




- @sherlockMa
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Qwen-Image是由阿里巴巴团队开发的200亿参数多模态图像基础模型,在复杂文本渲染和精准图像编辑方面取得突破性进展。该模型采用MMDiT架构,整合了多模态大语言模型Qwen2.5-VL和创新的变分自编码器,通过多阶段训练策略和严格的数据过滤流程,实现了卓越的生成能力。在公开基准测试中,Qwen-Image在文本到图像生成、中文文本渲染、图像编辑等任务上均达到SOTA水平,特别是在中文长文本处

机器学习》,又称西瓜书,是南京大学教授周志华教授编著的一本机器学习领域的经典教材。《机器学习》系统地介绍了机器学习的基本理论、常用算法及其应用。全书内容丰富,涵盖了机器学习的多个重要方面,包括监督学习、无监督学习、强化学习等主要学习范式。《机器学习》适合计算机科学、人工智能、数据科学等相关专业的本科生、研究生以及对机器学习感兴趣的自学者。无论是初学者希望系统地学习机器学习的基础知识,还是有一定基础

CosyVoice 2是由阿里巴巴集团开发的先进流式语音合成模型,它不仅继承了前代模型的优秀基因,更通过一系列创新性的技术优化,实现了在保持极低延迟的同时,生成质量几乎与人类发音无异的语音。CosyVoice 2模型的核心优势在于其能够提供接近人类发音自然度的合成语音。

在本研究中,作者引入了DeepSeekMath,这是一个特定于领域的语言模型,它的数学性能显著优于开源模型,在学术基准测试中接近GPT-4的性能水平。为了实现这一目标,作者创建了DeepSeekMath语料库,这是一个包含120 B个数学标记的大规模高质量预训练语料库。在初始迭代中,使用OpenWebMath中的实例来训练分类器作为正面例子,同时纳入了其他网页的多样化选择作为负面例子。随后,使用基

本文是《机器学习》(西瓜书)第六章支持向量机的详细解读。主要内容包括:1. 支持向量机的基本原理,介绍了最大间隔分类超平面的概念及其数学表达;2. 对偶问题的推导与求解方法,包括KKT条件和SMO算法;3. 核函数的作用与性质,如何通过核技巧解决非线性可分问题;4. 软间隔支持向量机,引入松弛变量处理噪声和异常点;5. 支持向量回归(SVR)的实现原理;6. 核方法在机器学习中的广泛应用。文章通过

百度ERNIE团队发布ERNIE4.5模型家族,包含10种多模态模型变体,涵盖47B和3B参数的MoE模型及424B总参数模型。该系列采用异构模态结构和模态隔离路由机制,支持跨模态参数共享,同时保持各模态独立性。模型在指令遵循、知识记忆、视觉理解等任务上达到SOTA性能。

Qwen3 代表了人类在通往通用人工智能(AGI)和超级人工智能(ASI)旅程中的一个重要里程碑。通过扩大预训练和强化学习的规模,之子实现了更高层次的智能。作者无缝集成了思考模式与非思考模式,为用户提供了灵活控制思考预算的能力。此外,作者还扩展了对多种语言的支持,帮助全球更多用户。

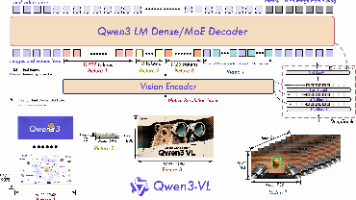
Qwen3-VL是阿里巴巴开发的新一代视觉语言模型,支持256K tokens的交错上下文处理,包含稠密型和混合专家型变体。其核心优势包括强大的文本理解能力、稳健的长上下文处理以及先进的多模态推理能力。模型通过增强型交错MRoPE、DeepStack集成和文本基视频时间对齐三大升级优化时空建模。训练采用四阶段预训练和SFT、知识蒸馏、RL后训练流程,在多模态任务中表现卓越。评估显示Qwen3-VL
《机器学习》,又称西瓜书,是南京大学教授周志华教授编著的一本机器学习领域的经典教材。在接下来的日子里,我将每周精心打磨一章内容,全方位、多角度地为大家剖析书中精髓。
字节跳动Seed团队提出GR-RL框架,解决了机器人长程精密操作难题。该框架通过强化学习增强的多阶段训练流程,将通用视觉-语言-动作模型转化为专家型政策,成功实现机器人自主系鞋带任务,成功率高达83.3%。GR-RL采用混合Transformer架构,包含策略网络和评论家网络,通过数据过滤、形态对称性增强和在线强化学习优化,有效解决了人类演示数据噪声、训练-部署不匹配等问题。实验表明,GR-RL在
