




- @weixin_44584198
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
LunarLander复现:07、基于LunarLander登陆器的DQN强化学习案例(含PYTHON工程)08、基于LunarLander登陆器的DDQN强化学习(含PYTHON工程)09、基于LunarLander登陆器的Dueling DQN强化学习(含PYTHON工程)
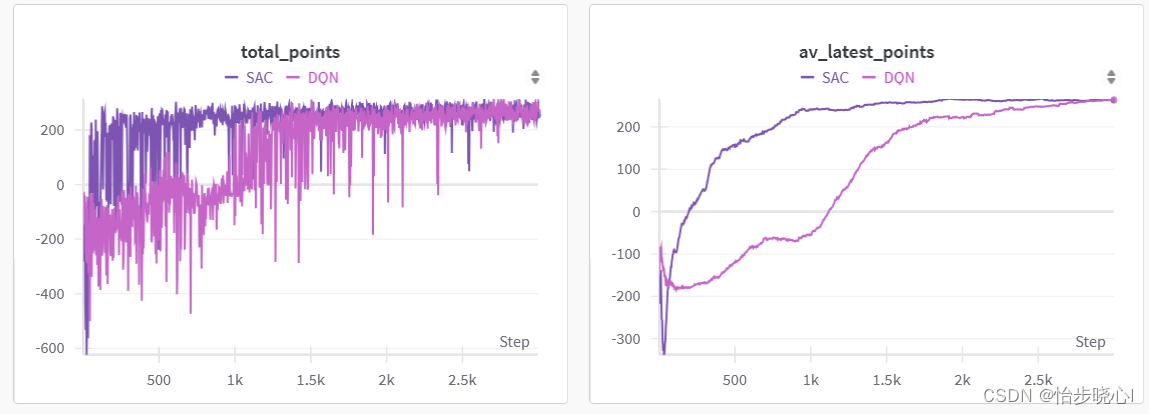
stochastic policies: 这是指实际执行的动作是对概率分布采样得到的,因为TRPO and PPO都是AC框架下的产物,其执行的动作取决于输出策略网络的概率分布的采样。deterministic policies:可以通过网络给每个动作的打分,通过贪婪策略选定最高打分的动作执行。on-policy&off-policy:on-policy就是采样的数据和某个策略强绑定,也就是采样的
在实际进行电路系统理论分析时,我们往往需要用到一些十分理想化的器件来进行模拟,例如无限带宽且没有损耗的功分器、无限带宽的3dB电桥等等。这些主要是在理想的架构理论仿真中使用。在ADS中,不是所有的微波器件都提供了理想模型,但是提供了基于传输端口参数(S、Z、Y)的器件模型,我们可以通过给定矩阵参数,自定义器件的行为,非常好用。例如,对于四端口器件的模型是这样的,写入端口矩阵就能得到自己想要的理想器

本文以 Ansys Siwave 为例,介绍了 PCB 上 eMMC 信号的波形与眼图仿真流程,包括 IBIS 模型导入、仿真向导配置、激励源设置及时域参数选择等关键步骤。结合数据线、时钟线和命令线的不同特点,说明了 PRBS 与自定义比特序列在 SI 分析中的应用方法。随后通过接收端波形和眼图结果,分析了眼高、眼宽、抖动、噪声、ISI、反射与串扰等核心指标的工程意义。整体内容适合作为 Siwav
负载调制平衡放大器Load Modulation Balanced PA,简称LMBA是2016年Cripps大佬分析实践的:An Efficient Broadband Reconfigurable Power Amplifier Using Active Load ModulationLMBA本质是是一种双输入的架构,在实现宽带和高回退方面具备优势。但是与常规的双输入的Doherty、Outp

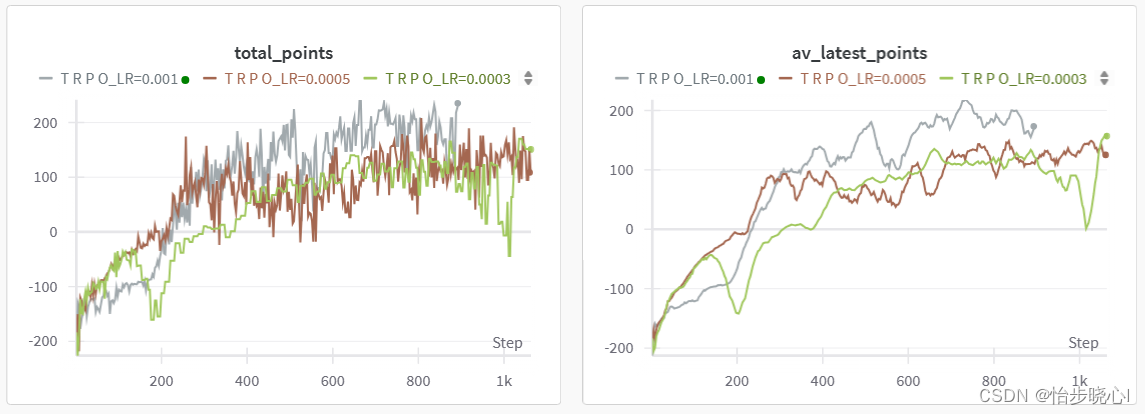
TRPO强化学习算法主要分为3个部分,分别介绍其理论、细节、实现本文主要介绍TRPO的理论和代码的对应、实践其他算法:07、基于LunarLander登陆器的DQN强化学习案例(含PYTHON工程)08、基于LunarLander登陆器的DDQN强化学习(含PYTHON工程)09、基于LunarLander登陆器的Dueling DQN强化学习(含PYTHON工程)10、基于LunarLander
stochastic policies: 这是指实际执行的动作是对概率分布采样得到的,因为TRPO and PPO都是AC框架下的产物,其执行的动作取决于输出策略网络的概率分布的采样。deterministic policies:可以通过网络给每个动作的打分,通过贪婪策略选定最高打分的动作执行。on-policy&off-policy:on-policy就是采样的数据和某个策略强绑定,也就是采样的
STM32CUBEMX配置教程(十)STM32的ADC读取内部温度传感器
TYPEC无协议芯片最高可输出5V3ATYPEC协议无需额外的协议芯片最多可输出5V3A,也就是15W的功率。这时只需要合理配置CC1和CC2的连接即可。下图是一个简单的6pin的TYPEC母座。CC可以通过开关切换上拉Rp作为Source(输出端),也可以切换下拉Rd作为Sink(用电器端)。连在电压输出端的CC端的电阻为Rp,连在用电器端的CC端的电阻为Rd。CC1和CC2没有什么区别,是对称
计算电磁学三大数值算法FDTD、FEM、MOMADS、HFSS、CST 优缺点和应用范围详细教程参考书籍:The finite-difference time-domain method for electromagnetics with MATLAB simulations(国内翻译版本:MATLAB模拟的电磁学时域有限差分法)
