- @weixin_44603934
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本项目开发了一个基于NSGA-II算法和神经网络代理模型的波纹壳结构多目标优化系统,可同时优化临界载荷、结构质量、载重比和效率指数四个相互冲突的目标。系统采用模块化设计,包含数学模型、优化算法、深度学习代理模型和可视化分析四大核心模块,通过神经网络代理模型将评估速度提升100倍以上。该系统适用于航空航天、压力容器等领域的结构优化设计,提供完整的帕累托前沿解集和专业可视化分析报告,具有工程实用性强、
13.如果长时间都一直是该情况,可以使用Ctrl + Shift + P,打开命令窗口,输入reload window来重新加载窗口(会要求你重新手动输入密码)8. 使用Ctrl + Shift + P,打开命令窗口,输入ssh connect to host,选择第一个(在当前窗口连接)或第二个(在新窗口连接)都可以。12.该用户第一次访问该服务器可以看到该提示信息,耐心等待即可,这时是插件在服

本文提出了一种基于多智能体近端策略优化(MAPPO)的航天器编队控制系统,实现了8个航天器在动态碎片环境中的精确编队变换。系统采用集中训练-分散执行架构,结合控制屏障函数安全约束和PD控制器混合策略,达到了编队误差≤14m、位置误差≤10m的严格指标。关键技术包括:1)动态混合控制策略,根据距离自适应调整MAPPO和PD控制器权重;2)安全优先经验回放机制,提升避障成功率至100%;3)多目标奖励
在当今数字化与智能化飞速发展的时代,深度学习作为人工智能领域的核心技术,正以前所未有的速度改变着我们生活的方方面面。从图像识别到自然语言处理,从医疗诊断到智能安防,深度学习模型的强大能力不断突破人们的想象。而这一切令人瞩目的成就背后,高质量的数据无疑是推动其发展的关键动力。在众多数据来源中,安检 DR 数据正逐渐崭露头角,尤其是通过自主采集获得的非涉密安检 DR 数据,为深度学习训练带来了独特且巨

摘要:SAM-SLR系统是CVPR2021挑战赛双赛道冠军的手语识别方案,通过骨架感知多模态融合技术突破传统识别瓶颈。该系统创新性地整合RGB、光流、深度和骨架四种模态,采用3D卷积网络处理视觉信息,图卷积网络建模骨架时空关系,并通过精心调优的加权融合策略实现最优性能。实验证明,该系统在AUTSL等多个数据集上达到SOTA水平,为听障人士沟通提供了技术突破。文章详细解析了系统架构、数据处理流程和训
摘要:Prompt Studio是一款开源本地化提示词优化工具,能将口语化输入转化为结构化提示词。其核心价值在于:1)通过"人话输入-模型优化-最终确认"的三步流程降低人机沟通成本;2)严格本地化运行保障数据安全,支持OpenAI兼容API和Ollama本地部署;3)提供多风格提示词模板和API接口,平衡易用性与专业性。项目采用MIT协议,强调透明可控的技术伦理,为提示词工程提
文件名为Rec3D.tif。

谷歌第一个:https://www.mathworks.com/matlabcentral/fileexchange/8797-tools-for-nifti-and-analyze-image。下载后将解压后的文件夹放入MATLAB安装路径中的toolbox中。4.在workspace中可以查看nii 数据,并提取数据。2.在MATLAB中加载工具包路径;cd(‘nii所在文件夹’)a 矩阵就是
13.如果长时间都一直是该情况,可以使用Ctrl + Shift + P,打开命令窗口,输入reload window来重新加载窗口(会要求你重新手动输入密码)8. 使用Ctrl + Shift + P,打开命令窗口,输入ssh connect to host,选择第一个(在当前窗口连接)或第二个(在新窗口连接)都可以。12.该用户第一次访问该服务器可以看到该提示信息,耐心等待即可,这时是插件在服
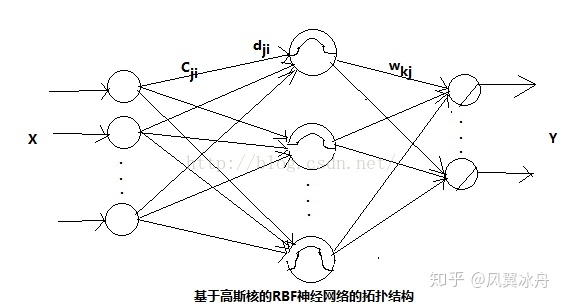
在开始这个话题之前要告诉大家一个不幸的消息:RBF神经网络无论如何都替代不了传统的向前传播型网络,肯能你马上就要滑走了,但请等等!!!这并不妨碍RBF在如今各行各业中的广泛应用。可以打个比方说RBF是方仲永,那个最终泯然众人的家伙,但是其年幼时的风光、天才的智慧也值得我们来说一说!径向基(RBF)网络是一个三层的网络,除了输入输出之外仅有一个隐藏层。隐藏层中的转换函数是局部响应的高斯函数,而其他向