- @weixin_43224466
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍如何使用Ollama在本地电脑上运行大语言模型,实现离线AI助手功能。详细讲解了Ollama在Windows、macOS和Linux系统的安装方法,以及常用命令操作(模型下载、运行和删除)。重点展示了如何通过Python调用本地模型API进行问答交互,并对比了本地模型与在线模型在响应速度、隐私保护和成本方面的优势。通过简单的代码示例,读者可以快速上手将大模型部署到个人电脑,打造专属AI助手

今天我们把过去一周的知识全部融合在一起,打造了一个功能强大、完全离线的本地轻量Agent。它:✅ 基于LangChain + Ollama,离线运行✅ 拥有丰富的工具(天气、计算器、时间、文件操作、随机数等)✅ 具备记忆(摘要记忆,节省token)✅ 有友好的命令行交互界面✅ 经过参数优化,响应速度更快。

摘要:本文介绍如何使用LangChain和Ollama搭建完全离线的AI助手,解决在线模型依赖网络、隐私泄露等问题。通过配置LangChain连接本地Ollama模型(如Qwen 7B),创建支持工具调用(计算器、时间查询)的Agent,并优化响应速度。文章详细展示了环境准备、工具定义、Agent构建及性能优化步骤,帮助开发者打造安全高效的本地AI应用。
本文提供了一个从零搭建RAG系统的实战教程,包含通义千问、Deepseek和本地大模型三种实现方案。教程采用Python+LangChain+Chroma技术栈,详细演示了文档加载、文本拆分、向量化存储等核心步骤。特别针对中文场景优化了文本分割策略,并提供了API调用和本地模型两种向量化方案。通过构建"2026年LPR利率"的问答系统,展示了RAG如何解决大模型知识更新的问题。

本文介绍如何构建支持多格式文档的RAG知识库系统。主要内容包括: 支持PDF/Word/TXT文档的自动解析和文本提取 采用递归分块技术实现中文语义保持 可批量处理多个文档构建统一知识库 提供通义千问在线版和本地Qwen:7b两种模型方案 系统能自动解析不同格式文档,智能分块后存入向量数据库,实现跨文档精准检索。完整代码可直接运行,适合构建企业级私有知识库。

文章摘要:RAG检索与重排序深度优化方案 本文针对生产环境中基础RAG系统的痛点,提出进阶优化方案,通过混合检索和重排序技术提升准确率50%。核心方案包括:1)采用向量检索与BM25关键词检索结合的混合检索方式;2)使用通义千问或本地Qwen:7b模型进行高阶重排序;3)设计生产级Prompt模板确保回答精准性。文章提供两种实现路径:在线版利用通义API实现高性能检索,离线版基于本地模型保障数据隐

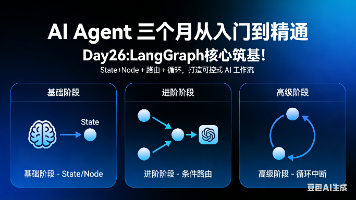
本文介绍了LangGraph框架的核心概念与应用,分为基础篇和进阶篇两部分。 基础篇重点讲解State、Node、Edge三大核心组件: State作为AI的共享记事本存储全局数据 Node作为专用功能模块执行特定任务 Edge定义执行流程路线 通过两个案例演示了单节点问答和多节点顺序工作流的实现方法,支持通义千问和本地Qwen两种模型。 进阶篇介绍了条件路由功能,使AI能够根据问题类型自主选择执
LangGraph 函数字典:从入门到精通 本文全面介绍 LangGraph 的核心 API,涵盖图构建、状态管理、执行和持久化等功能。主要内容包括: 图构建函数:StateGraph 创建基础框架,add_node 添加功能节点,add_edge 连接固定流程,add_conditional_edges 实现条件分支。 状态管理:使用 Annotated 和自定义 Reducer 控制状态合并规
大模型推理加速技术实战摘要 本文系统讲解了大模型推理加速的核心技术与实践方法。重点介绍了vLLM引擎及其革命性的PagedAttention机制,该技术通过分页式显存管理将显存利用率从50%提升至95%以上,实现3-5倍加速。文章详细对比了Ollama、vLLM和TensorRT-LLM三大工具的性能差异,其中vLLM凭借开箱即用和Python3.10完美兼容成为最优选择。实战部分提供了vLLM完
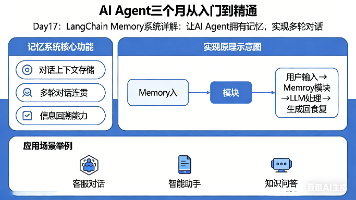
本文深入解析了LangChain的Memory系统如何为AI Agent赋予记忆能力,实现连贯的多轮对话。主要内容包括: 介绍了LangChain的两种记忆类型:短期记忆(ConversationBufferMemory)和长期记忆(ConversationSummaryMemory) 详细演示了如何将Memory集成到Agent中,通过天气查询示例展示上下文记忆功能 讲解了使用Structure