- @qq_33876553
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
前言搭建samba的时候,如果是在内网\测试环境中,可以直接关闭防火墙,但是如果是在外网情况下,需要对防火墙开放某些端口。开放的具体步骤,下面我们来看。 操作步骤1.添加端口firewall-cmd --zone=public --add-port=80/tcp --permanent (--permanent永久生效,没有此参数重启后失效)2.重新载入fire...
前言正在使用react native构建自己的第二款APP,遇到了之前没有遇到的一些问题,就是点击下面的tabbar的时候,上面的状态栏问题无法动态改变。查阅了一些资料也没有头绪,最后去官网看了一下文档,解决后为有同样问题的大家分享一下步骤。步骤1. 重构navigationOptions使得可以接收参数static navigationOptions = ({ navigation }) =&a
前言之前博主一直是使用手动发布项目的,所以效率上是很费时的。最近因为搞了几台服务器,发布自己项目的时候感觉很痛苦。于是准备暂时打造一个自动化的发布脚本,第一步当然是将代码传到github上,因为码云上有免费的仓库,就直接用码云上手了。下面是将本地的代码使用git推到码云的步骤。环境操作系统:WIN10软件环境:git, Git Bash步骤1. 打开Git Bash, 生成公钥ssh-keygen
前言最近自己编写的react native安卓程序准备部署一下,发现调用的webview是本地的html文件,即url的格式是: http://localhost:8081/..这样的, 所以打包之后会出现加载不到页面的问题。所以下面就讲一下怎么样去修改,以便部署到线上不出问题。步骤1. 将html文件和相关的js/css等文件复制到asserts目录下 --即存放bundle包的目录,建议
前言打包apk的时候,遇到一个很神奇的问题,就是报错说找不到符号MainApplication.java:6: 错误: 找不到符号import com.facebook.react.ReactNativeHost;而且连续报了8个错误,后来查阅了很多文档,发现只有英文的帖子里有解决方法,最后拜读了一下,下面为大家解答一下问题详解很明显,这种错误是没有导入相应的包所导致的。所以很大的可能会是包管理工
Language Support for Java™ by Red Hat 插件版本较旧,无法将当前Java项目添加到source path中,导致无法编译。更新Language Support for Java™ by Red Hat 插件后重启VSCode,问题解决。使用VSCode编译、运行Java程序时,直接报错提示。
分布式NoSQL数据库基本概念什么是NoSQL?NoSQL是一些分布式非关系型数据库的统称,它采用非关系的数据模型,弱化模式或表结构、弱化完整性约束、弱化甚至取消事务机制,可能无法支持,或不能完整的支持SQL语句。目的是实现强大的分布式部署能力——一般包括分区容错性、伸缩性和访问效率(可用性)。什么是HBase?全称Hadoop Database,它是Google BigTable的开源实现,是一
这个时候有没有存在一整套的解决方案,能够帮我们存储这种海量的结构化、半结构化以及非结构化数据。即使规模再大,都能完成存储。存储之后基于海量的数据进行计算时,它的效率也很高,并且能够有很强的扩展性。有没有这样一套方案呢?当然有,这就是大数据技术生态。对于大数据,有一个比较长的、比较权威的定义。大数据是指超出传统数据库工具收集、存储、管理和分析能力的数据集。与此同时,及时采集、存储、聚合、管理数据,以

这些产品它们各自的功能是什么,它们又是怎么样相互配合来完成一整套的数据存储,包括分析计算任务。这里要给大家进行一个讲解与分析。我们按照数据处理的流程,从下往上给大家进行依次的讲解。

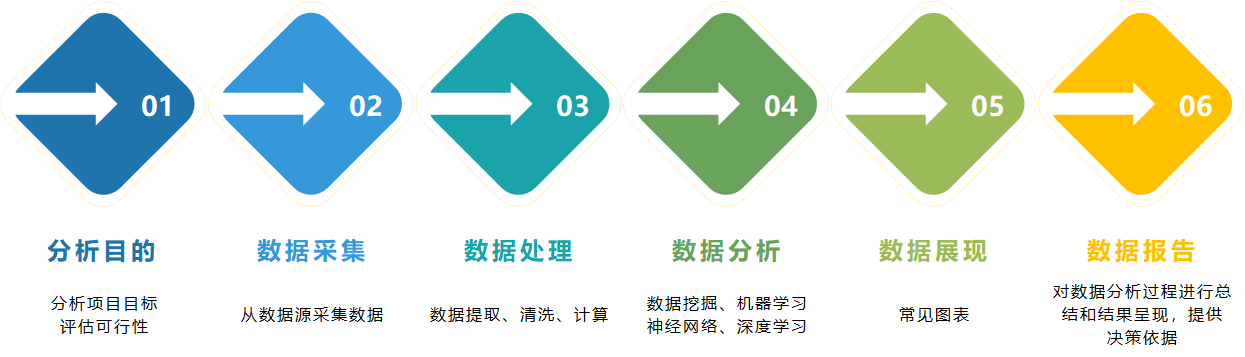
本教程内容,主要目的是帮助数据分析和机器学习的新手玩家快速了解开发流程,并运用于实战。整体讲解数据分析的整体流程,并结合一个极简案例——信用卡审批,快速上手数据分析,使用机器学习算子,完成结果的预测。开发语言使用Python3,数据处理使用Numpy、Pandas,机器学习使用Sklearn,可视化绘制使用Matplotlib。本次分享,主要以最小案例进行讲解,演示在数据分析工作中,使用机器学习算