




- @m0_74373135
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
遇到“与 Windows 版本不兼容”的报错时,不要盲目去升级或降级 Windows 系统。在 99% 的情况下,这只是因为 npm 的安全机制拦截了核心文件的下载脚本。通过先卸载、再使用参数重新安装,即可轻松解决此问题,让你的 AI 编程助手恢复正常运行!
遇到“与 Windows 版本不兼容”的报错时,不要盲目去升级或降级 Windows 系统。在 99% 的情况下,这只是因为 npm 的安全机制拦截了核心文件的下载脚本。通过先卸载、再使用参数重新安装,即可轻松解决此问题,让你的 AI 编程助手恢复正常运行!
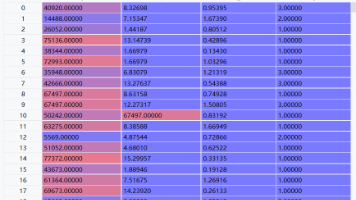
本文实现了一套AI 驱动的全自动课堂教学质量分析系统,通过多维度数据评分 + 大模型智能诊断,让课堂评估从 “人工主观” 走向 “数据客观”。系统可快速输出课堂得分、问题分析、改进建议,大幅提升教研效率,降低评课成本,是智慧教育领域非常实用的技术工具。
本文介绍了一套基于Docker自托管的开源电商智能客服解决方案,采用Dify+Ollama+Qwen3.5:4b技术栈实现完全本地化部署。该方案通过WSL2环境配置、Dify容器部署、Ollama模型对接三个核心步骤,构建了包含商品查询、价格计算、促销读取等功能的智能客服Agent。系统采用SQLite存储商品数据,支持离线运行且无需支付API费用,有效解决了传统方案的成本高、隐私风险等问题。文章
本文介绍了LLaMAFactory工具的使用方法,主要包括三个核心部分:微调、推理和模型合并。首先详细说明了安装步骤和运行环境配置,包括GPU实例设置和依赖安装。其次重点解析了三个关键YAML配置文件的功能:训练配置文件定义模型学习参数,推理配置文件用于交互测试,合并配置文件将LoRA适配器整合到基础模型中。文章还对比了全量微调、LoRA和QLoRA三种微调方式的优缺点,并介绍了模型量化技术(如G
通过可视化的方式展示了如何在三维空间中应用k-NN算法进行学生性格分类,将爱学习、一般和爱玩的学生分别用不同颜色标记,并解释了如何通过调查问卷和辅导员的专业分析来获取和分类学生数据。机器学习中的k-近邻算法(k-NN)是一种基于实例的监督学习算法,适用于分类和回归任务。其核心思想是通过测量目标数据点与训练集中其他点的距离,找到最近的k个邻居,并根据这些邻居的类别(分类)或平均值(回归)进行预测。3
人脸识别是计算机视觉领域最经典、最实用的应用之一。,无需复杂训练、无需 GPU,仅用少量样本就能实现精准识别。本文将通过,从最基础的静态识别,一步步升级到,每段代码都保留原貌并详细解释,带你从零掌握 OpenCV 人脸识别全流程。
如果计算机上已经安装了与CUDA版本相兼容的Visual Studio Integration文件,或者通过其他方式(如单独安装Visual Studio的插件)已经集成了CUDA支持,那么在安装CUDA时勾选“Visual Studio Integration”可能会导致冲突或重复安装,进而引发问题。Torch是一个开源的机器学习库,主要用于构建深度学习模型。它基于Lua编程语言,并提供了一个强
在不新增真实采集的原始数据的前提下,对已有数据集做变换、扰动、裁剪、拼接、加噪等操作,批量生成更多“等价但不一样”的样本,用来扩充训练集、防止模型过拟合、提升泛化能力。数据增强就是低成本、零标注成本,对原有样本做合理随机变换,造出海量等价训练数据,专治深度学习数据少、过拟合、实战效果差三大问题,是做CV、NLP项目必用的基础操作。- 几何变换:随机翻转(水平/垂直)、随机裁剪、缩放、平移、旋转、透
背景建模的核心是区分静态背景和动态前景,通过 MOG2 算法构建背景模型,自动提取视频中的运动物体,常用于监控、人流统计、运动分析等场景。import cv2# 打开视频/摄像头cap = cv2.VideoCapture('test.avi') # 改为0则调用摄像头# 定义结构元与背景减法器break# 背景建模,提取前景# 开运算去噪# 轮廓检测# 过滤小目标# 显示结果break。