




- @weixin_42322991
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这些技术知识点可以配合使用,帮助我们快速构建出具有 CRUD 功能的 Web 应用,并且遵循了 Django 框架的惯例和最佳实践。它们的应用场景包括博客系统、电商平台、社交网络等各种类型的 Web 应用。通过使用这些技术知识点,我们能够提高开发效率,减少重复的代码编写工作,并且保证代码的一致性和可维护性。ModelViewSet 是 Django REST framework 提供的一个视图集类

1. AttributeError: Can't pickle local object 'train..collate_fn'2. cv2.ernor: penCV(4.6.0) n: alopenvw-pythanlopencvo-python oncvlmoutesirgproelarc Loton .op.12: evw:(-215.Assartion faitad ! syc.empty
1. 什么是机器学习 ( Machine Learning )?2. 机器学习的分类2.1 监督学习的分类3. 机器学习算法过程4. 没有午餐定理5. 总结6. 测试
1. AttributeError: Can't pickle local object 'train..collate_fn'2. cv2.ernor: penCV(4.6.0) n: alopenvw-pythanlopencvo-python oncvlmoutesirgproelarc Loton .op.12: evw:(-215.Assartion faitad ! syc.empty
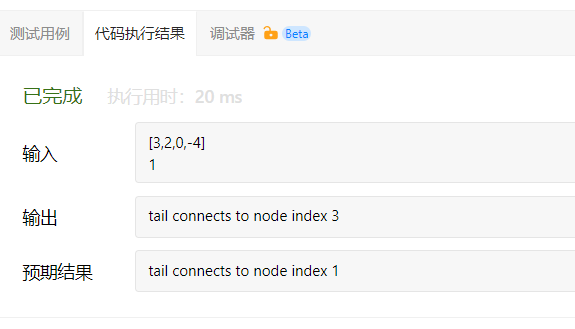
为了表示给定链表中的环,使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。题意: 给定一个链表,返回链表开始入环的第一个节点。如果链表无环,则返回 null。:不允许修改给定的链表。看了代码随想录的视频。
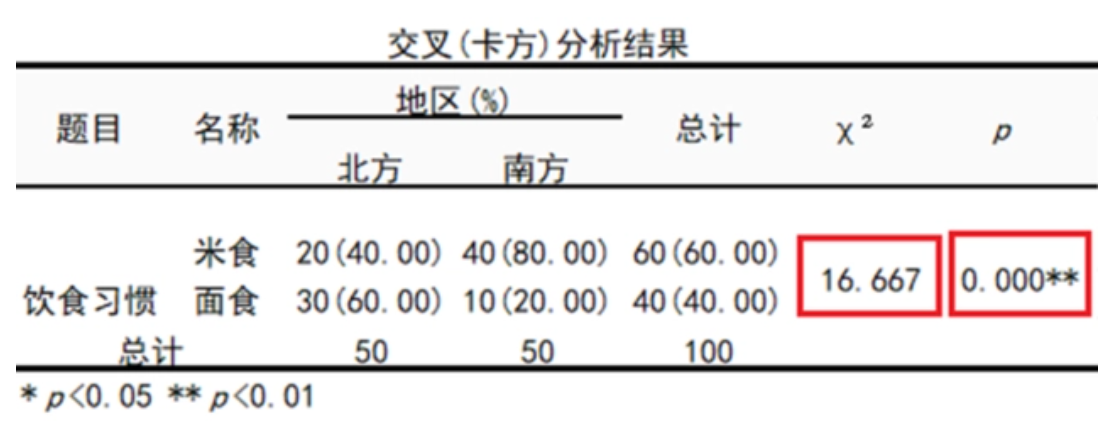
卡方值的大小与样本量(自由度)有关。一般来说,卡方值越大越好,但并不准确。比如5000和5010的差异为10;40和50的差异为10,明显后者差异更大。可以看到卡方值为16.667,p =0.000<0.01,所以不同地区的饮食习惯情况呈现出。例如研究人员想知道两组学生对于手机品牌的偏好差异情况。使用频率高,仅使用Pearson卡方,不支持加权数据。卡方值表示观察值与理论值之间的偏离程度。一般使用
1. AttributeError: Can't pickle local object 'train..collate_fn'2. cv2.ernor: penCV(4.6.0) n: alopenvw-pythanlopencvo-python oncvlmoutesirgproelarc Loton .op.12: evw:(-215.Assartion faitad ! syc.empty