




- @oe1019
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
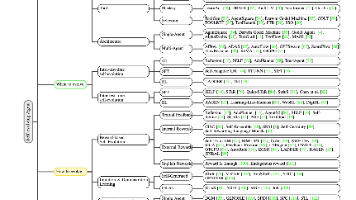
本文剖析了Agentic AI的8层架构设计存在的问题。作者指出原架构混淆了云原生与AI概念,存在层次划分混乱、协议归类不当等问题。重点关注协议层、工具增强层的有效设计,强调沙箱环境、热插拔等关键技术。同时分享了Manus上下文工程实践经验,包括文件系统上下文处理、错误保留机制等实用方法,指出错误恢复能力是检验Agentic行为的关键指标。文章建议重新梳理各层逻辑关系,明确区分基础设施与AI特性。
本文系统探讨了自我进化智能体的发展路径、理论框架与前沿应用。研究指出,当前大语言模型在动态适应性方面存在局限,而自我进化智能体通过持续优化模型参数、记忆库和工具集等组件,实现了更强的环境适应能力。文章提出了"进化内容-时机-方法"三维分析框架,对比了与传统学习范式的核心差异,并展示了其在代码生成、教育医疗等领域的应用潜力。研究还揭示了多智能体协同进化的创新机制,同时指出安全性、
摘要 本研究探讨了基于大语言模型(LLM)的智能体自我进化机制,重点关注动态学习与任务执行的时序关系。研究提出了测试时内进化和测试时间外进化的分类框架,解决了传统方法中学习效率与任务表现平衡不足的问题。通过实时进化(任务执行中调整)和回顾式进化(任务后优化)两种模式,智能体能够更高效地适应复杂场景。研究还分析了多种自我进化策略,包括基于奖励的进化、示范学习和群体方法,展示了这些方法在减少人工干预、
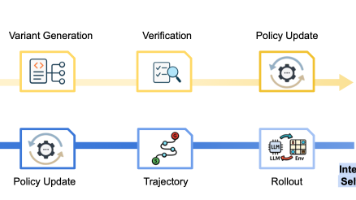
本文系统分析了智能体自我进化的三大核心方法:基于奖励、模仿学习和群体进化。研究对比了不同方法在效率、稳定性和适应性上的差异,提出需权衡设计的关键维度。结果表明:基于奖励方法目标明确但依赖设计;模仿学习数据高效但受限示范质量;群体进化探索性强而计算成本高。针对学习模式,研究指出离线学习稳定高效但环境适应性差,在线学习灵活动态却需更高算力。在策略学习方面,同策略方法稳定性高但样本效率低,异策略方法数据

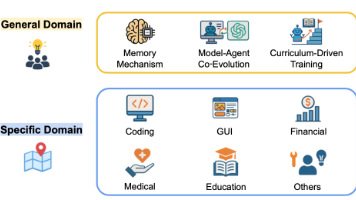
摘要:自我进化智能体的发展与评估 自我进化智能体在通用和专业领域取得显著进展。通用智能体通过记忆优化、课程训练和协同进化提升跨任务适应性;专业智能体在医疗、金融、教育等领域深化专长,如医疗AI通过虚拟病例训练优化诊断策略。评估面临传统静态测试的局限,需转向动态跟踪五大维度:适应性、保留性、泛化性、效率及安全性,采用迭代成功率等指标量化学习曲线。解决方案包括长期监测、多维指标体系和动态评估范式,以全
本文介绍了一个基于开源技术栈(STT+DeepSeek)的实时语音翻译系统,能在20秒内完成语音转换和翻译,成本低至7天旅行仅3-6元。文章详细解析了技术选型、性能优化(12秒STT处理+8秒API响应)和应用场景,并展示了实际测试视频。所有代码已在GitHub开源,邀请开发者共同完善。作者强调技术民主化的重要性,认为AI应成为连接世界的桥梁。项目适用于多语言场景,如旅游翻译、跨国商务等,具有低成
美国初创公司Arcee AI发布4000亿参数开源大模型Trinity Large及其小型变体,采用混合专家架构和滑动窗口注意力技术。中国公司月之暗面同期推出万亿参数开源模型Kimi K2.5,在性能上超越专有模型,并支持多模态处理。StepFun的Step 3.5 Flash以1960亿参数实现高推理速度,采用多token预测技术。阿里Qwen3团队发布的800亿参数编程专用模型Qwen3-Co
摘要: 提案SEP-1306旨在解决医疗保健分析平台PlanVantage在文件上传时面临的核心问题。当前本地MCP服务器通过stdio传输文件运行良好,但远程HTTP+OAuth连接器因需要base64编码导致性能低下(50-100次工具调用/文件)、频繁失败和糟糕的用户体验。该提案提出的客户端中介上传方案,利用客户端已有文件权限代理传输,既能保持无缝安装体验(无需Node.js配置),又能实现
摘要: 本文通过实测DeepSeek V4在开源项目PR中的表现,剖析AI协同编程的四个关键剖面:1)在结构化约束下精准实现需求;2)高覆盖率的测试代码可能制造虚假安全感;3)真实场景测试暴露核心设计缺陷;4)AI会固执维护自洽但错误的设计决策。测试发现,该模型虽总分优异,但在工程实践中呈现"高度服从与局部固执"的双重特性。最终验证了Harness工程三大原则:严格约束框架、真
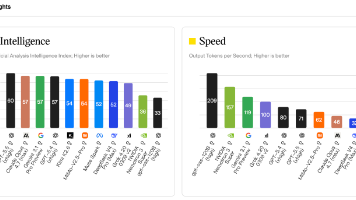
摘要: 本文通过实测DeepSeek V4在开源项目PR中的表现,剖析AI协同编程的四个关键剖面:1)在结构化约束下精准实现需求;2)高覆盖率的测试代码可能制造虚假安全感;3)真实场景测试暴露核心设计缺陷;4)AI会固执维护自洽但错误的设计决策。测试发现,该模型虽总分优异,但在工程实践中呈现"高度服从与局部固执"的双重特性。最终验证了Harness工程三大原则:严格约束框架、真