- @qq_64680177
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
使用: 使用mybatisplus自带的log-impl配置,使用log4j日志框架配置,使用P6spy插件这三种方法打印sql,分别介绍这三种方法的配置方法、应用场景和优缺点。
具体的验证过程,使用服务端的秘钥和指定的加密算法(如HS256)对Header和Payload进行验证签名,得到一个签名结果。此时看这个签名结果和前端传过来的token中的签名是否一样,如果一样就说明这个token是有效,并不是伪造的,此时要进行判断这个token是否过期,这个行为我们可以再创建token时就将其放入的redis当中,并给它设置过期时间。用户在以后的请求中都要将token放入请求当
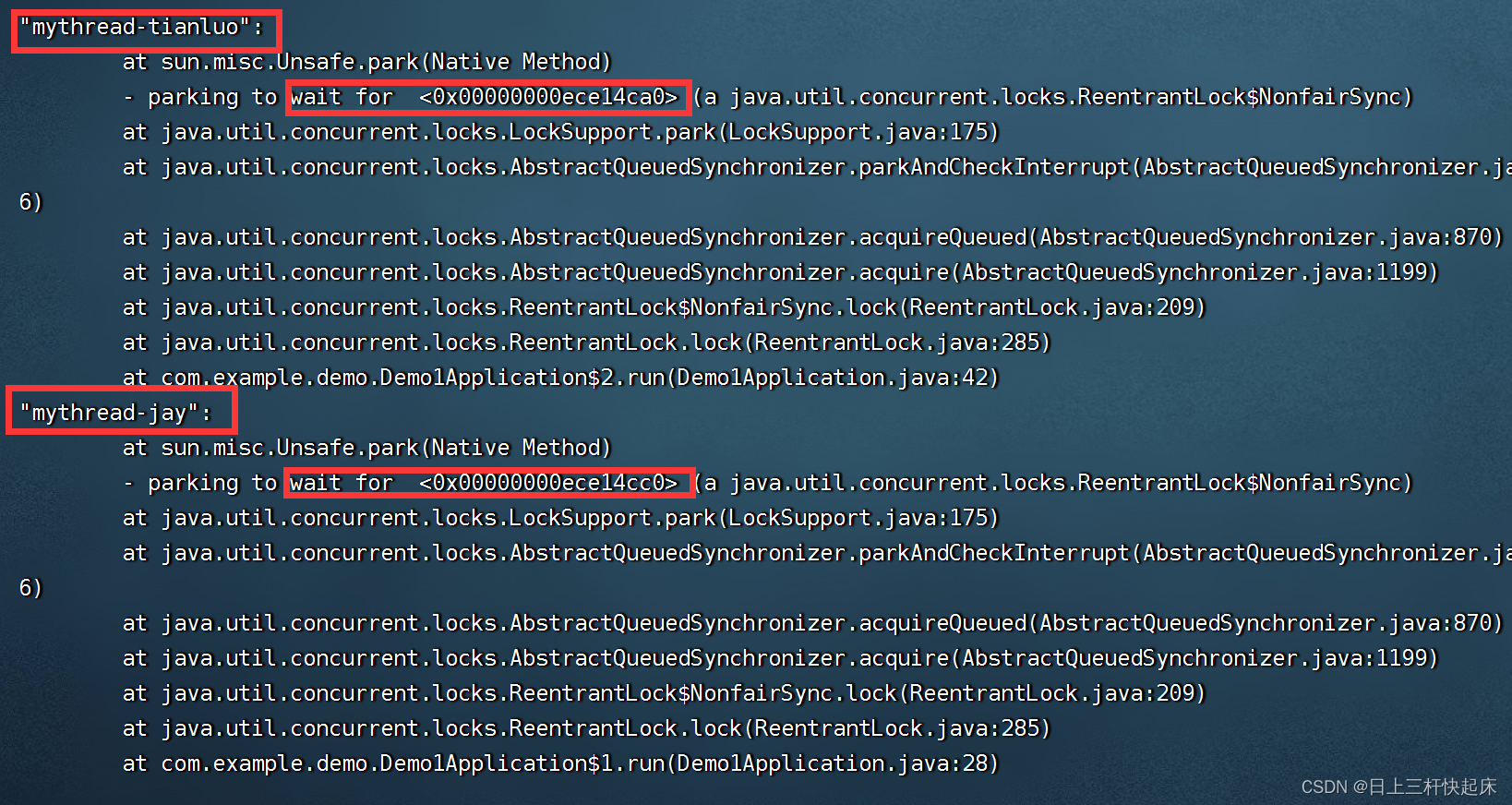
无论是再面试过程中还是再实际项目开发当中我们都有可能遇到这两个问题。我之前有同学面试这两个问题都有问道过。哈哈哈。所以我绝对把他们了解下并利用博客记录。JStack可以显示Java应用程序中每个线程的堆栈跟踪,帮助开发人员诊断线程相关的问题,比如死锁和性能问题。通过使用JStack,开发人员可以查看线程的状态、锁定信息以及线程调用堆栈,从而更好地理解应用程序的运行状况。命令介绍:jstack -F
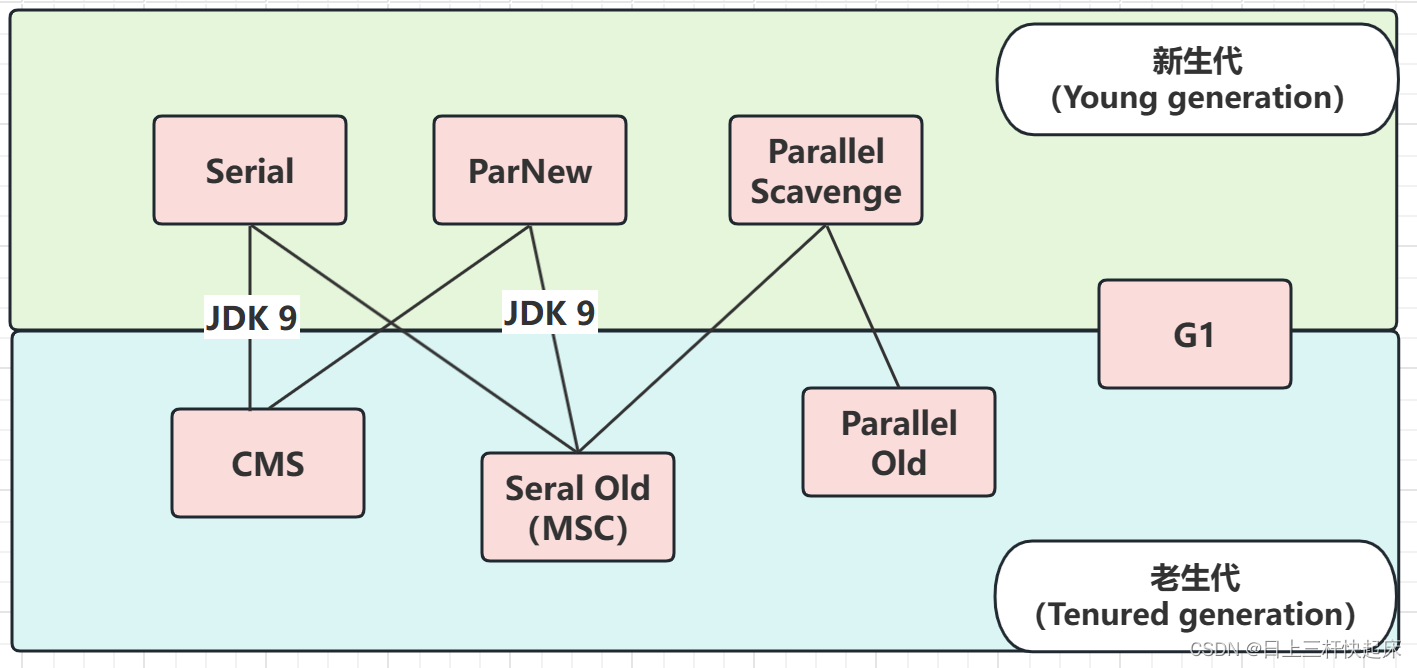
CMS(Concurrent Mark Sweep)收集器是以获取最短回收停顿时间的为目标的收集器。注重服务的响应速度,希望系统停顿时间尽可能短,以给用户更好的交互体验。这个收集器是基于标记清除算法实现的。用于老年代的收集。收集过程有四个阶段:1、初始标记2、并发标记3、重新标记4、并发清除四个阶段中初始标记和重新标记仍需要暂停所有的用户线程(Stop The World),但为什么说这个收集器也
1.7:数组+链表 (由于是链表长度长了。查询效率不高。所以在设计初衷1.7的hash算法更复杂。数据也更散列)1.8:数组+链表+红黑树(JDK8中即使用了单向链表,也使用了双向链表,双向链表主要是为了红黑树相关链表操作方便,应该在插入,扩容,链表转红黑树,红黑树转链表的过程中都要操作链表),HashMap的扩容是通过调用resize()方法实现的。java1.8+在扩容时,不需要重新计算元素的
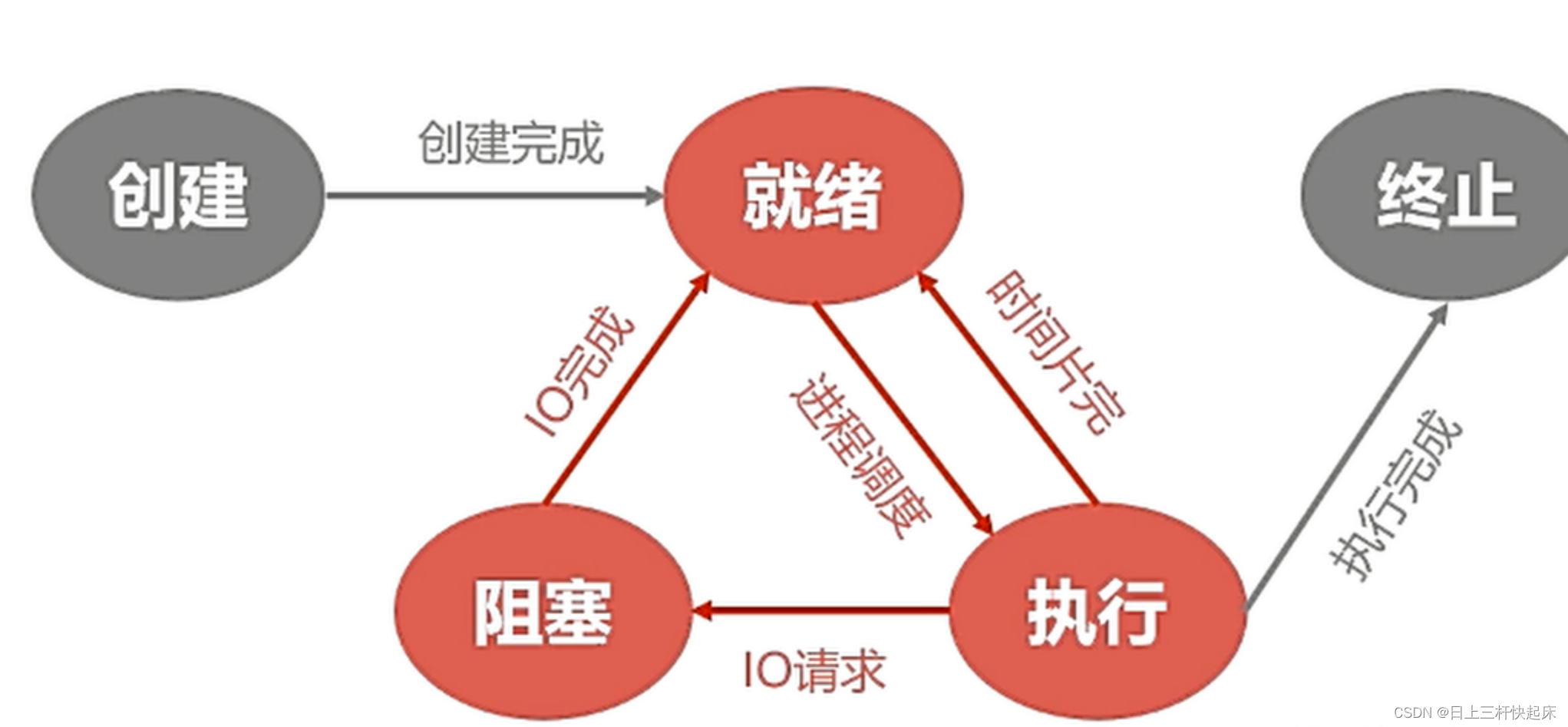
时间片轮转调度算法(RR):这的基本思想是将CPU的时间分割成若干个小的时间段,称为时间片,将这个时间片分给每一个进程,在这段时间内这个进程会在CPU中执行在这个法 中有两种情况程序会让出CPU:当时间片用完了之后这个进程的程序还没有执行完毕,则会让出CPU重新进入就绪队列等待被选中,CPU会继续从就绪队列中选择下一个进程执行。当时间片还没用完,程序发生阻塞或者执行完毕,也会立即让出CPU。在这
java虚拟机再执行Java程序的时候把它所拥有的内存区域划分了若干个数据区域。这些区域有着不同的功能,各司其职。这些区域不但功能不同,创建、销毁时间也不同。有些区域为线程私有,如:每个线程都有自己的程序计数器,则程序计数器随着用户线程创建而创建,随其销毁而销毁。而有些区域是所有线程共有的,如堆是被所有线程所共有的。根据《java虚拟机规范》的规定,java虚拟机所管理的内存将会包括以下几个运行时

JVM(Java Virtual Machine,Java虚拟机): JVM是Java程序运行的环境,它是Java平台的核心组成部分。JRE(Java Runtime Environment,Java运行时环境): JRE是Java应用程序的运行时环境,它包含了JVM以及Java基础类库和所需的运行时资源。JDK提供了开发Java应用程序所需的一切,包括编译、调试、文档生成、性能分析等工具。简而言

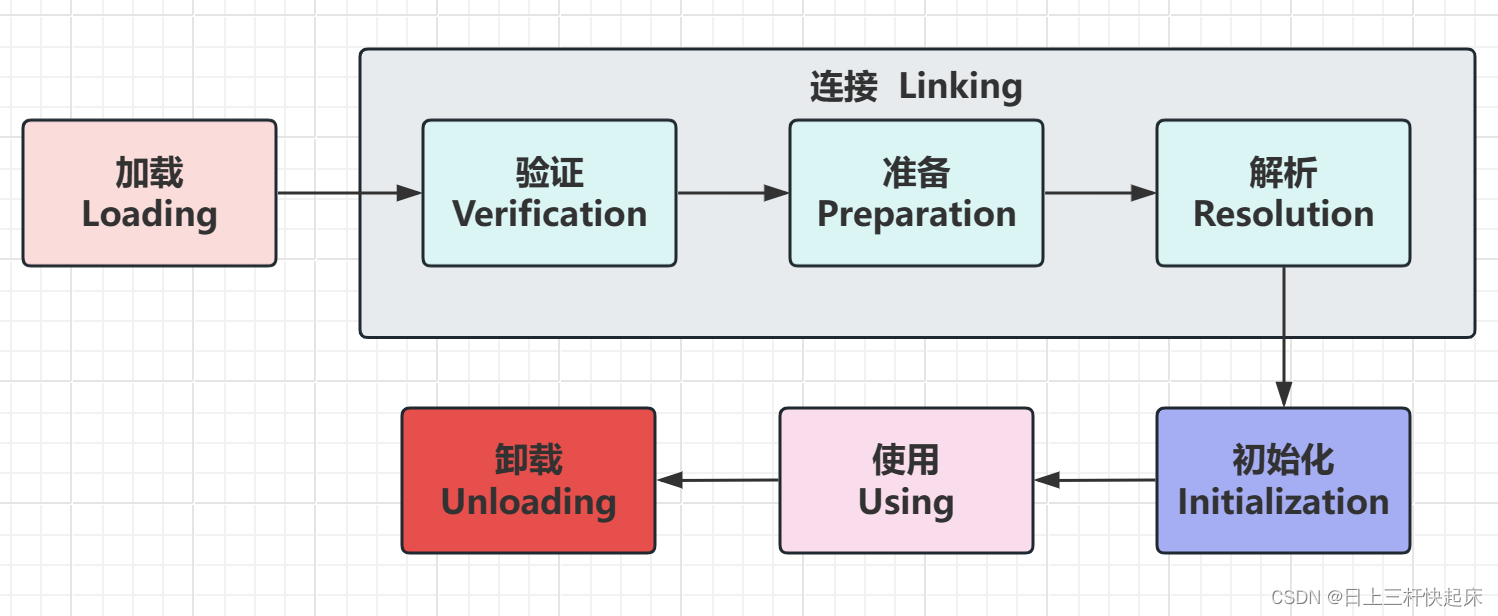
就是将 java的字节码文件(.Class)文件加载到内存当中,然后在方法区当中根据这个文件构建这个类的类模型,这个类包含了从字节码文件中解析出来的常量池、类方法、等信息。初始化阶段是类加载的最后一个步骤,再之前的加载阶段中处理加载阶段可以用用户子自定义类加载器的方式参与,其他时候都是由JVM自己主导控制的,到了初始化阶段才正式的使用我们自己写的java代码了,再这个阶段有一个执行类构造器方法需要