写文章




- @taotao_guiwang
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
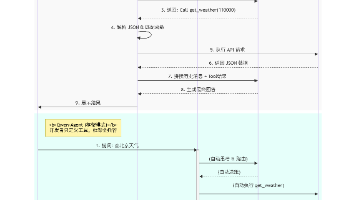
借助LangChain使用ReAct范式搭建一个本地知识智能客服
借助LangChain使用ReAct范式搭建一个本地知识智能客服

对比原生 Function Calling(手搓)与Qwen-Agent(框架模式)在实现上的差异
对比原生 Function Calling(手搓)与Qwen-Agent(框架模式)在实现上的差异
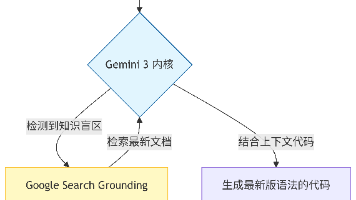
【硬核测评】Gemini 3 编程能力全面进化:不仅仅是 Copilot,更是你的 AI 架构师
【硬核测评】Gemini 3 编程能力全面进化:不仅仅是 Copilot,更是你的 AI 架构师
【Java AI 新纪元】Spring AI 深度解析:让 Java 开发者无缝接入大模型
【Java AI 新纪元】Spring AI 深度解析:让 Java 开发者无缝接入大模型
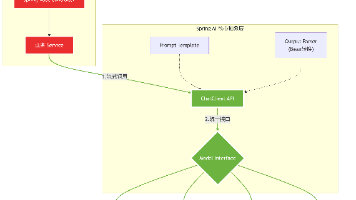
实战:用 Spring Boot 搭建 Model Context Protocol (MCP) 服务
实战:用 Spring Boot 搭建 Model Context Protocol (MCP) 服务

LangChain, LangGraph, Qwen-Agent, Coze, Dify 深度对比与选型指南
LangChain, LangGraph, Qwen-Agent, Coze, Dify 深度对比与选型指南
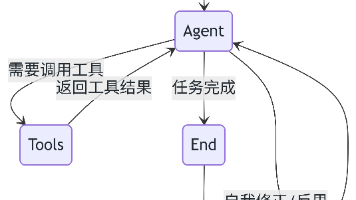
【AI Agent实战】手把手教你用 LangGraph + 通义千问打造“深思熟虑”的智能投研助手
【AI Agent实战】手把手教你用 LangGraph + 通义千问打造“深思熟虑”的智能投研助手
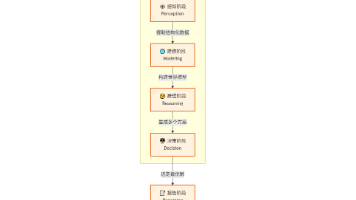
实战 LangGraph:打造“快思考”与“慢思考”结合的财富管理 AI 智能体
实战 LangGraph:打造“快思考”与“慢思考”结合的财富管理 AI 智能体
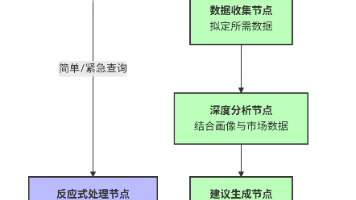
【实战】InternVideo2.5:基于 Python 实现高性能视频理解与多模态对话
【实战】InternVideo2.5:基于 Python 实现高性能视频理解与多模态对话
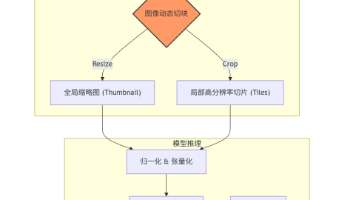
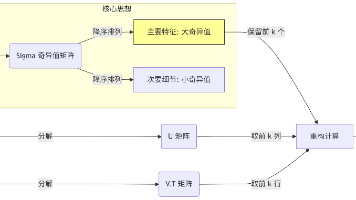
【图像处理】Python 实现 SVD 奇异值分解对图片进行压缩与还原
【图像处理】Python 实现 SVD 奇异值分解对图片进行压缩与还原