




- @weixin_44228413
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Power BI已成为企业数据分析的核心工具,本文深度解析社招/校招中15个高频Power BI面试题,涵盖数据建模、DAX公式、可视化设计等核心技能,附完整解题思路和避坑指南!

作者:数分大拿的Statham。

数据分析师的未来,绝不是被AI取代,而是被“会用AI的分析师”取代。从“取数工具人”到“价值掌舵者”,这条路注定充满挑战,但也风景独好。在这个数据爆炸的时代,愿你不仅能看见数据,更能看见数据背后的未来。
作者:数分大拿的Statham。
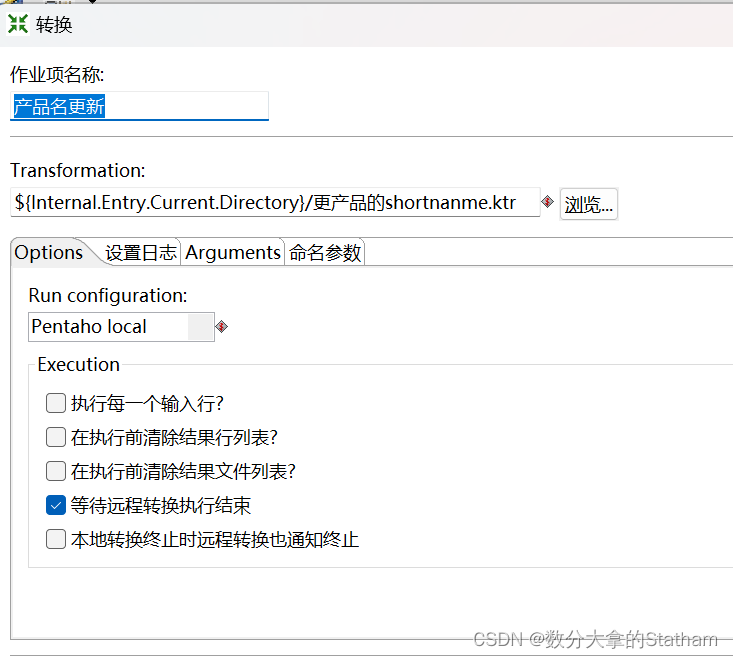
在配置ktr的时候,点击右键,配置编辑作业入口 然后会看到transformation 的输入框,这时候我们把路径 写为${Internal.Entry.Current.Directory}/每个作业对应ktr路径,如果我们想要配置一次,然后多次使用的话。这样我们在把整个文件发给其他使用者的时候 ,其他使用者就不用在配置路径啦。这样我们在把整个文件发给其他使用者的时候 ,其他使用者就不用在配置路径
数据分析师的未来,绝不是被AI取代,而是被“会用AI的分析师”取代。从“取数工具人”到“价值掌舵者”,这条路注定充满挑战,但也风景独好。在这个数据爆炸的时代,愿你不仅能看见数据,更能看见数据背后的未来。
Power BI已成为企业数据分析的核心工具,本文深度解析社招/校招中15个高频Power BI面试题,涵盖数据建模、DAX公式、可视化设计等核心技能,附完整解题思路和避坑指南!
Excel是数据分析师的核心工具之一,掌握常见面试题的解题思路能让你在求职中脱颖而出。本文整理了数据分析岗位面试中高频的Excel题目。

摘要:掌握Numpy和Pandas是数据分析师的核心竞争力!本文精选20道企业高频面试题,覆盖数组操作、数据清洗、性能优化等核心场景,提供代码解析+避坑指南,助力面试冲刺!

数据分析师的未来,绝不是被AI取代,而是被“会用AI的分析师”取代。从“取数工具人”到“价值掌舵者”,这条路注定充满挑战,但也风景独好。在这个数据爆炸的时代,愿你不仅能看见数据,更能看见数据背后的未来。