




- @weixin_42038527
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
组织类型(54):GTEx数据库简介(1) - 知乎 (zhihu.com)TCGA、ICGC、GTEx 数据库都是啥?- 知乎 (zhihu.com)GTEx:基因型和基因表达量关联数据库-CSDN博客。

深度学习在药物发现中常因“分布外”(OOD)分子而失效——模型对结构新颖的分子预测不可靠,却可能给出高置信度的错误答案。如何让模型知道自己“没见过”某个分子?2026年《Nature Machine Intelligence》的一项研究给出了答案:不熟悉度(Unfamiliarity)。作者提出联合分子模型(JMM),通过分子SMILES的自编码重构损失量化陌生感,并结合谱聚类主动划分OOD测试集

DrugBank是一个综合性的生物信息学和化学信息学数据库,专门收录药物和靶点的详细信息。它由加拿大阿尔伯塔大学的Wishart 研究组维护,提供化学、药理学、相互作用、代谢、靶点等多方面的药物数据。DrugBank 结合了实验数据和计算预测,广泛应用于药物研发、精准医疗、生物信息学研究等领域。

深度学习在药物发现中常因“分布外”(OOD)分子而失效——模型对结构新颖的分子预测不可靠,却可能给出高置信度的错误答案。如何让模型知道自己“没见过”某个分子?2026年《Nature Machine Intelligence》的一项研究给出了答案:不熟悉度(Unfamiliarity)。作者提出联合分子模型(JMM),通过分子SMILES的自编码重构损失量化陌生感,并结合谱聚类主动划分OOD测试集
CD-HIT是一款高效的生物序列聚类工具,通过贪心算法和局部敏感哈希快速将相似序列分组。它通过设置相似度阈值(如0.4-0.9)来降低数据冗余,在蛋白质相互作用预测中尤为重要,能防止模型通过记忆相似序列而非学习互作模式导致的评估偏差。

DrugBank是一个综合性的生物信息学和化学信息学数据库,专门收录药物和靶点的详细信息。它由加拿大阿尔伯塔大学的Wishart 研究组维护,提供化学、药理学、相互作用、代谢、靶点等多方面的药物数据。DrugBank 结合了实验数据和计算预测,广泛应用于药物研发、精准医疗、生物信息学研究等领域。
组织类型(54):GTEx数据库简介(1) - 知乎 (zhihu.com)TCGA、ICGC、GTEx 数据库都是啥?- 知乎 (zhihu.com)GTEx:基因型和基因表达量关联数据库-CSDN博客。
在AI for Science领域,一项来自新加坡国立大学的研究重磅登陆《自然·通讯》,为蛋白质-蛋白质相互作用预测带来了范式转变。传统单链蛋白质语言模型(如ESM2)虽强,却像是训练“独行侠”,无法从根本上理解两个蛋白如何协同工作。为此,研究者提出了 PPLM —— 一个开创性的蛋白质配对语言模型。PPLM的核心革命在于其联合编码的预训练方式。它通过独创的混合链内/链间注意力机制,在模型底层就

不再满足于看懂单个蛋白质,新一代蛋白质语言模型MINT通过跨链注意力机制,直接从海量序列中学习蛋白质之间如何“握手”与“交谈”,在抗体设计、癌症突变解读、病毒免疫逃逸预测等领域大放异彩。
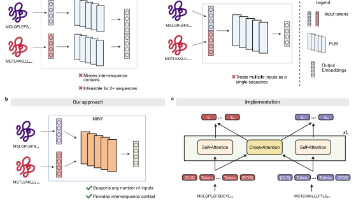
在AI for Science领域,一项来自新加坡国立大学的研究重磅登陆《自然·通讯》,为蛋白质-蛋白质相互作用预测带来了范式转变。传统单链蛋白质语言模型(如ESM2)虽强,却像是训练“独行侠”,无法从根本上理解两个蛋白如何协同工作。为此,研究者提出了 PPLM —— 一个开创性的蛋白质配对语言模型。PPLM的核心革命在于其联合编码的预训练方式。它通过独创的混合链内/链间注意力机制,在模型底层就