




- @weixin_39671271
简介
🌞 Hello,我是愚者Turbo!北极代码库贡献者 本博客专注于分享开源技术、云原生架构、DevOps 实践以及个人生活随笔。 内容涵盖 Java、Python、Go、大数据、AI、Kubernetes、Service Mesh、容器化、微服务等技术,同时记录作者在技术成长过程中的思考与经验, 旨在为广大开发者和技术爱好者提供有价值的参考与交流平台。
擅长的技术栈
可提供的服务
加入到我的星球之后,你将获得: 一.3个高质量的专栏永久阅读,内容涵盖Java面试宝典,源码解析,项目实战等内容! 二.免费的简历修改服务。 三.一对一免费提问交流,模拟面试(保驾护航)。 四.专属求职指南和建议,效率翻倍,不走弯路! 五.海量 Java 优质面试资源分享。 六.打卡活动,读书交流,学习交流,让学习不再孤单,报团取暖。 七.不定期福利:节日抽奖、送书送课、球友线下聚会等等。
Spring Data Neo4j(SDN)是Spring Data项目的一部分,它专为简化Neo4j图数据库在Spring应用中的集成而设计。SDN的核心目标是通过对象图映射(OGM)技术,将Java对象与Neo4j的图数据模型建立映射关系,使开发者能够像操作传统Java对象一样操作图数据库。通过SDN,开发者无需直接编写Cypher查询语言,而是可以利用Spring框架的风格和特性来操作Neo
Spring Cloud Task作为微服务架构中的轻量级任务调度框架,为开发人员提供了一种构建短生命周期微服务任务的便捷方式。它允许开发者快速创建、执行和管理一次性任务或短期批处理作业,任务执行完成后自动关闭以释放系统资源,避免了传统长期运行微服务的资源浪费问题。
Spring Cloud Kubernetes是连接Spring Cloud生态与Kubernetes容器编排平台的关键桥梁,它通过适配器模式将Spring Cloud接口与Kubernetes原生资源对接,使Java微服务开发者能够在不放弃Spring生态便利性的同时,充分利用Kubernetes的云原生能力。
Alluxio 是世界上第一个面向基于云的数据分析和人工智能的开源的数据编排技术。 它为数据驱动型应用和存储系统构建了桥梁, 将数据从存储层移动到距离数据驱动型应用更近的位置从而能够更容易被访问。 这还使得应用程序能够通过一个公共接口连接到许多存储系统。 Alluxio内存至上的层次化架构使得数据的访问速度能比现有方案快几个数量级。
Spring Cloud Circuit Breaker是微服务架构中防止服务雪崩的关键容错组件,它通过熔断、降级、限流等机制保护服务调用链路,确保系统整体稳定性。 作为Spring Cloud生态系统的核心组件之一,它为分布式系统提供了断路器模式的实现,能够有效应对服务间依赖导致的级联故障。
Spring Cloud Bus作为微服务架构中的关键组件,通过消息代理实现分布式系统中各节点的事件广播与状态同步,解决了传统微服务架构中配置刷新效率低下、系统级事件传播复杂等问题。它本质上是一个轻量级的事件总线,将Spring Boot Actuator的端点功能扩展到分布式环境中,使开发者能够通过统一的接口管理微服务集群的配置更新和状态变化。
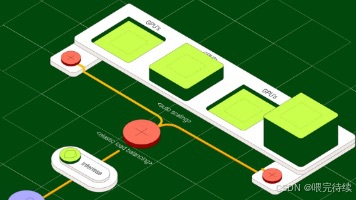
Spring Cloud Data Flow(SCDF)是一个用于构建、部署和管理数据流应用的开源框架,它简化了数据管道的开发与运维,使开发人员能够专注于业务逻辑而非底层基础设施细节。SCDF基于Spring Boot和Spring Cloud生态系统构建,支持流式处理和批处理任务的统一编排,为现代云原生环境提供了灵活的数据流管理工具。
Apache Ozone是Apache Hadoop生态中的新一代分布式对象存储系统,专为解决HDFS在扩展性和小文件处理方面的局限性而设计。作为面向技术开发人员的深度指南,本文将从基础概念到架构设计,再到实际应用,全面解析Ozone的技术特性与价值。

2025年大数据技术迎来关键突破,从基础设施到应用场景实现全面升级。东数西算、工程推动算力市场规模达8351亿元,湖仓一体架构成为企业标配。隐私计算与可信数据空间保障数据安全流通,AI融合创新催生多模态分析等新技术。工业、农业、医疗等领域应用深化,数据要素市场化加速推进。技术栈向智能化演进,Flink2.0提升实时处理能力。未来将面临数据流通壁垒等挑战,但量子计算等前沿技术将带来新机遇。大数据正成

HDFS(Hadoop分布式文件系统)是Apache Hadoop生态系统的核心组件,专为大规模数据集设计,能够在廉价商用硬件上提供高可靠性和高吞吐量的数据存储服务。 作为大数据处理的基础设施,HDFS解决了传统文件系统在处理海量数据时面临的扩展性、容错性和吞吐量瓶颈问题,为MapReduce等分布式计算框架提供了理想的底层存储支持。本文将从HDFS的诞生背景、架构设计、核心特性到使用方法进行全面
