




- @weixin_39918374
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
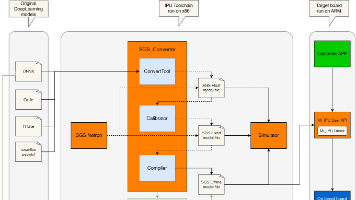
本文详细介绍了IPU工具链中模型转换的完整流程,主要包括:1. 模型转换配置文件input_config.ini的编写指南,涵盖输入输出配置、量化参数设置等核心内容;2. 前处理脚本的编写规范,针对不同数据格式(RGB/BGR/GRAY/RAWDATA等)提供了具体示例;3. 使用SGS_converter工具将原始模型转换为端侧离线模型的完整方法。其中重点说明了ONNX框架作为主力支持平台的优势
Alkaid SDK是基于Linux内核的软件开发包,用于在Sigmastar平台构建多媒体应用。SDK采用分层架构,包含应用层、软件库层、驱动层和硬件层,支持音频、图像处理、显示等多媒体功能,通过MI模块提供易用API。主要目录包括bootloader、kernel、SDK源码和工程文件,支持多种存储介质配置。编译流程自动生成对应烧录文件,包括内核、根文件系统和分区表等。开发者可通过CoMake

摘要:本文详细介绍了自动白平衡(AWB)的技术原理与参数调整方法。AWB通过补偿R、B增益使灰阶区域的RGB值接近,消除不同光源下的色偏。系统将画面分割为64×90区域进行统计,通过AWBAnalyzer插件可实时查看统计数据。调整界面包含多种参数设置:色温框选择、收敛阈值、算法模式(如GrayWorld、Normal等)、混光校正、特殊场景处理等。还介绍了WB增益限制、亮度权重、区域权重等进阶功

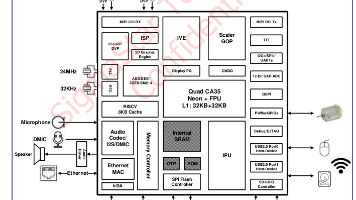
星宸科技SSD2355芯片是一款低功耗AIoT芯片,采用4核A35 1.5GHz CPU+576MHz RISCV协处理器的多核异构方案,搭载1T NPU算力,支持主流AI框架和Transformer模型优化。具备丰富外设接口(MIPI、UART、I2C、SPI等)、8通道DMIC、3通道AMIC音频处理能力,支持双百兆网口、双USB2.0、安防级ISP和TrustZone安全功能。开发者可通过C
Alkaid SDK是基于Linux内核的软件开发包,用于在Sigmastar平台构建多媒体应用。SDK采用分层架构,包含应用层、软件库层、驱动层和硬件层,支持音频、图像处理、显示等多媒体功能,通过MI模块提供易用API。主要目录包括bootloader、kernel、SDK源码和工程文件,支持多种存储介质配置。编译流程自动生成对应烧录文件,包括内核、根文件系统和分区表等。开发者可通过CoMake
本文档详细介绍了PCUPID系列芯片的硬件看门狗机制。主要内容包括:1) 看门狗的基本原理和工作机制;2) 硬件与软件看门狗的区别;3) Linux内核和Uboot下的配置使用方法;4) 相关DTS配置说明;5) 通过/dev/watchdog设备文件进行喂狗、设置超时等操作的示例代码。文档提供了从底层驱动到应用层的完整开发指导,帮助开发者正确使用看门狗功能实现系统监控和自动恢复。

摘要:本文详细介绍了传感器驱动移植(Porting)的完整流程。首先需要确认传感器硬件连接正确,获取厂商提供的数据手册和初始化表。驱动开发需配置传感器参数结构体,包括图像参数、接口参数、上下电控制等。关键步骤包括:1)实现电源管理时序;2)配置分辨率参数;3)设置I2C通信参数;4)实现MIPI数据接口配置。文章还详细讲解了帧率调节、曝光控制、增益调节等功能的实现方法,并提供了驱动验证方案。整个过

摘要:本文档详细介绍了Pcupid芯片音频子系统(AudioOutput)的架构与功能。主要内容包括:1)音频输出模块(AO)的硬件资源管理机制,涵盖DMA控制器、编解码器及接口设备;2)关键概念解析,如Device/Interface的绑定关系、声道模式、增益控制等;3)各芯片系列(Muffin/Mochi/Maruko/Souffle/Pcupid)的硬件差异对比;4)开发流程说明,包括编译配

本文介绍了SigmaStar PCUPID系列芯片的WLAN使用方案,重点说明如何通过外置WiFi模组实现无线功能。文章详细阐述了硬件连接方式(SDIO/USB接口)、内核配置方法(包括设备树修改和驱动加载)、常用WiFi工具(如wpa_supplicant、hostapd等)的使用说明,并提供了STA模式、AP模式和桥接模式的具体测试步骤。特别针对Comake_Pi_D1开发板给出了USB接口W

本文介绍了Comake PID1开发板的点屏程序功能及配置说明。主要包含两个演示场景:GUI旋转功能(支持0/90/180/270度旋转)和GUI图案功能(显示三色渐变图),均支持单/双buffer模式。详细说明了编译环境配置、屏幕参数设置、dts修改方法,以及程序编译部署流程。同时提供了运行环境搭建指南、演示命令格式(如./prog_gfx_gfx_demo 0 1 0表示旋转场景+MIPI屏+
