- @qq_34478339
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文总结了Elasticsearch配置调优的三个关键方面:1)核心参数优化,包括内存锁定、节点发现机制、故障检测、队列控制和内存管理;2)系统层面调整,涉及JVM配置、交换分区、文件句柄、内存映射和磁盘优化;3)使用方式优化,如热点线程分析、任务队列监控和字段存储策略选择。通过合理配置这些参数,可以显著提升Elasticsearch集群的性能和稳定性。

本文对比分析了国内两款主流分布式数据库TiDB和OceanBase的关键特性。TiDB采用计算存储分离架构,兼容MySQL生态,适合互联网高并发和云原生场景;OceanBase采用计算存储融合设计,基于Paxos协议提供金融级强一致性。性能方面,OceanBase在TPC-C测试中表现更优,TiDB则在扩展灵活性上占优。运维上TiDB部署更简单,而OceanBase提供企业级自动化平台。选型建议:
本文深入分析了三款国产分布式数据库TiDB、OceanBase和PolarDB的架构特点与性能表现。TiDB采用分层架构,支持OLTP/OLAP融合处理,兼容MySQL生态;OceanBase基于Paxos协议实现金融级高可用,兼容Oracle/MySQL;PolarDB采用计算存储分离设计,支持弹性扩展。三者在数据分片、一致性机制、事务处理等方面各有特色,适用于不同业务场景,为企业数据库选型提供

SQL审核平台是数据库操作的"安全闸门",通过自动化流程取代人工审核,实现"事前拦截、事中管控、事后追溯"的主动防御体系。主流平台包括:Archery(支持多数据库)、SQLE(700+审核规则)、Yearning(简洁易用)和Bytebase(专业CI/CD)。这些平台通过语法检查、风险拦截、性能预判等功能,保障数据库变更安全,提升开发效率,是企业数据架构

本文探讨了从Docker Compose向Kubernetes迁移的实战方案,重点介绍了服务网格技术的应用。随着应用规模扩大,Docker Compose在伸缩性、服务发现和故障恢复方面的局限性日益明显,而Kubernetes提供了完整的容器编排解决方案。文章详细分析了迁移前的评估要点(存储、网络、镜像),并介绍了Kompose和Velero等迁移工具的使用方法。特别针对服务治理需求,深入讲解了I

摘要:随着数据量激增,传统SQL查询效率低下,大模型技术正变革数据分析流程。本文探讨大模型如何通过自然语言生成SQL、优化查询建议及异常检测等功能提升分析效率。案例显示某零售企业应用后,沟通成本降低80%,执行效率提高3-5倍。文章详细解析了技术架构,包括自然语言理解层和SQL优化层,并介绍本地部署方案。未来展望包括增强上下文感知、主动建议能力等趋势。大模型正推动数据分析从手动编写SQL向自然语言

本文介绍了多种存储性能监测工具的使用方法,重点讲解了perf工具的性能分析流程。首先通过perf record命令采集CPU占用和线程调度数据,结合vdbench压力测试生成性能分析文件,然后使用perf report可视化查看分析结果。文章还列举了numastat查看NUMA节点内存使用的方法,并提供了一个自动化脚本,可以同时监控vdbench测试和numastat统计结果。其他工具如iosta

摘要:随着数据量激增,传统SQL查询效率低下,大模型技术正变革数据分析流程。本文探讨大模型如何通过自然语言生成SQL、优化查询建议及异常检测等功能提升分析效率。案例显示某零售企业应用后,沟通成本降低80%,执行效率提高3-5倍。文章详细解析了技术架构,包括自然语言理解层和SQL优化层,并介绍本地部署方案。未来展望包括增强上下文感知、主动建议能力等趋势。大模型正推动数据分析从手动编写SQL向自然语言
CentOS7停止支持后,推荐迁移方案包括:Rocky Linux和AlmaLinux完全兼容RHEL,适合传统业务迁移;RHEL适合企业级高保障场景;openEuler和麒麟V10适配国产信创需求;Ubuntu适合云原生和DevOps场景。根据业务需求选择:传统应用选Rocky/Alma,安全合规选Alma/RHEL,政企信创选openEuler/麒麟,云原生选Ubuntu/Rocky。

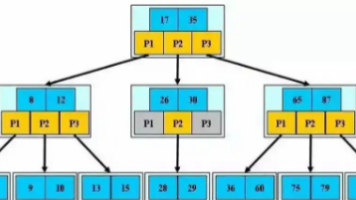
本文深入解析MySQL索引优化策略,重点探讨B+Tree索引原理及其在数据库性能优化中的应用。文章详细介绍了B+Tree的数据结构和数学原理,对比了其与B-Tree、哈希索引的优劣。针对最左前缀原则,通过多个查询场景分析复合索引的使用规律。同时,深入解读EXPLAIN命令的执行计划分析,提供索引设计的最佳实践,包括选择性原则、覆盖索引和复合索引设计模式。最后通过电商订单查询案例,展示如何将理论知识