成功。但是安装的PyTorch却无法调用GPU进行运算。

市民赵铁柱在A公司担任开发工程师,某日赵铁柱负责维护的一个网站无法访问,经排查,是docker的mysql容器挂了,这个简单,赵铁柱不慌不忙,倒了杯咖啡,然后不急不缓地启动了mysql容器。看到mysql容器启动成功了,然后自己访问网站测试了下,数据全没了。启动dream_mysql57_3307容器,对外映射端口是3307。先查看下已经在运行的容器,把mysql57容器停止服务。经排查发现,赵铁

git push。

IOPS是指单位时间内系统能处理的I/O请求数量,一般以每秒处理的I/O请求数量为单位,I/O请求通常为读或写数据操作请求。对于应用系统,需要首先确定数据的负载特征,然后选择合理的IOPS指标进行测量和对比分析,据此选择合适的存储介质和软件系统。影响磁盘的关键因素是磁盘服务时间,即磁盘完成一个I/O请求所花费的时间,它由寻道时间、旋转延迟和数据传输时间三部分构成。每秒查询率QPS是对一个特定的查询

云原生大数据组件研究(Hive+Hadoop)前言网上的找的文档大多残缺不靠谱,所以我整理了一份安装最新版本的hive4…0.0+hadoop3.3.4的学习环境,可以提供大家安装一个完整的hive+hadoop的环境供学习。由于在公司担任大数据的培训工作后续还会更新一些基础的文章,希望能帮助到大家。**一、**安装Hadoop3.3.4前置:集群规划机器信息Hostnamek8s-masterk

4. 在测试类中执行创建。文件夹,上传,下载文件。
