- @u013531166
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
今日在使用mybatisplus的雪花算法自动给id赋值时发现怎么都是null的情况,这尼玛测了半天,终于发现巨坑,废话不多说,直接上干货。

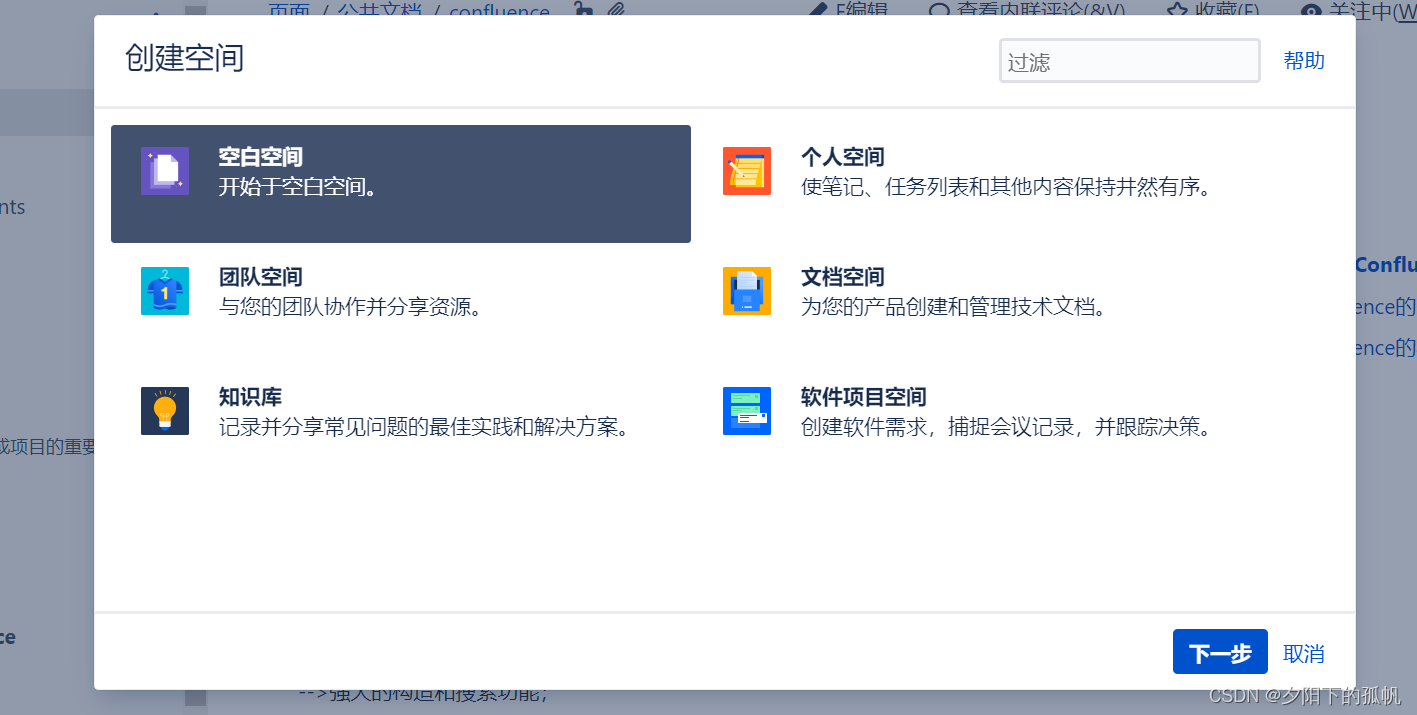
需要安装python,不同matlab版本需要下载对用的python版本!!!!,切记!!!!否则程序无法运行,下图是展示了matlab和python之间的版本对应。
短时傅里叶变换(Short-Time Fourier Transform, STFT)是一种时频分析方法,用于分析非平稳信号的频率成分随时间的变化。与传统的傅里叶变换不同,STFT在处理信号时考虑了时间局部性,使得它能够同时在时间域和频率域上分析信号。STFT的基本思想是使用一个滑动窗口函数,将信号分割成若干个短时段,对每个时段进行傅里叶变换。

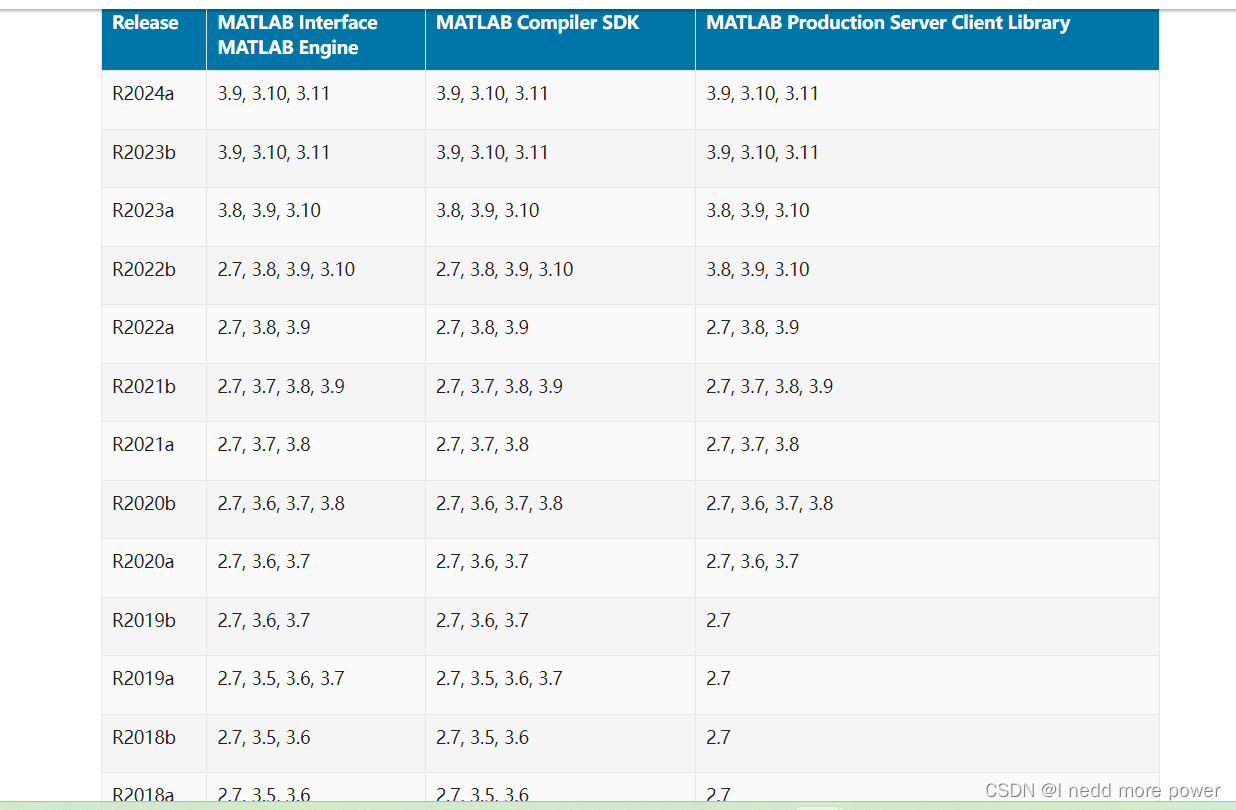
主成分分析(Principal Component Analysis, PCA)是统计学中一种重要的降维技术。它通过寻找数据中各特征之间的线性关系,来降低数据的维度,同时保留数据中的主要信息。PCA在机器学习、信号处理、图像处理等领域广泛应用,特别是在数据降维、特征提取和模式识别中有着重要作用。本文将介绍PCA的基本原理、应用,以及一些高级应用,帮助大家理解PCA在实际问题中的重要性。
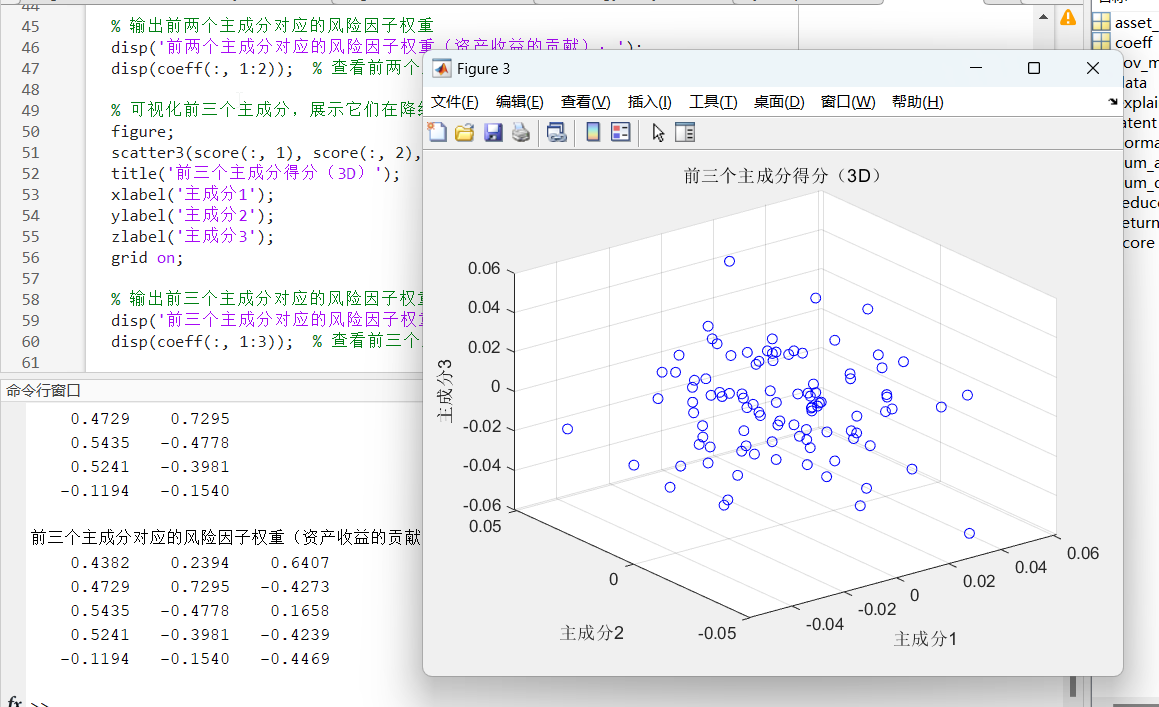
加权移动平均(Weighted Moving Average,简称WMA)是一种用于时间序列数据平滑和分析的技术。它与简单移动平均(Simple Moving Average, SMA)类似,但不同之处在于加权移动平均对不同的历史数据点赋予不同的权重,从而使得对最近的数据点赋予更大的影响力。这使得WMA在捕捉数据的趋势和波动性方面比SMA更加灵敏加权移动平均是指对一段时间内的历史数据按照预设的权重

指数加权移动平均(Exponential Moving Average, EMA)是一种用于平滑时间序列数据的技术,它通过对历史数据赋予不同的权重来实现平滑。与简单移动平均(SMA)不同,EMA对最近的数据赋予更大的权重,从而能够更敏感地反映数据的近期变化趋势。这使得EMA在金融市场分析、信号处理和其他时间序列预测领域得到了广泛应用指数加权移动平均(EMA)是一种强大的时间序列平滑工具,因其对最新
举个例子,常见的JPEG图像文件的魔数是FF D8 FF,PDF文件的魔数是25 50 44 46,ZIP文件的魔数是50 4B 03 04等等。文件魔数(Magic Number)是文件的一小部分数据,通常是文件的头部字节,用来识别文件的类型。每种文件类型都有其特定的魔数,这些魔数是固定的,并且不同文件类型的魔数通常是不同的。我们判断一个上传文件的格式,大多数会进行后缀判断,可是文件的后缀格式可

在一个企业中,在一个团队中,文档协同的及时性,方便性,丰富性是决定项目进度关键要素之一。工欲善其事必先利其器,所以现在接下来,我们介绍一下目前地球上最好用的在线文档协同工具(没有之一)----confluence提示:以下是本篇文章正文内容,下面案例可供参考应用市场进入点击右上角小齿轮—》管理应用然后点击查找新应用在输入框输入要安装的插件即可。