- @sinat_41567654
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了在AWS中国区EKS集群上部署kgateway并路由流量到Lambda函数的完整过程。首先安装Gateway API CRD和kgateway控制平面,解决中国区Docker Hub镜像拉取问题后部署httpbin示例应用。通过创建Gateway和HTTPRoute资源,kgateway自动创建Envoy代理、ServiceAccount和NLB服务。重点阐述了如何配置Lambda后端,
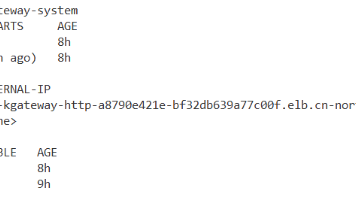
本文介绍了如何在中国区AWS搭建实时流数据处理管道,利用纽约市出租车数据(2010年1月1日-13日,540万条记录)构建运营监控仪表盘。通过Kinesis回放数据,由Managed Flink进行实时处理(1小时窗口聚合),最终写入OpenSearch可视化。系统可回答两个核心问题:各区域每小时上车次数和到机场的平均行程时间。文档详细说明了数据预处理(CSV转JSON)、网络拓扑设计(NAT子网
本文实现了 Kubernetes MCP Server 的集成,让 OCAI 具备了直接访问 EKS 集群的能力。整个过程涉及:- 理解 MCP 协议和 RAG 的分工- 采用 Streamable HTTP 模式部署MCP服务- 配置OCAI集成Kubernetes MCP Server并测试功能

本文实现了 Kubernetes MCP Server 的集成,让 OCAI 具备了直接访问 EKS 集群的能力。整个过程涉及:- 理解 MCP 协议和 RAG 的分工- 采用 Streamable HTTP 模式部署MCP服务- 配置OCAI集成Kubernetes MCP Server并测试功能
本文介绍了OpenCloudOS的OCManager开源方案,用于集中管理大规模Linux服务器集群。该系统由四个核心组件构成:运维管控核心(ocmanager和ocm-agent)和AI智能体系(ocai-service和ocai-agent)。文章详细说明了各组件的功能与交互关系,并提供了在AWS EKS节点上的部署方案,包括控制平面搭建、Agent批量下发以及AI助手集成。部署过程涉及Doc
摘要:本文探讨了将Bedrock AI模型API转换为OpenAI兼容格式的适配器开发过程。针对现有工具如LiteLLM和bedrock-access-gateway在Bedrock Tool Calling功能支持上的不足,作者开发了专用适配器解决格式转换问题。核心挑战包括消息格式差异(如OpenAI的tool_calls与Bedrock的toolUse)、Tool Result格式差异以及Be
在RAG系统中对FAISS,HNSW,BM25向量检索引擎选型的问题
文章摘要 本文探讨了企业内部AI Agent数量激增带来的通信难题,提出采用网关模式(Gateway Pattern)作为解决方案。通过统一入口集中管理Agent间的通信,解决点对点直连导致的复杂度爆炸问题。文章详细拆解了自建Agent网关的核心原理,包括认证机制、Agent注册与发现、请求路由、后端凭证隔离和限流策略,并基于PostgreSQL设计了一套完整的数据模型。作者强调自建网关的价值在于

文章摘要 本文探讨了企业内部AI Agent数量激增带来的通信难题,提出采用网关模式(Gateway Pattern)作为解决方案。通过统一入口集中管理Agent间的通信,解决点对点直连导致的复杂度爆炸问题。文章详细拆解了自建Agent网关的核心原理,包括认证机制、Agent注册与发现、请求路由、后端凭证隔离和限流策略,并基于PostgreSQL设计了一套完整的数据模型。作者强调自建网关的价值在于
Airflow 3.2.1 + AgentOperator 技术环境摘要 本文构建了一个基于Airflow 3.2.1的智能工作流编排系统,集成了AgentOperator、多种工具集(SQL/Hook/MCP)、MinIO对象存储和LiteLLM大语言模型代理。系统采用微服务架构,核心组件包括API Server、DAG Processor、Scheduler、Worker和Triggerer,