




- @qq_41915623
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Feather:最快的读写速度,适合跨语言高效传输。Parquet:高效的列式存储与压缩,适合大规模数据分析。HDF5 (.h5):强大的数据管理能力,适用于科学计算和工程应用。NPZ (.npz):专为NumPy数组优化,适合数值计算任务。:灵活的Python对象序列化,适合内部数据持久化。:嵌入式数据库,适合需要SQL查询的小型应用。:灵活的文本格式,适合嵌套数据和配置文件。CSV (.csv

(1)Kotlin语法简洁,同样功能,kotlin可能会比java减少50%的代码量;(2)语法更加高级,使开发效率提升;(3)kotlin在语言安全性上下了工夫,几乎杜绝了空指针这个全球崩溃率最高的异常;(4)与Java100%兼容,使得Kotlin可以直接调用Java编写的代码,可以无缝使用Java三方库。注:在线kotlin编程网址https://try.kotlinlang.org(1)v
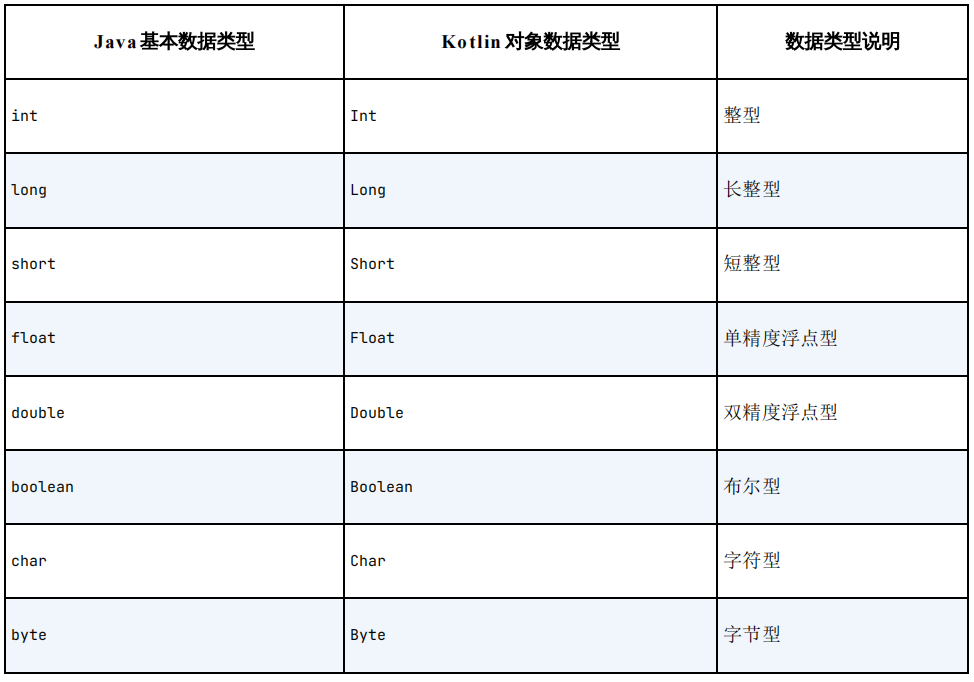
很早绘制的一些模型图,当时放在CSDN的草稿里,今天发现了,把它分享出来吧,还能更清晰的帮助理解!
本文对比了三大分布式SQL引擎Hive、Trino和SparkSQL的核心差异。Hive作为最早的SQL-on-Hadoop工具,适合离线批处理和元数据管理;Trino采用MPP架构,支持多数据源联邦查询,延迟极低;SparkSQL则与Spark框架深度集成,擅长批流一体的ETL和机器学习任务。在性能上,Trino适合实时查询,SparkSQL适合大规模计算,Hive稳定性强但速度较慢。建议根据具
文章目录说明1. batch和batch_size2. step、iteration、epoch说明全部基于自己的实践理解,如有不对之处,欢迎在评论区指出。1. batch和batch_size还是以例子进行解释吧,假设我们有2000个数据样本,设batch_size = 100,则 batch = 2000/100 = 20.注:batch_size 一般取32,64,128等2的N次方,bat
一、问题描述在idea中,导入依赖时,有时会出现这种导入不进来的情况,让人非常难受。即时"reimport", 删除缓存后重启也没什么用。二、解决办法Step1: 去maven依赖下载地址这个网站下载需要的jar包。例如:我这里需要的是swagger的包Step2: 如果配置了maven的路径,就随便哪里打开命令行(如果没有配置路径,就去安装maven的bin路径打开命令行)。运行代码:mvn i
Wide & Deep是由谷歌APP Stroe团队在2016年提出的关于CTR预测的经典模型,该模型实现简单,效果却非常好,因而在各大公司中得到了广泛应用,是推荐系统领域的经典模型!团队:Google APP Store发表时间:2016年。
算法面试合集:transformer、Swin-T, Wide&Deep等等

激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。在神经元中,输入的input经过一系列加权求和后作用于另一个函数,这个函数就是这里的激活函数。
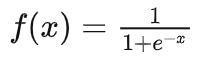
1. 说明本系列博客记录B站课程《PyTorch深度学习实践》的实践代码课程链接请点我2. Pytorch写代码的一般逻辑3. 代码# ---------------------------# @Time: 2022/4/12 18:17# @Author: lcq# @File: Logistic_Regression.py# @Function : PyTorch实现Logistic回归# -
