




- @qq_45467608
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
以notebook的形式呈现,支持多节点代码执行和文件管理,同时执行运行状态追踪功能,极大地提升开发者的效率和工作体验。我们通过docker来启动secretflow,这里我安装的是secretflow/secretflow-lite-anolis8。这里我是用docker来进行集群模式的仿真,所以我需要了解一下docker网络的概念。在这里我采用的是Host网络模式,该模式下容器和docker主
又是谁在何时报告了某个功能缺陷等等。

假设如果’A’和’B’在不同的网络上,主机’A’可能有或可能没有公共IP地址,但主机’B’一定有一个公共IP地址。这段代码是一个简单的基于libp2p的P2P聊天应用程序的示例。它允许两个节点通过P2P连接进行聊天。

又是谁在何时报告了某个功能缺陷等等。
数据定义语言(Data Definition Language,DDL)是 SQL 语言集中负责数据结构定义与数据库对象定义的语言。DDL 的主要功能是定义数据库对象。DDL 的核心指令是。
第 1代 P2P 文件网络需要中央数据库协调,例如在 2000年前后风靡一时的音乐文件分享系统 Napster。在 Napster中,使用一个中心服务器接收所有的查询,服务器会向客户端返回其所需要的数据地址列表。这样的设计容易导致单点失效,甚至导致整个网络瘫痪。

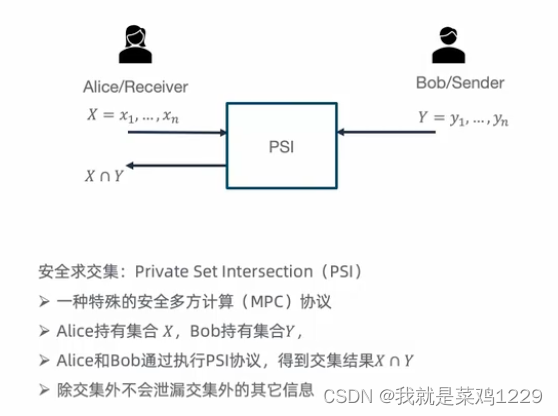
定义:PSI(Private Set Intersection)是一种协议,用于比较两个私有集合的元素,并在不泄露集合成员身份的情况下确定两个集合的交集。
源码里一共包含了5个py文件单机模型(Normal_ResNet_HAM10000.py)联邦模型(FL_ResNet_HAM10000.py)本地模拟的SFLV1(SFLV1_ResNet_HAM10000.py)网络socket下的SFLV2(SFLV2_ResNet_HAM10000.py)使用了DP+PixelDP隐私技术(SL_ResNet_HAM10000.py)使用的数据集是:HAM
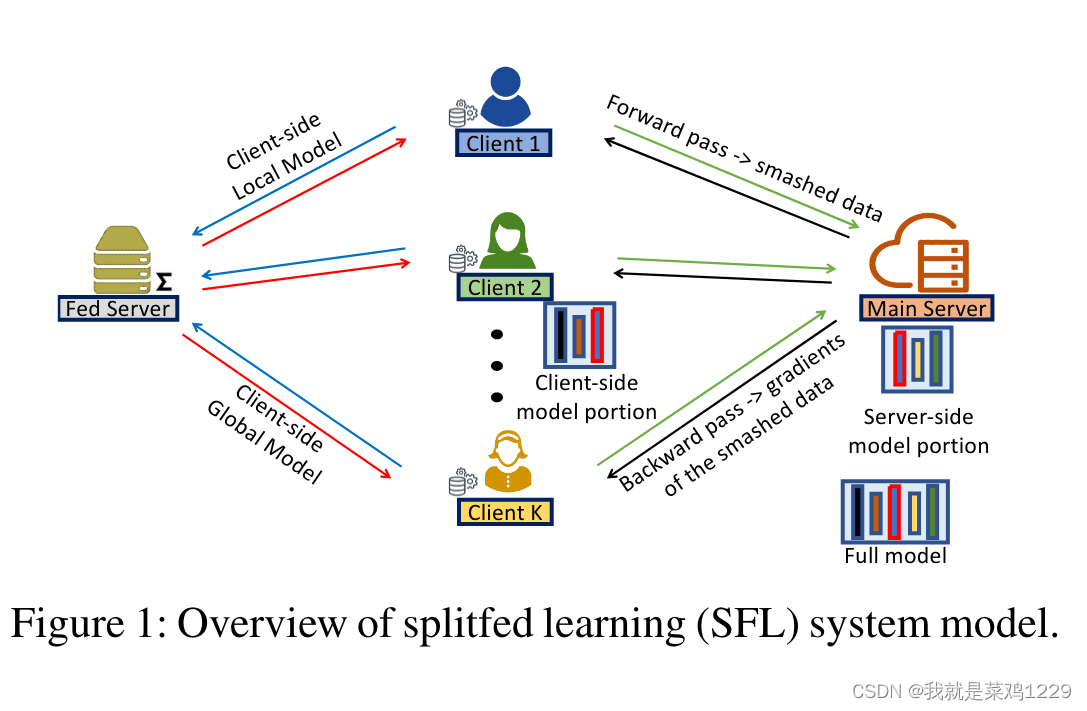
出自—联邦学习综述:概念、技术、应用与挑战 梁天恺 1*,曾 碧 2,陈 光 1。

本文提出了一种基于公平性的联邦学习激励机制(FedFAIM)。
