




- @weixin_43145427
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章探讨了大型语言模型(LLMs)是否拥有知识的问题,提出了LLMs具有由特定能力集定义的“工具性知识”,并讨论了这种知识与人类基于世界模型的“世俗知识”之间的关系及差异。论文题目: From task structures to world models: What do LLMs know?论文链接: https://arxiv.org/abs/2310.04276PS: 欢迎大家扫码关注公众

一个架构系统的demo中,因为里面有几个子系统是clone别人的项目,导致github这个文件夹上显示白色箭头并且不能打开。原来是因为这个文件夹里面有.git隐藏文件,github就将该文件夹视为一个子系统模块了。解决办法就是:1、删除文件夹里面的.git文件夹2、执行git rm --cached [文件夹名]3、执行git add [文件夹名]4、执行git commit -m "msg"5、

在系统上安装好Git后,还需要配置Git 环境。 每台计算机上只需要配置一次,程序升级时会保留配置信息,也可以在任何时候再次通过运行命令来修改它们。配置文件位置Git 自带一个git config的工具来帮助设置配置变量,这些变量存储在三个不同的位置:/etc/gitconfig文件: 包含系统上每一个用户及他们仓库的通用配置。 如果在执行git config时带上--system选项,那么它就会

docker-compose中的配置命令很多都是Dockerfile中的命令,不过需要遵循yml的文件格式。下面讲解yml配置是针对单服务器的容器管理,如果是集群模式配置会稍微有些不同。version指定本 yml 依从的 compose 哪个版本制定的。build指定为构建镜像上下文路径:例如 webapp 服务,指定为从上下文路径 ./dir/Dockerfile 所构建的镜像:version

有时候同一个分支,远程仓库的和本地的都被修改的面目全非了,变得很不一致了。如果想要把本地的替换成远程的,即用远程分支覆盖本地分支。第一种方式: reset --hard 参数git fetch --allgit reset --hard origin/dev (这里dev要修改为对应的分支名)git pull origin dev第二种方式:pull --force参数有的时候,已经知道远程分支与

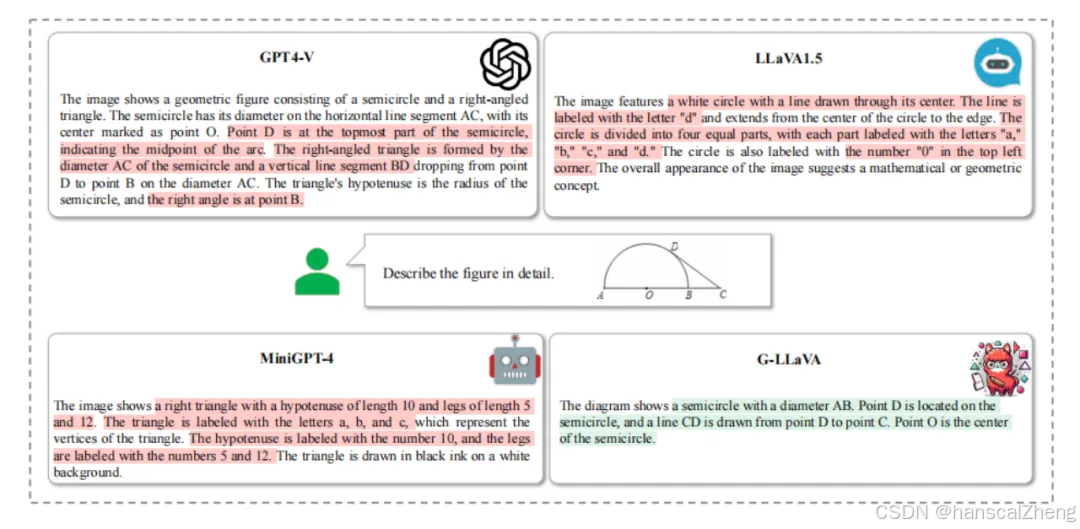
本文提出了G-LLaVA智能体,通过构建增强的几何数据集Geo170K,显著提高了多模态大语言模型在几何问题解决中的表现。论文题目: G-LLaVA: Solving Geometric Problem with Multi-Modal Large Language Model论文链接: https://arxiv.org/abs/2312.11370PS: 欢迎大家扫码关注公众号,我们一起在AI
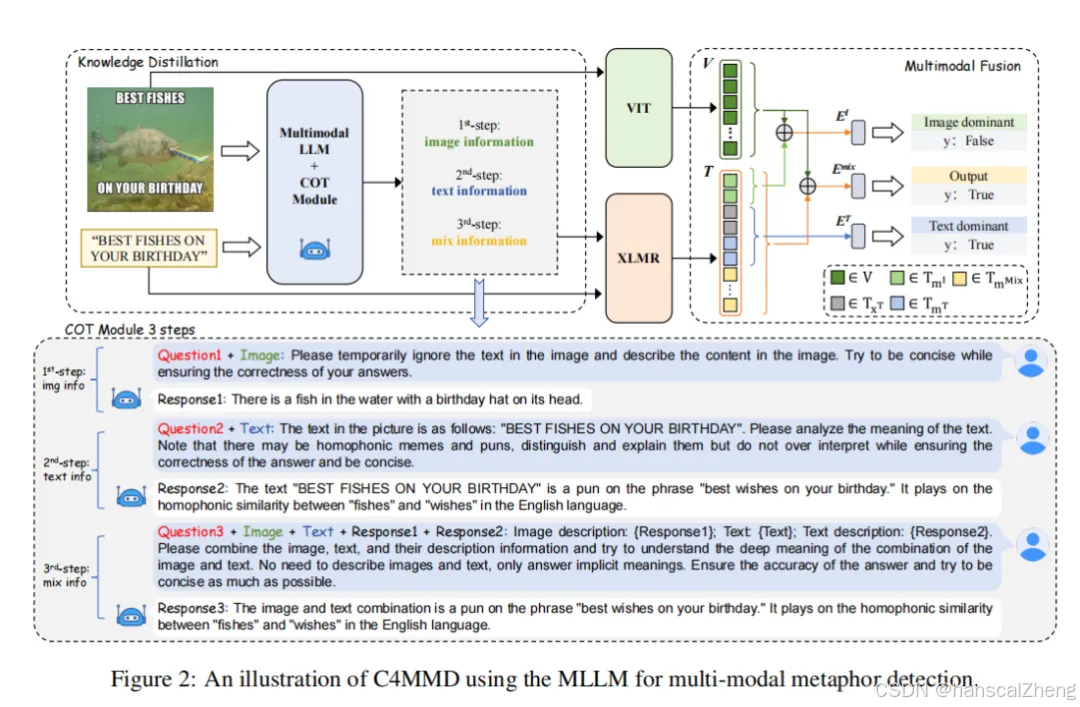
文章提出了一种名为C4MMD的框架,通过链式思维方法增强智能体对多模态隐喻的检测能力,显著提高了模型的表现。论文题目: Exploring Chain-of-Thought for Multi-modal Metaphor Detection论文链接: https://aclanthology.org/2024.acl-long.6/PS: 欢迎大家扫码关注公众号,我们一起在AI的世界中探索前行,
本文提出了G-LLaVA智能体,通过构建增强的几何数据集Geo170K,显著提高了多模态大语言模型在几何问题解决中的表现。论文题目: G-LLaVA: Solving Geometric Problem with Multi-Modal Large Language Model论文链接: https://arxiv.org/abs/2312.11370PS: 欢迎大家扫码关注公众号,我们一起在AI
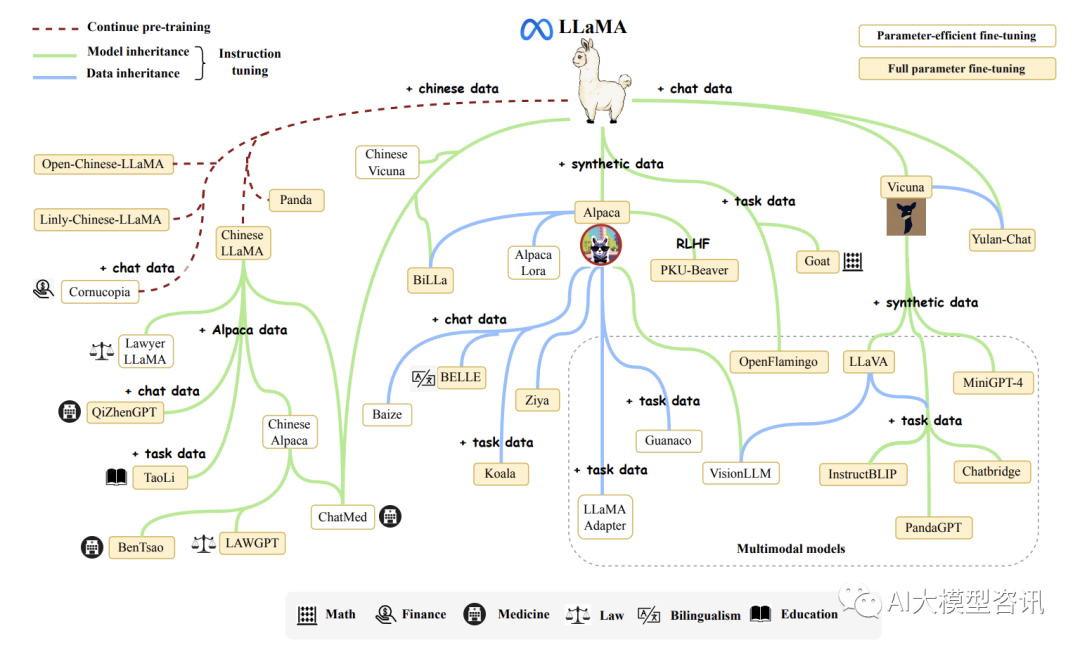
LLaMA 模型集合由 Meta AI 于 2023 年 2 月推出, 包括四种尺寸(7B 、13B 、30B 和 65B)。由于 LLaMA 的 开放性和有效性, 自从 LLaMA 一经发布, 就受到了研究界和工业界的广泛关注。LLaMA 模型在开放基准的各 种方面都取得了非常出色的表现, 已成为迄今为止最流行的开放语言模型。大批研究人员通过指令调整或持续 预训练扩展了 LLaMA 模型。特别需
优雅规范的注释有助于对代码理解,易于与人合作开发,提高效率。但若没有自动化的注释会让写注释耗时耗力。可以自动生成功能和用途简介、参数、返回值、创建人、创建时间、修改人、修改时间、版权声明、异常抛出。下面介绍在 pyCharm中使用两种方式的注释:1. 文件头规范自动生成在文件头加上创建人、创建时间、修改人、修改时间、版权声明;有些规范建义这些元素写在文件头部。可通过如下方法设置:File->
