




- @weixin_44852067
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1.TensorFlow简介1.1 定义 TensorFlow 是一个端到端开源机器学习平台, 它允许将深度神经网络的计算部署到任意数量的 CPU 或 GPU 的服务器、PC 或移动设备上,且只利用一个 TensorFlow API。TensorFlow最初由谷歌大脑团队开发,用于Google的研究和生产,于2015年11月9日在Apache 2.0开源许可证下发布。1.2 特性支持所有流行语言
1.基本介绍1.1 Nvidia GPU, Tensorflow与Python的关系1.Python为最上层的结构,透过Tensorflow的框架(或是想成函式库)进行深度学习;2.Tensorflow透过CUDA Toolkit来连接GPU,让GPU的众多核心能够接受指令实际地执行运算;3.cuDNN则是Nvidia针对深度神经网路提供的加速器。3.2 GPU的配备需求Tensorflow-gp
指数族分布 (The exponential family distribution),区别于指数分布(exponential distribution)。指数分布族不是专指一种分布,而是一系列符合特征的分布的统称。在概率统计中,若某概率分布满足下式,我们就称之属于指数族分布。py;py;θbyexpηθTy−Aθ其中,η\etaη是分布的自然参数(nature parameter);TyT(y)

1.TensorFlow简介1.1 定义 TensorFlow 是一个端到端开源机器学习平台, 它允许将深度神经网络的计算部署到任意数量的 CPU 或 GPU 的服务器、PC 或移动设备上,且只利用一个 TensorFlow API。TensorFlow最初由谷歌大脑团队开发,用于Google的研究和生产,于2015年11月9日在Apache 2.0开源许可证下发布。1.2 特性支持所有流行语言
python实现十大排序算法
1.官网语法pandas.read_csv(filepath_or_buffer, sep=NoDefault.no_default**,** delimiter=None**,** header='infer’, names=NoDefault.no_default**,** index_col=None**,** usecols=None**,** squeeze=False**,** pre
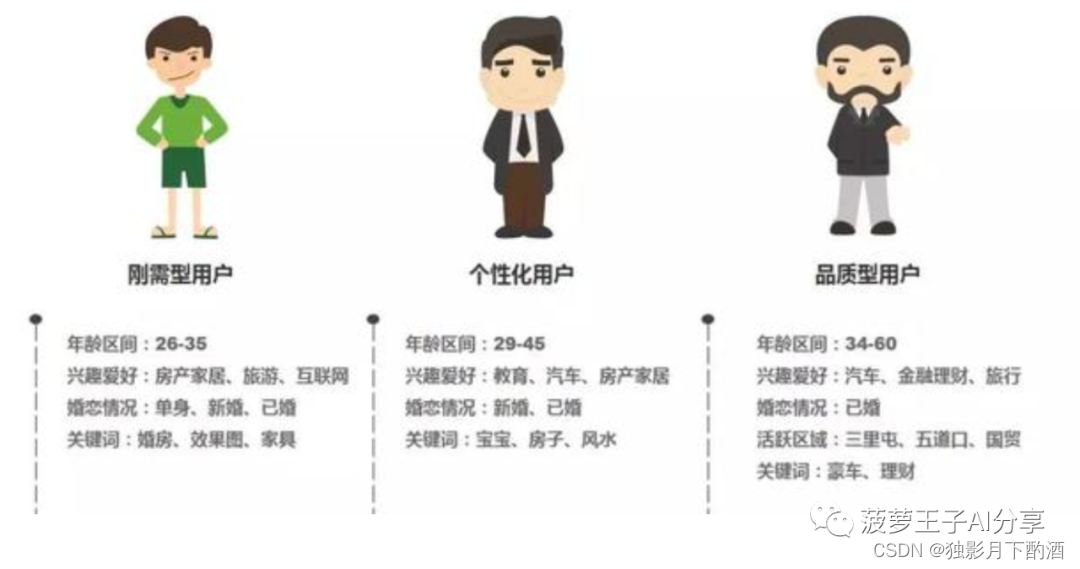
推荐系统的用户画像主要有两种:基本画像和偏好画像。基本画像是用户的个人属性,如年龄,性别,居住城市等。用户偏好画像是推荐系统中的重点,它一般用用户偏好程度 = 行为类型权重值 × 次数 × 时间衰减 × TFIDF值计算出来。用户画像在推荐系统中用于召回和模型训练。参考:https://www.woshipm.com/user-research/3780886.html。
1.需求情景:安装完Anaconda利用conda创建了虚拟环境,但是启动jupyter notebook之后却找不到虚拟环境。原因:由于在虚拟环境下缺少kernel.json文件2.解决方案2.1 安装ipykernelconda install ipykernel2.2 激活conda环境source activate 环境名称2.3 将环境写入notebook的kernel中# python
loc函数:通过行索引 “Index” 中的具体值来取行数据(如取"Index"为"A"的行)iloc函数:通过行号来取行数据(如取第二行的数据)注:loc是location的意思,iloc中的i是integer的意思,仅接受整数作为参数。行根据行标签,也就是索引筛选,列根据列标签,列名筛选如果选取的是所有行或者所有列,可以用:代替行标签选取的时候,两端都包含,比如[0:5]指的是0,1,2,3,
1.简介Pandas DataFrame是带有标签轴(行和列)的二维大小可变的,可能是异构的表格数据结构。算术运算在行和列标签上对齐。可以将其视为Series对象的dict-like容器。它也是Pandas的主要数据结构。2.语法结构作用:Pandas DataFrame.columns属性返回给定Dataframe的列标签。DataFrame.columnsparam:Nonereturn:T