- @sikh_0529
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细介绍了如何利用Nanobot和vLLM构建智能QQ聊天机器人。Nanobot作为超轻量级AI智能体(仅4000行代码),结合vLLM的高效推理能力,可实现快速响应和多功能对话。教程涵盖从环境准备(推荐16GB+显存GPU)、星图AI部署Qwen3-4B模型、QQ机器人注册,到Nanobot安装配置的全流程。最终实现的机器人支持本地部署、多轮对话和功能扩展,为个人AI助手提供实用解决方案。文

【文章摘要】本文介绍了如何利用魔珐星云SDK快速开发具备具身交互能力的大模型数字人应用。文章首先指出传统文字输出Agent的局限性,强调低延迟、实时反馈和低成本对交互体验的重要性。随后详细展示了通过魔珐星云的AI端渲技术,将大模型输出转化为3D数字人的表情、动作和语音反馈的开发流程,包括SDK初始化、流式文本处理和中断控制等关键技术点。最后提供了一个完整的HTML示例代码,演示如何结合DeepSe

【文章摘要】本文介绍了如何利用魔珐星云SDK快速开发具备具身交互能力的大模型数字人应用。文章首先指出传统文字输出Agent的局限性,强调低延迟、实时反馈和低成本对交互体验的重要性。随后详细展示了通过魔珐星云的AI端渲技术,将大模型输出转化为3D数字人的表情、动作和语音反馈的开发流程,包括SDK初始化、流式文本处理和中断控制等关键技术点。最后提供了一个完整的HTML示例代码,演示如何结合DeepSe
机器学习基础【ML】
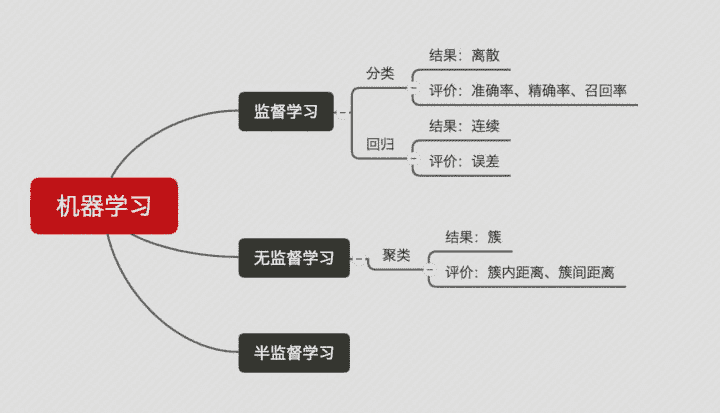
一般情况来说,单一评分标准无法完全评估一个机器学习模型。只用good和bad偏离真实场景去评估某个模型,都是一种欠妥的评估方式。下面介绍常用的分类模型和回归模型评估方法。分类模型常用评估方法:回归模型常用评估方法:在机器学习中,Bias(偏差),Error(误差),和Variance(方差)存在以下区别和联系:**对于Error **:误差(error):一般地,我们把学习器的实际预测输出与样
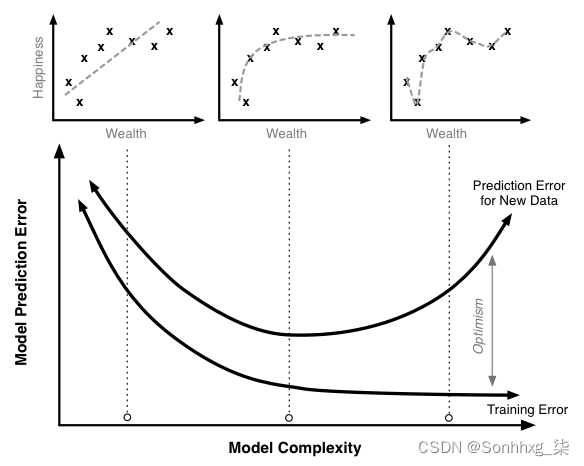
深度学习并没有想象的那么难,甚至比有些传统的机器学习更简单。所用到的数学知识也不需要特别的高深,本章将会一边讲解深度学习中的基本理论,一边通过动手使用PyTorch实现一些简单的理论,本章内容很多,所以只做一个简短的介绍。

这个算法是选取2个或者2个以上相似的样本(根据距离度量 distance measure),然后每次选择其中一个样本,并随机选择一定数量的邻居样本对选择的那个样本的一个属性增加噪声(每次只处理一个属性)。预测患有疝气病的马的存活问题,这里的数据包括368个样本和28个特征,疝气病是描述马胃肠痛的术语,然而,这种病并不一定源自马的胃肠问题,其他问题也可能引发疝气病,该数据集中包含了医院检测马疝气病的
随机初始化分布参数θE步,求Q函数,对于每一个i,计算根据上一次迭代的模型参数来计算出隐性变量的后验概率(其实就是隐性变量的期望),来作为隐藏变量的现估计值:M步,求使Q函数获得极大时的参数取值)将似然函数最大化以获得新的参数值然后循环重复2、3步直到收敛。详细的推导过程请参考文末的参考文献。
上图中左侧的蓝色大矩阵表示输入数据,在蓝色大矩阵上不断运动的绿色小矩阵叫做卷积核,每次卷积核运动到一个位置,它的每个元素就与其覆盖的输入数据对应元素相乘求积,然后再将整个卷积核内求积的结果累加,结果填注到右侧红色小矩阵中。卷积运算是有其严格的数学定义的。不过在 CNN 的应用中,卷积运算的形式是数学中卷积定义的一个特例,它的目的是提取输入的不同特征。对于这样的输入数据,第一层卷积层可能只能提取一些
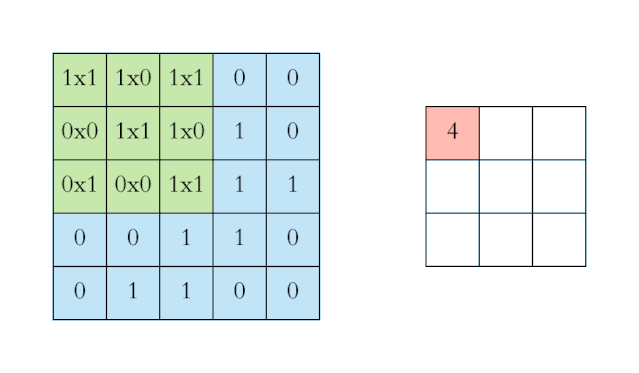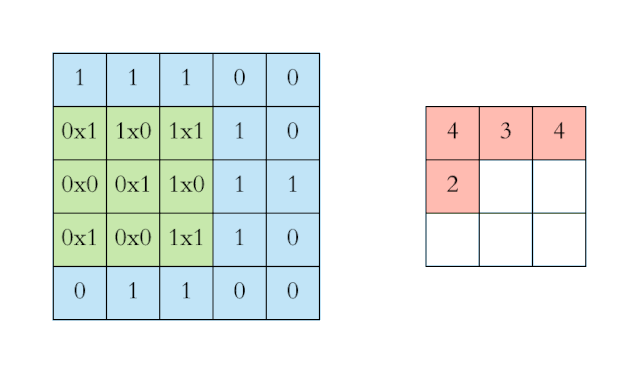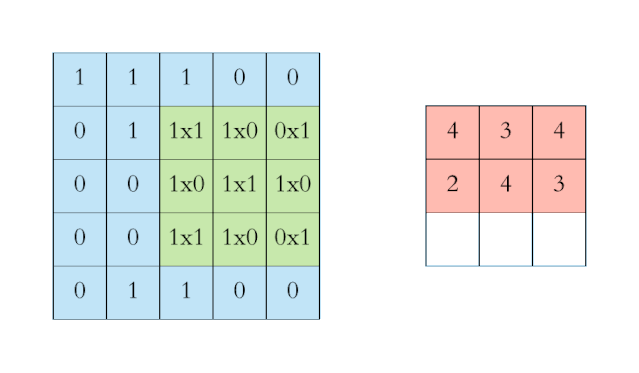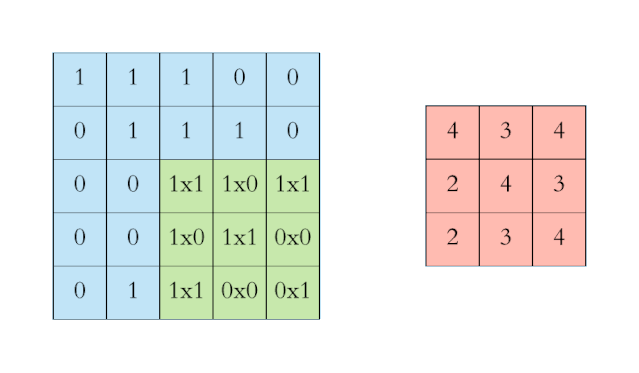
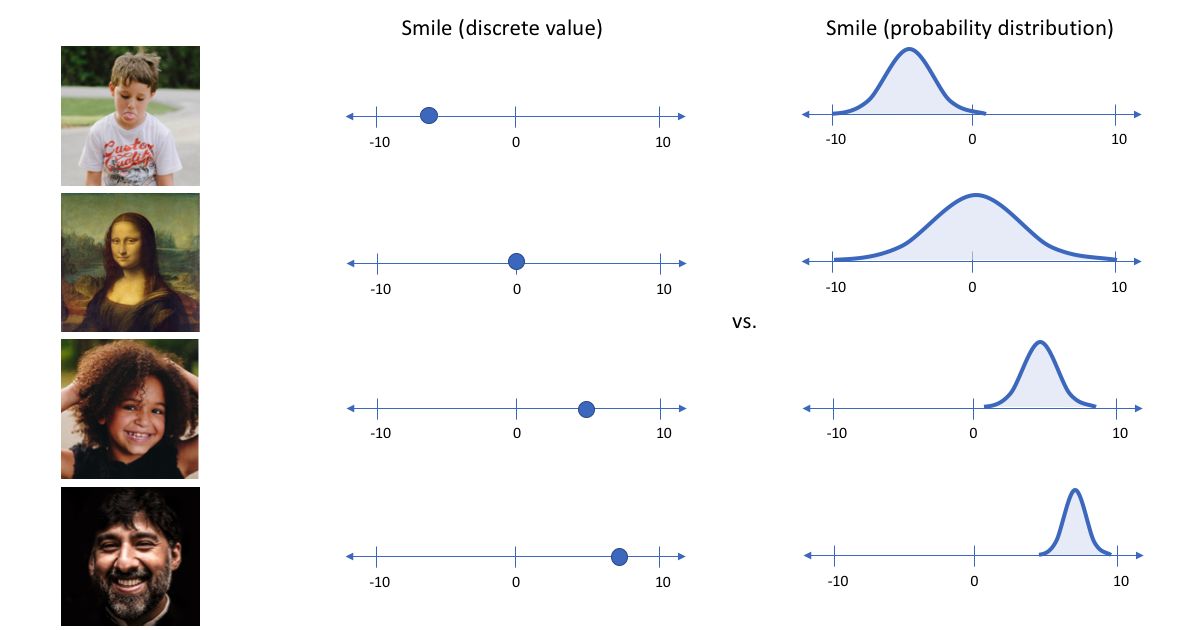
而变分自编码器便是用“取值的概率分布”代替原先的单值来描述对特征的观察的模型,如下图的右边部分所示,经过变分自编码器的编码,每张图片的微笑特征不再是自编码器中的单值而是一个概率分布。另一个根据生成的隐变量变分概率分布,还原生成原始数据的近似概率分布,称为生成网络。在上面的模型中,经过反复训练,我们的输入数据X最终被转化为一个编码向量X’, 其中X’的每个维度表示一些学到的关于数据的特征,而X’在每