




- @nebula1008
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
通过microsoft应用商店方式获取是最好的(搜nvidia control panel)(其他的方法不太好,后面会出很多问题),但这个应用商店似乎一直刷不出来。尝试各种办法,最后得到了解决。
1. 数据集数据集涉及到训练集(train data)、验证集(validation data)和测试集(test data)。利用训练集(train data)来训练出最好的网络权重,但怎么保证训练过程中参数的更新方向是有效的呢?于是用验证集(validation data)在训练的时候边训练边验证,相当于训练的时候是根据验证集的效果得到反馈,继而可以及时地往对的方向更新权重参数。举个例子,网络
python统计csv文件行数import pandas as pd#导入pandas包data = pd.read_csv("xxx.csv")#读取csv文件#count = len(open('905909197体表温度.csv',"rU").readlines())#print(data)print(len(data))我需要比对很多csv文件的行数,搜了一圈怎么计算这个行数,发现直接le
当你pip list时,那些包有些是在Anaconda3\envs\tf\Lib\site-packages,有些是在C:\Users\username\AppData\Roaming\Python\Python38\site-packages,所以有时候会看见某个库有两个版本同时存在,这样也会造成很多包的不兼容。突然,我想到了加–user可以把包放在c盘的AppData\Roaming\Pyth

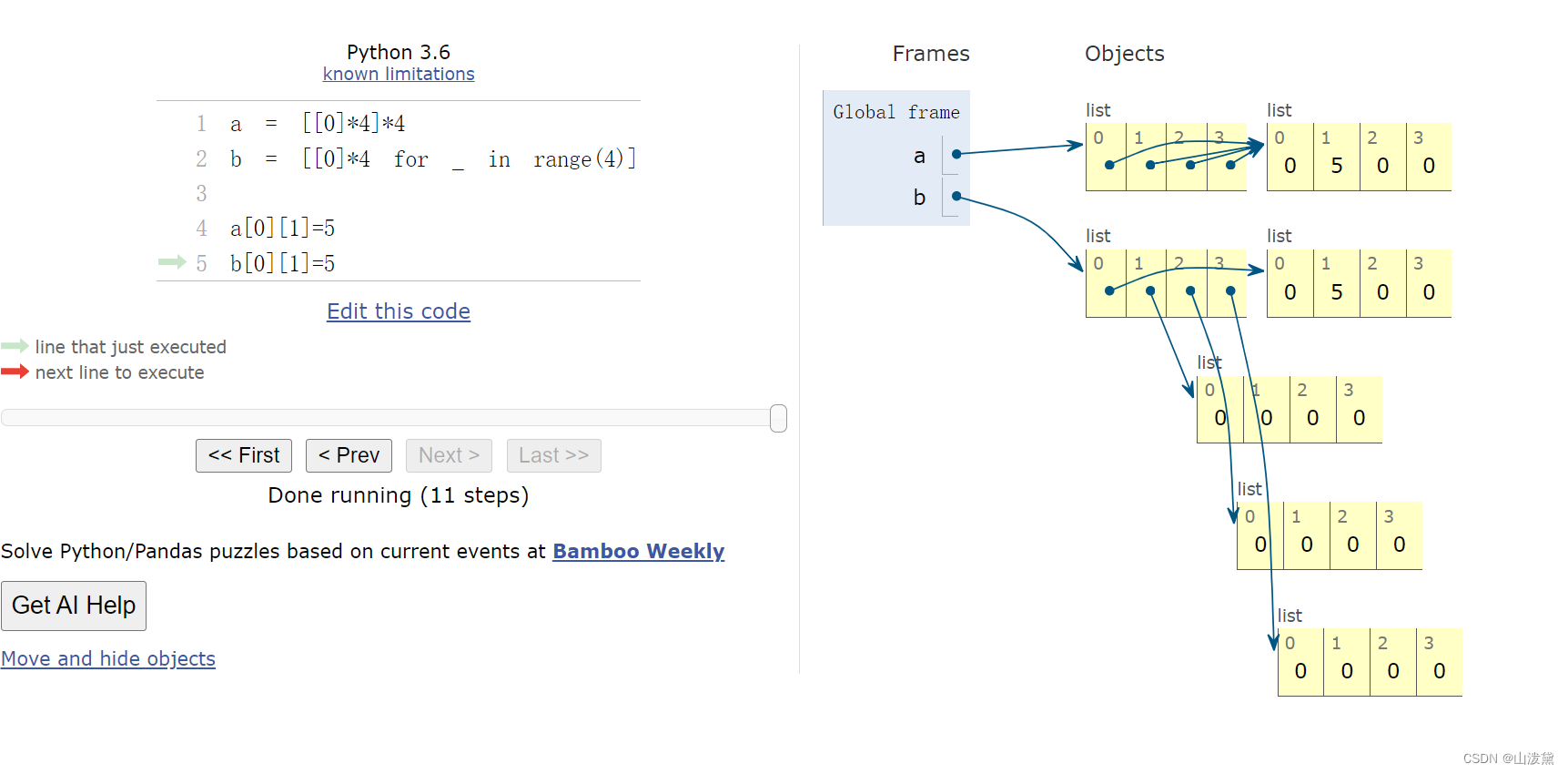
第一种初始化方法创建矩阵时使用了相同的子列表对象。在Python中,使用 [0] * n 这样的方式创建子列表时,实际上是对相同的子列表对象的引用。因此,当你修改其中一个子列表的元素时,其他子列表也会受到影响。以前经常混用也没发现什么问题,直到昨天debug的时候发现第一种初始化之后对矩阵进行赋值时混乱的,比如matrix[0][1]=2会导致所有行的第二列都变成2。为了避免这种问题,可以使用列表
误差:模型越复杂,平均误差反而越大。这种error的主要来源是偏差bias和方差variance。由真实数据训练得到的模型与理想模型之间存在的差距就算是偏差和方差导致的。不同模型的偏差和方差不同。偏差大说明欠拟合。方差大说明过拟合。因此需要在偏差和方差之间权衡一个模型,使得总误差最小。可以通过交叉验证或者n折交叉验证得到的准确率来选择。梯度下降法:这是一种更新参数值的方法。就是每次更新的幅度,由当
后面我的还是报错,缺少dll文件,发现自己没安装cuda和cudnn。看c盘的program files文件夹下是否有NVIDA GPU computing toolkit文件夹,如果没有,可以安装下面这个教程一步步安装。最后导入tensorflow成功,但是导入keras还是有问题。降低numpy的版本,好像1.24.0版有很多问题。好像是新版该规则了,换一下写法就行。
force-reinstall:通常,如果已经安装了请求的包的最新版本,pip将不会重新安装包。使用这个参数,pip会忽略包的当前安装状态,强制重新下载并安装指定版本的包,即使它已经是最新版本。这对于解决安装问题或损坏的包文件特别有用。可能的原因是环境中安装了与标准TensorFlow包不同的包,或者可能是TensorFlow没有正确安装。解决方法如下,亲测有效。

force-reinstall:通常,如果已经安装了请求的包的最新版本,pip将不会重新安装包。使用这个参数,pip会忽略包的当前安装状态,强制重新下载并安装指定版本的包,即使它已经是最新版本。这对于解决安装问题或损坏的包文件特别有用。可能的原因是环境中安装了与标准TensorFlow包不同的包,或者可能是TensorFlow没有正确安装。解决方法如下,亲测有效。
按住shift选中多个cell后,按shift+m可以合并选中的多个cell为一个cell。这两个单元格合并之后一个。合并之后也可以将一个单元格切分成两部分,首先将光标放在想分割的地方,然后按Ctrl+shift+ -...