




- @qq_43629945
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Excel(第三周)
PCA(主成分分析)、LDA(线性判别分析);熵与信息增益;离群点和异常点、LOF方法进行离群点检测;数据类型转换、采样、可视化等等

数据挖掘的一些基本概念、学习资源;什么是数据、信息、知识、决策;大数据、云计算、商务智能BI;分类、聚类、关联规则、回归;数据预处理、过学习、交叉验证、混淆矩阵、ROC曲线、AUC、Cost Sensitive Learning、Lift Analysis;隐私保护与并行计算;幸存者偏差...

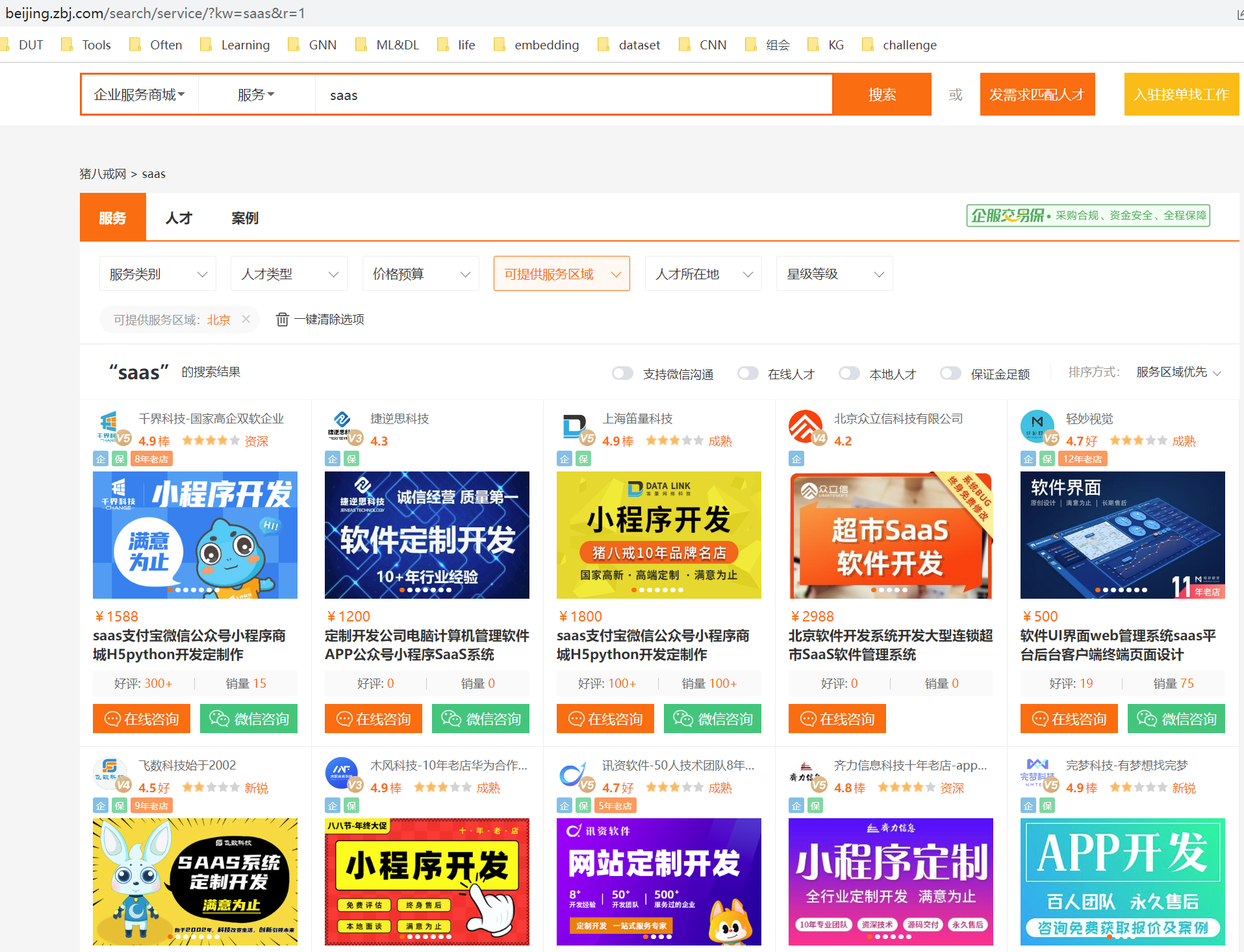
xpath案例之爬取猪八戒网信息
查看CUDA版本的几个命令及区别:nvidia-smi、nvcc -V、print(torch.version.cuda)、print(torch.utils.cpp_extension.CUDA_HOME)。如何配置版本兼容的cuda和pytorch
10-11集(CNN)内容:卷积神经网络(基础篇、高级篇)
sklearn中的降维算法(模块decomposition);PCA 及重要参数n_components;鸢尾花数据集可视化;SVD及重要参数svd_solver、random_state;重要属性components_;重要接口inverse_transform;人脸识别数据集的案例
前9集内容:Overview、线性模型、梯度下降算法、反向传播、用PyTorch实现线性回归、逻辑斯蒂回归、处理多维特征的输入、加载数据集、多分类问题
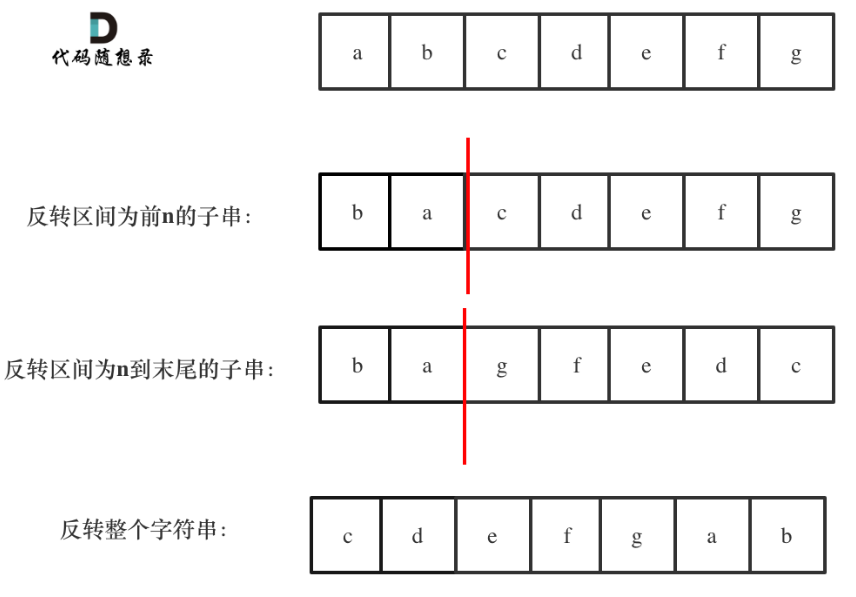
双指针法(反转字符串);使用整体反转+局部反转就可以实现反转单词顺序的目的;KMP算法(解决两类问题:匹配问题&重复子串问题)
前9集内容:Overview、线性模型、梯度下降算法、反向传播、用PyTorch实现线性回归、逻辑斯蒂回归、处理多维特征的输入、加载数据集、多分类问题