




- @qq_40243750
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
伪装目标检测(Camouflaged Object Detection, COD)是一项计算机视觉任务,旨在识别和分割背景中难以察觉的目标,如动物伪装、隐形物体检测等。由于伪装目标通常与背景高度相似,这项任务比传统的目标检测更具挑战性。伪装目标检测是一个极具挑战性的计算机视觉任务,广泛应用于生态保护、军事隐身目标检测、医学影像等领域。深度学习技术的进步使得 COD 取得了显著提升,但仍然存在泛化能

在之前的文章中,我们已经探讨了如何使用TensorRT加速YOLOv5模型的推理过程。如果你已经掌握了这些基础知识,那么现在是时候更进一步了!本文将带你深入实战,从零开始,一步步部署一个属于你自己的目标检测项目。无论你是刚入门深度学习,还是已经有一定经验的开发者,本文都将为你提供清晰的指引。我们将覆盖从数据标注与整理、模型训练、模型导出,到TensorRT序列化和部署推理的完整流程。通过这个项目,
TensorRT(NVIDIA TensorRT)是 NVIDIA 提供的一款高性能深度学习部署推理优化库,专门用于加速在 NVIDIA GPU 上运行的深度学习模型。它提供了一系列优化手段,如运算融合(Layer Fusion)、精度校准(Precision Calibration)、张量优化(Tensor Optimization)等,能够显著提升模型推理速度,并降低延迟。
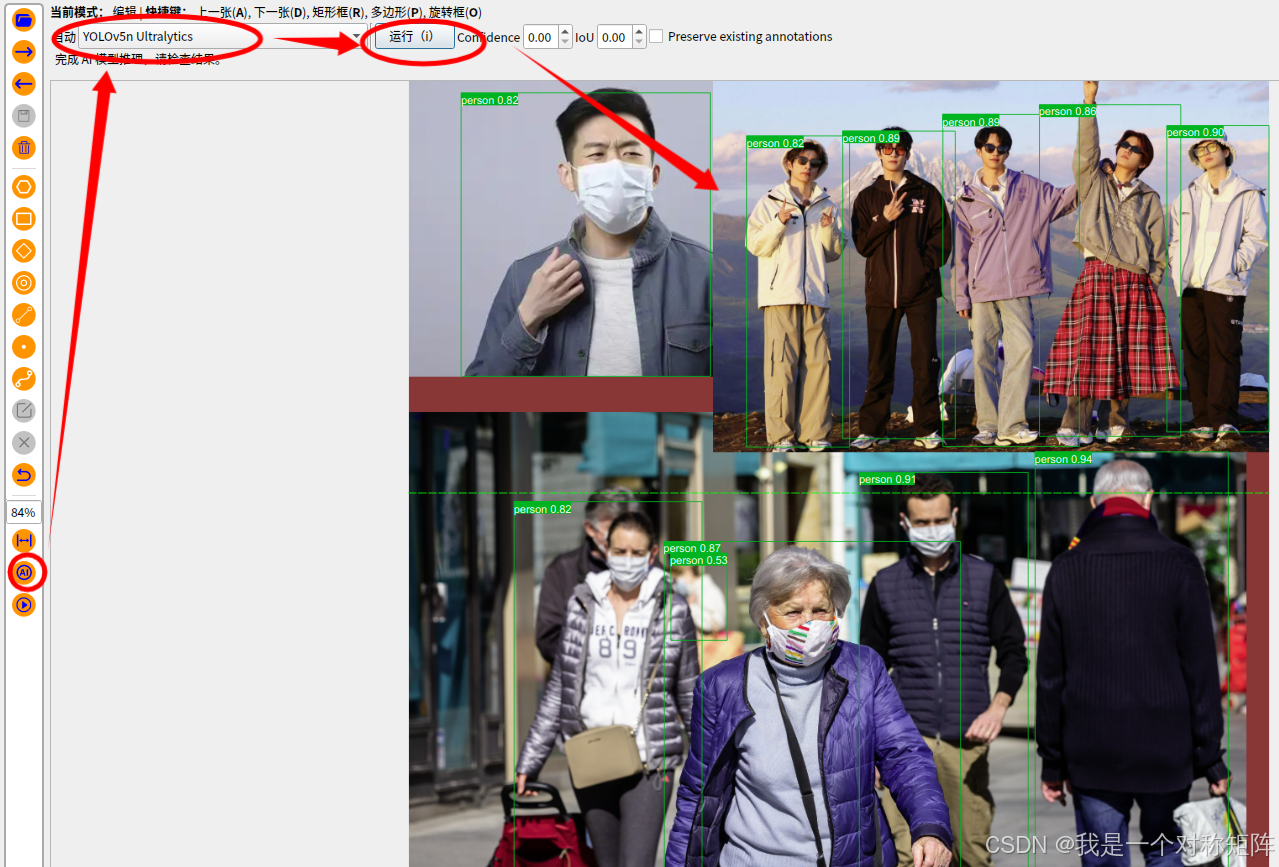
0. 效果展示这是GitHub项目地址偷了几张项目中的展示图感受下,要是喜欢这个风格,就继续往下看:1. 使用该项目我只在Ubuntu18成功运行过,Windows试过没有成功。1.1 克隆项目到本地1.2 安装相关ubuntu 16.04sudo apt-get install texlive-latex-extraubuntu 18.04sudo apt-get install texlive
随着ChatGPT的火热,科技公司们各显神通,针对大语言模型LLM通常需要极大的算力支持,且没有开源,阻碍了进一步的研究和应用落地。受 Meta LLaMA 和 Stanford Alpaca 项目的启发,来自加州大学伯克利分校、CMU、斯坦福大学和加州大学圣地亚哥分校的成员,共同推出了一个 Vicuna-13B 开源大模型。本文将尝试在3090上运行Vicuna-7B模型。
1、介绍pyqt5中的交互框有很多种,先介绍我用到的,后续有用到的再慢慢补充2、文件选择框:QFileDialog通过以下代码实现:imgName, imgType = QFileDialog.getOpenFileName(parent=None, caption="打开图片", directory="", filter="*.jpg;;*.png;;All Files(*)")paramete
[1]章国锋. 商汤科技:面向增强现实的视觉定位技术的创新突破与应用[J]. 杭州科技, 2019(6):4.1、引入2、挑战3、SenseAR的关键技术3.1、稀疏点云地图构建3.2、精准定位4、一些应用4.1《王者荣耀》AR相机4.2、AR测量5、发展趋势1、引入“增强显示”(AR)是一种将虚拟虚拟警务或信息无缝融入现实环境的技术。定位于地图构建技术(SLAM)可以在未知环境中定位自身方位并构

0. 前言本文是基于知乎文章Android TensorFlow Lite实时人脸识别而写,本文更像是对知乎文章的观后总结,感兴趣可以阅读原文。本文要完成一个离线的人脸识别应用,涉及到人脸检测和人脸识别两项主要技术。1. 技术选择1.1 人脸检测人脸检测直接使用ML Kit,这是一个旨在Machine learning for mobile developers的库。1.2 人脸识别方案LFW精度
HOG结合角点检测能够在图像匹配任务中提供高鲁棒性的特征描述。适用于目标识别、拼接和物体跟踪等应用。在计算机视觉任务中,特征匹配是目标识别、图像配准和物体跟踪的重要组成部分。角点是图像中具有显著变化的点,在特征匹配中至关重要。HOG的基本思想是计算局部区域内像素梯度的方向分布,并构建特征向量。HOG提取局部特征,而角点提供关键匹配点,可以使用。使用OpenCV实现Harris角点检测。
时我们需要给一张图片添加logo,例如下图这样在这里插入图片描述掩膜操作思路它的思想是:1.1 先将彩色图像转换为灰度图,然后利于阈值将图像二值化,变成非黑即白的形式,这样logo的蒙版就做好来了(学过PS的人应该很容易理解);1.2 蒙版中黑色的区域表示删除掉该区域像素,白色表示保留该区域像素。黑色是0,白色是255;1.3 所以利用二值化得到的蒙版(掩膜)是剔除logo区域的。反之,是用来提出