- @qiutesting
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
想象一下,你有一大堆五颜六色的球,红的、蓝的、绿的……它们都混在一起。现在,你要做的就是根据颜色把这些球分成不同的组,红色的放一堆,蓝色的放一堆,绿色的放一堆。在机器学习中,聚类算法干的就是类似的事儿,只不过它处理的是数据,而不是球。聚类算法是一种无监督学习算法,它不需要我们提前告诉它数据应该分成几类,或者每一类是什么样的。把相似的数据点自动分到同一组,让同一组(簇cluster)内的数据尽可能相

学习路径graph TDA[线性回归] --> B[理解机器学习核心]A --> C[掌握基础算法]A --> D[建立数据思维]B --> E[后续学习更轻松]C --> F[能解决实际问题]D --> G[成为数据达人]关键收获🔍 学会用数学建模解决实际问题📊 掌握模型评估的基本方法🧠 理解机器学习的"调参艺术"学习建议👩💻 多动手:从简单案例开始实现📈 多可视化:用图表理解数据关

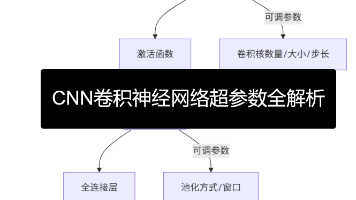
调参侠”必看!手把手教你用代码调教CNN模型,附“炼丹”避坑指南⚗️✨。
欧氏距离:直来直去的老铁曼哈顿距离:靠谱的出租车司机切比雪夫距离:警惕的棋手闵可夫斯基距离:多变的变形金刚马氏距离:高冷的贵族标准化欧氏距离:健身达人汉明距离:二进制世界的极客没有最好的距离,只有最适合的距离!下次当你构建模型时,不妨先想想:"我的数据更适合和哪种距离做朋友呢?"🤔📌 关注我,获取更多机器学习硬核干货!如果你有想了解的算法或技术,欢迎在评论区留言,我会考虑把它变成下一篇"爆款"

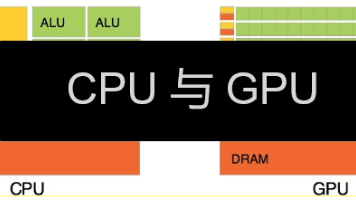
宝子们👋,在人工智能这个充满奇幻色彩的科技世界里,CPU 和 GPU 就像两位超级英雄,各自有着独特的本领,在各种场景中大显身手。今天咱就来深入了解一下它们到底是啥,工作原理如何,有啥区别,怎么找到它们,它们之间啥关系,还有在人工智能领域啥时候用 CPU,啥时候用 GPU🧐。
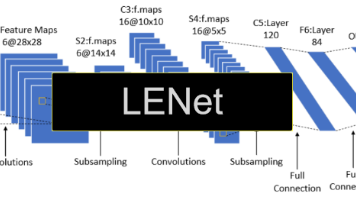
宝子们,今天咱们用LeNet模型在MNIST数据集上“炼丹”的过程是不是超有趣?通过这个实战,咱们不仅掌握了LeNet模型的结构和实现,还学会了如何用PyTorch框架进行模型训练和评估。深度学习就像一场奇妙的“炼丹之旅”,每一次尝试都可能带来意想不到的收获。希望你们也能在这个充满挑战和惊喜的世界里,不断探索,炼制出更多更强大的“神奇丹药”!💪好啦,今天的“炼丹”分享就到这里啦,咱们下次再见!?
经过前面的步骤,咱们的“丹药”终于要炼成啦!全连接层就像炼丹炉的“出丹口”,它把前面提取的特征整合起来,做出最终的判断(分类或回归)。它会综合考虑所有的特征,就像咱们判断一颗丹药是否炼成一样,要综合考虑颜色、气味、形状等多个方面,然后给出一个最终的“成丹”结果!宝子们,咱们这趟“炼丹”之旅是不是越来越有趣啦?从深度学习这口“大炼丹炉”,到CNN这位“炼丹小能手”,咱们一步步揭开了它们的神秘面纱。
TensorFlow + Horovod > PyTorch + DDP > MindSpore自动并行。:MindSpore联邦学习 > PySyft > TensorFlow Federated。🔥 建议掌握PyTorch+TensorFlow(覆盖90%场景)"你正在使用哪个框架?✅ TensorFlow(工业标准,长期维护)✅ PyTorch(学界标准,方便复现论文)✅ MindSpor

在目标检测领域,YOLO(You Only Look Once)系列算法以其惊人的速度和较高的准确率闻名于世。而支撑这一系列算法的"发动机",正是我们今天要深入探讨的Darknet。Darknet其实有双重身份:它既是一个轻量级深度学习框架,也是YOLO系列算法所采用的主干网络架构。这种"两位一体"的设计使得YOLO能够在性能和效率之间找到完美平衡🚀。高效性:通过精心设计的卷积组合和残差块,实现

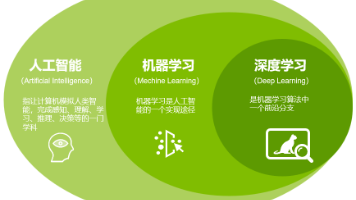
本文为零基础读者定制深度学习入门指南。首先拆解神经网络三层结构,结合猫狗分类案例,用Keras代码演示CNN模型搭建(卷积层+池化层+全连接层),并解析关键参数(如输入尺寸28x28、激活函数ReLU)。训练环节聚焦数据集划分(8:1:1)与fit()参数调优(epochs/batch_size),同步给出三大常见问题解决方案:过拟合用Dropout+正则化,梯度异常用ReLU+BatchNorm