




- @qq_40728667
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
(深度学习模型可能提取到一些人类不易察觉的特征,这些特征可能对结果的判定有着较大的贡献。可以把HOG特征的结果作为额外的一个Channel加入数据中让深度学习模型学习。如果仅仅给网络提供人工提取的特征,反而有可能会造成网络性能的下降。但是这种额外的工作对于模型来说不一定有很大的提高。1.略微提高2.略微降低。
HengkaiGuo的回答-知乎https//www.zhihu.com/question/306213462/answer/562776112。对于神经网络中输入的两路特征图,如果通道数相同,则add融合方式等价于concate之后对应通道共享同一个卷积核。使用add融合方式相当于为网络提供了一种先验两路输入的特征图中对应通道的语义特征类似。可以看出,使用add融合方式可以避免不同通道间语义信息
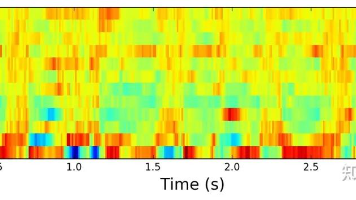
语音特征提取经历了从传统方法到自监督学习的演进。传统MFCC等特征基于听觉模型但表达能力有限。2019年Wav2Vec首次实现音频自监督学习,2020年Wav2Vec2.0引入Transformer和向量量化,通过掩码预测任务显著提升性能,推动了无监督语音表征的发展,在LibriSpeech等基准上取得突破。这些方法突破了对文本标注的依赖,实现了更强大的语音特征学习能力。
这一类接口虽然标识是这样的,但是大部分都是可以一口多用的,目前大多数主板都有自定义接口功能,无论插入哪个口,声卡驱动都会弹窗提醒。3.5mm接口输出的音频都是经过主板的集成声卡得到的模拟信号。一般情况下,后置输入输出端口面板中,大多数的主板音频部分是彩色的。而在定制化主板统一颜色的音频接口中,一般都会有专门突出的音频输出接口,但也可以通过接口旁的文字标识来辨别接口的功能。目前,大部分的新主板都采用

HengkaiGuo的回答-知乎https//www.zhihu.com/question/306213462/answer/562776112。对于神经网络中输入的两路特征图,如果通道数相同,则add融合方式等价于concate之后对应通道共享同一个卷积核。使用add融合方式相当于为网络提供了一种先验两路输入的特征图中对应通道的语义特征类似。可以看出,使用add融合方式可以避免不同通道间语义信息
(深度学习模型可能提取到一些人类不易察觉的特征,这些特征可能对结果的判定有着较大的贡献。可以把HOG特征的结果作为额外的一个Channel加入数据中让深度学习模型学习。如果仅仅给网络提供人工提取的特征,反而有可能会造成网络性能的下降。但是这种额外的工作对于模型来说不一定有很大的提高。1.略微提高2.略微降低。
因此,除了软件外,在硬件也上会下功夫,比如使用推理专用的NVIDIA T4、寒武纪MLU100等。相较于桌面级显卡,这些推理卡功耗低,单位能耗下计算效率更高,且硬件结构更适合高吞吐量的情况。软件上,一般部署时都不会直接上深度学习框架。OpenCV、OpenVINO都是intel的开源框架库,OpenCV的DNN模块其实调用的也就是OpenVINO,另外OpenvVINO在硬件加速方面使用了Inte
数据科学仅当能促进对数据的合理解读时才能被称为科学。深度学习调参的技巧:寻找合适的学习率。作为一个非常重要的参数,学习率面对不同规模、不同batch-size、不同优化方式和不同数据集,它的最合适值都是不确定的。我们唯一可以做的,就是在训练中不断寻找最合适当前状态的学习率;权重初始化。相比于其他的Trick来说使用并不是很频繁。只有那些没有预训练模型的领域才会自己初始化权重,或者在模型中去初始化神
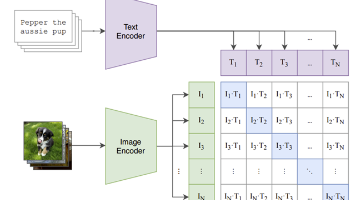
CLIP是OpenAI推出的革命性人工智能模型,通过对比学习4亿个图像-文本配对数据,实现了图像与语言的深度融合。其核心创新在于双编码器架构(图像编码器和文本编码器),将视觉和文本信息映射到共享嵌入空间。CLIP的最大突破是零样本学习能力,无需特定任务训练即可完成图像分类等任务。该技术已应用于DALL-E图像生成、智能搜索、内容审核等领域,但存在细节识别不足、计数困难等局限性。CLIP代表了AI多
语音特征提取经历了从传统方法到自监督学习的演进。传统MFCC等特征基于听觉模型但表达能力有限。2019年Wav2Vec首次实现音频自监督学习,2020年Wav2Vec2.0引入Transformer和向量量化,通过掩码预测任务显著提升性能,推动了无监督语音表征的发展,在LibriSpeech等基准上取得突破。这些方法突破了对文本标注的依赖,实现了更强大的语音特征学习能力。