




- @qq_63432403
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。在AI大模型中,Prompt的作用主要是给AI模型提示输入信息的上下文和输入模型的参数信息。在使用大语言模型时,总会看到token一词,调用大模型api是根据token的使用数进行付费。与当前的人工智能(AI)相比,AGI 不是专门针对某个任务(如语言生成、图像识别),而是具备。大模型(Large Model)是指

在“无监督学习”中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础,较为经典的是聚类。**聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”。**聚类既能作为一个单独过程,用于找寻数据内在的分布结构,也可以作为分类等其他学习任务的前驱过程。距离计算:pu1∑n∣xiu−xju∣p无序属性:VDM

贝叶斯决策论是概率框架下实施决策的基本方法,对分类任务来说,在所有相关概率都已知的理想情形下,贝叶斯决策论考虑如何基于这些概率和误判损失来选择最优的类别标记。贝叶斯决策论通过结合先验知识和观测数据,使用贝叶斯定理计算后验概率,从而做出最优决策。但是对于类条件概率P(x|c)来说,涉及了关于x所有属性的联合概率,因此很难进行估计。,当训练集包含充足的独立同分布样本时,P©可以通过各类样本所占的比例来

在c和c++的配置命令栏中增加。找到右下角管理,点击扩展。插件,打开扩展设置。
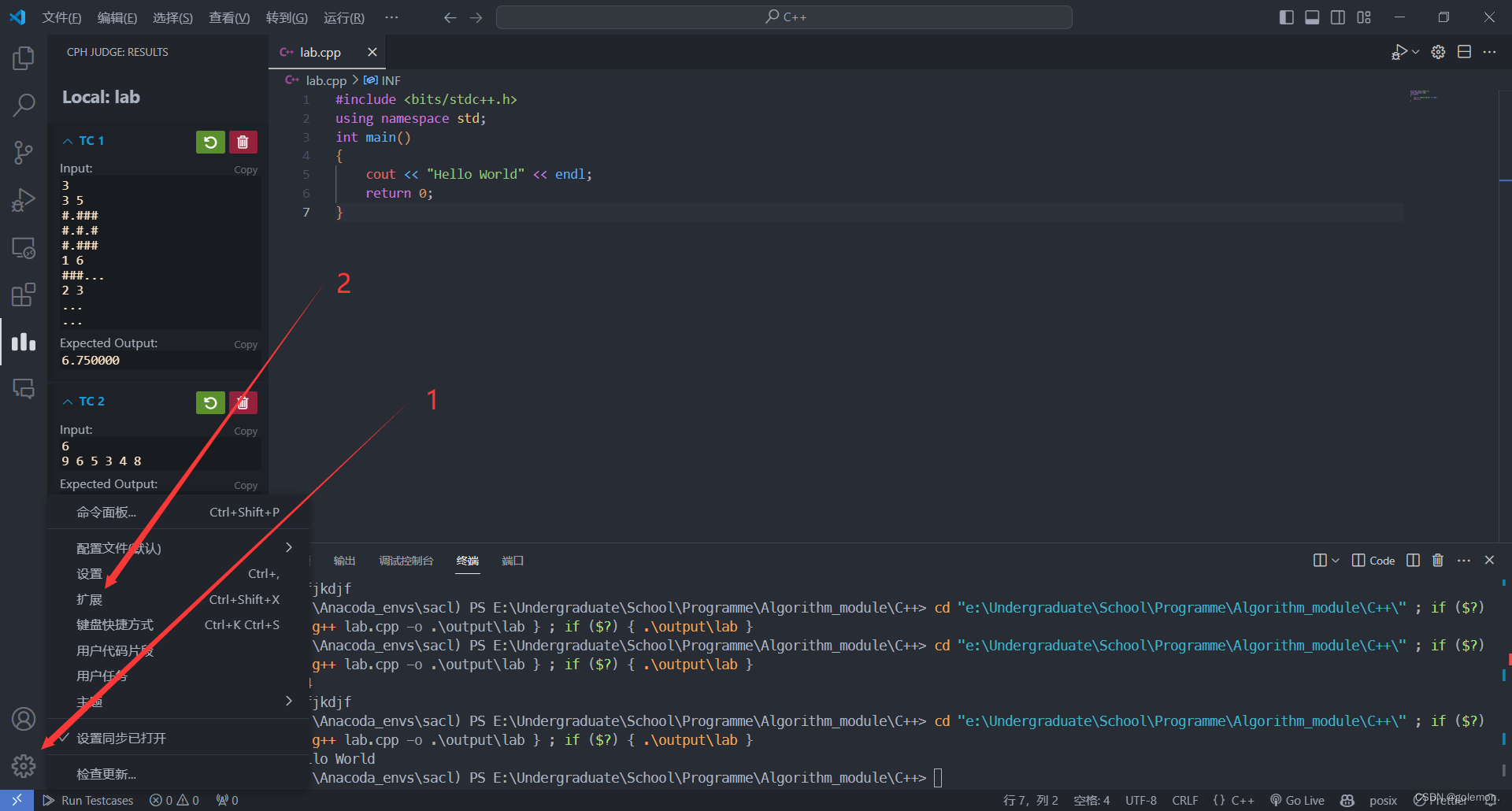
使用vscode的插件remote-ssh进行linux的远程控制。在vscode上安装完remote-ssh插件后,还需要安装openssh-client。
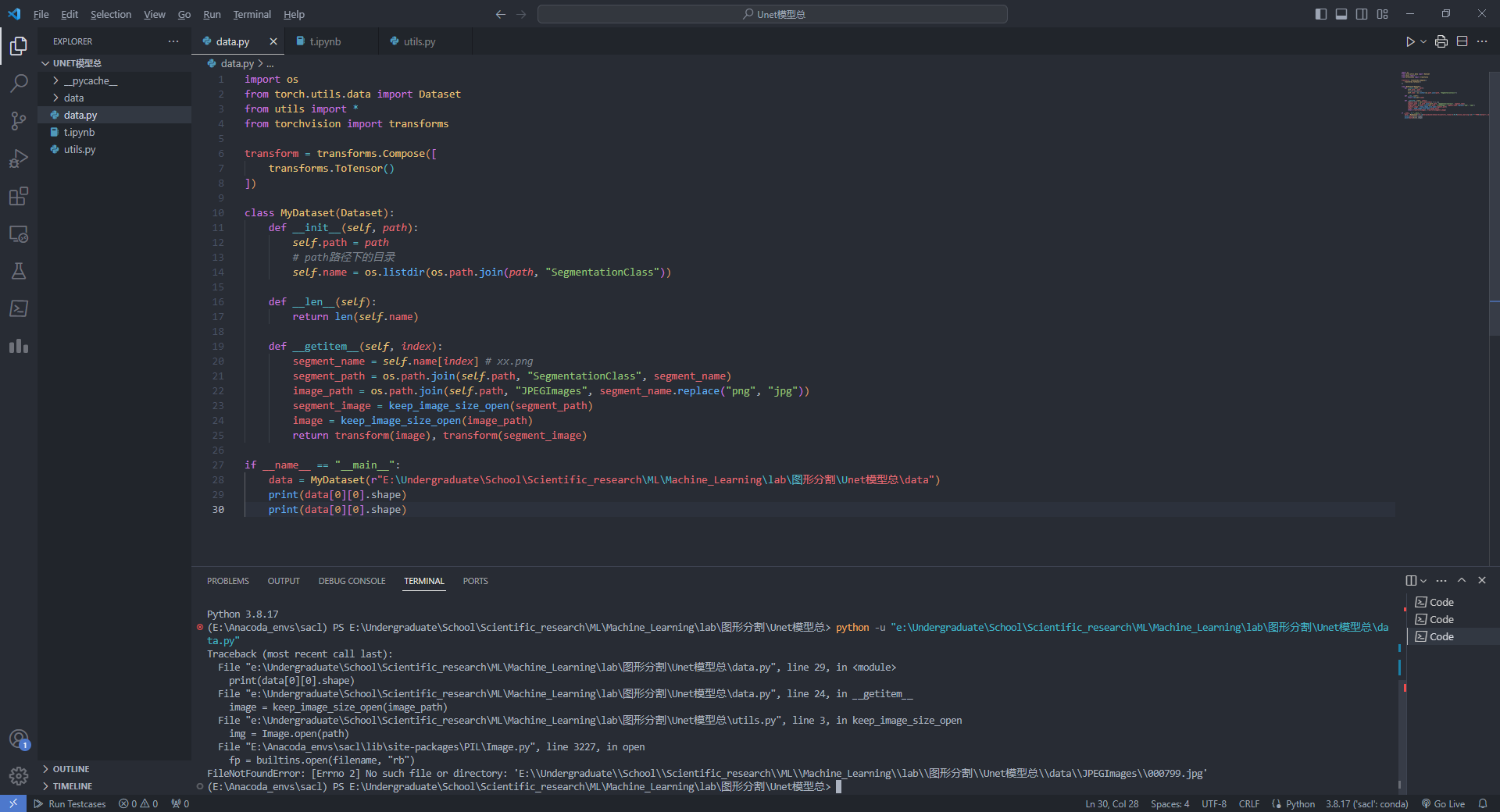
今天,想着将之前鸽的Unet网络模型给实现一下,结果发现,在vscode中运行python脚本,显示没有这包,没有那包。但是在其他的ipynb中是有的,感觉很奇怪。我检查了一下python版本,发现不是我深度学习的python3.8版本,而是默认的3.10。然后我想在vscode的终端中显式的调用conda虚拟环境中的python,但是conda命令却用不了。经过一顿分析和搜索,终于找到了原因:v
强化学习(Reinforcement Learning, RL)是一种机器学习方法,旨在通过与环境交互,使智能体(Agent)学习如何采取最优行动,以最大化某种累积奖励。它与监督学习和无监督学习不同,强调试错探索(Exploration-Exploitation)以及基于奖励信号的学习。强化学习任务通常用马尔可夫决策过程来描述:机器处于环境E中,状态空间X,其中每个状态x∈X是机器感知到的环境的描

但是官网上是全局安装,这里提供一个非全局安装的。在非全局中,不能在命令行直接使用。显示了版本号就表明安装成功了。模型还是比较容易的,根据官网。目前使用没有遇到权限问题(使用下面命令安装(少了。
用C++11特有的特性进行测试,看是否成功。
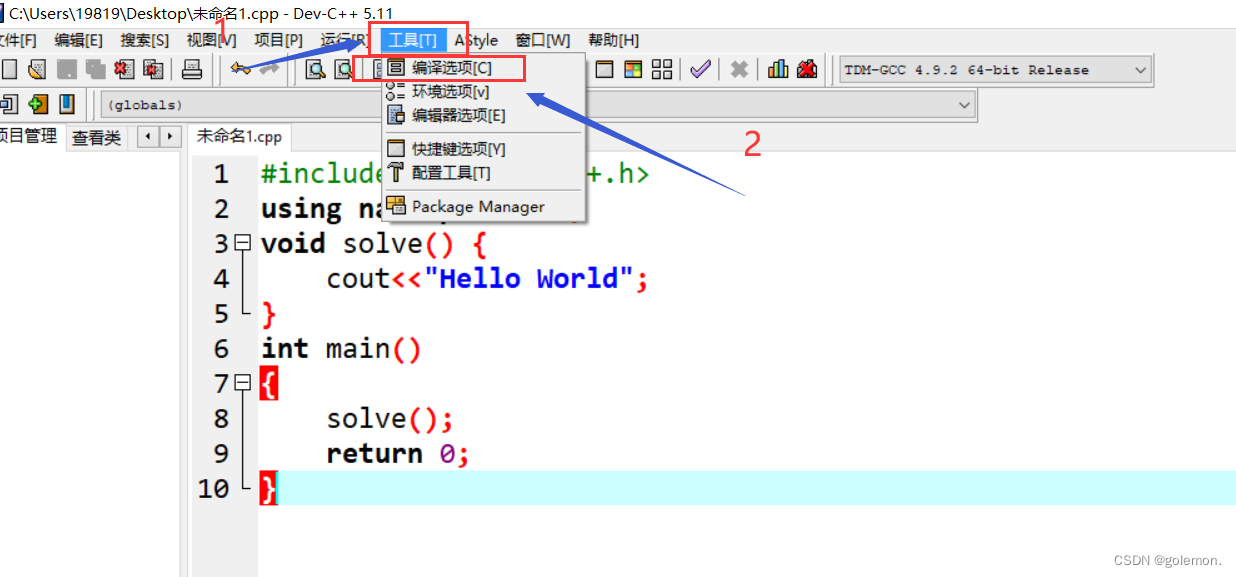
将要导入的插件文本位置与终端位置一致。
