- @m0_74277350
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本博客展示了如何使用C#和百度AI接口实现人脸检测和人脸比对功能。第一段代码通过检测图像中的人脸,提取并分析人脸的质量属性,如年龄、模糊度和光照等,确保图像质量符合要求。第二段代码则进一步实现了人脸比对,通过比较两张人脸图像来确定它们是否属于同一个人。后续人脸注册和人脸登录的代码,如果需要可以私我一下。
Oracle分布式数据库的安装遇到的问题【已解决】:找不到scott用户、出现【INS-30014】错误、oracle登录适配器错误

这个搭建过程主要是CentOS上成功完成了Hadoop和HBase的伪分布式安装。主要包括环境配置、Hadoop与HBase的安装、配置与测试。
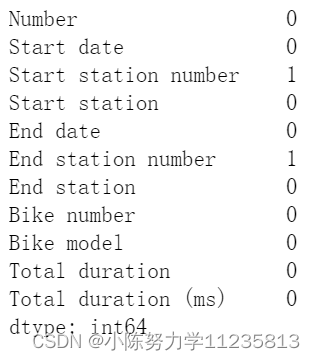
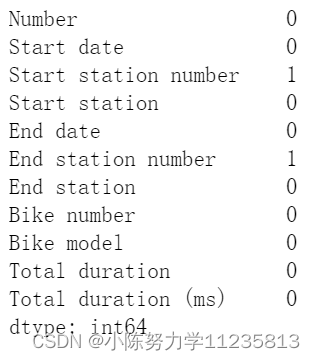
数据集已经上传到了我的资源里面,对于这个数据集,将进行数据预处理,然后进行k-means聚类、使用线性回归进行回归、使用XGBoost进行回归分析,并且进行分类预测。这篇主要是完成了数据的预处理、特征工程、可视化分析和多种机器学习模型的应用。对这个单车数据进行了聚类、回归、分类并进行可视化。
根据给定的葡萄酒分类记录,建立聚类模型,对葡萄酒信息进行聚类(此时注意去除数据集中分类信息),并进行模型评估。即主要内容是基于葡萄酒信息进行聚类分析和模型评估。首先加载并预处理数据,去除分类信息并进行标准化。接着,使用手肘法和轮廓系数确定K-means聚类的最佳簇数,并进行K-means聚类。然后,通过网格搜索找到DBSCAN的最佳参数,进行DBSCAN聚类。随后,采用最佳K值进行Agglomer
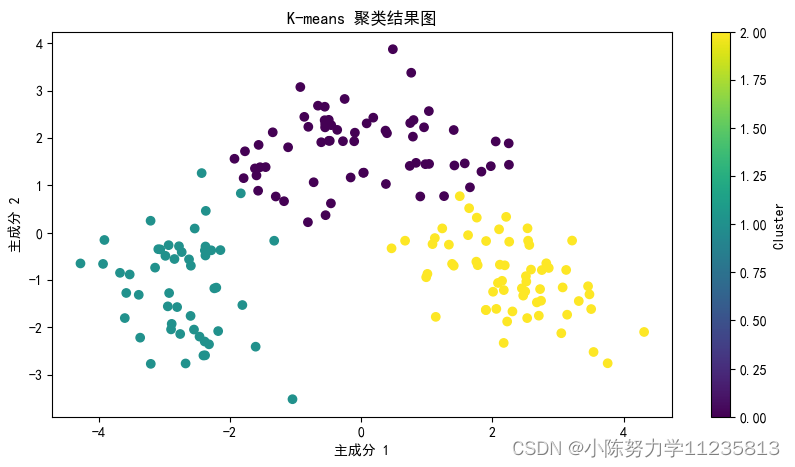
根据给定的葡萄酒分类记录,建立聚类模型,对葡萄酒信息进行聚类(此时注意去除数据集中分类信息),并进行模型评估。即主要内容是基于葡萄酒信息进行聚类分析和模型评估。首先加载并预处理数据,去除分类信息并进行标准化。接着,使用手肘法和轮廓系数确定K-means聚类的最佳簇数,并进行K-means聚类。然后,通过网格搜索找到DBSCAN的最佳参数,进行DBSCAN聚类。随后,采用最佳K值进行Agglomer
众所周知,GPT的中文库有点问题,要求他画带中文的图或表存在中文的时候,就会出现乱码或者方框。可以通过上传字体的方法解决这个问题(文章已附字体下载链接)

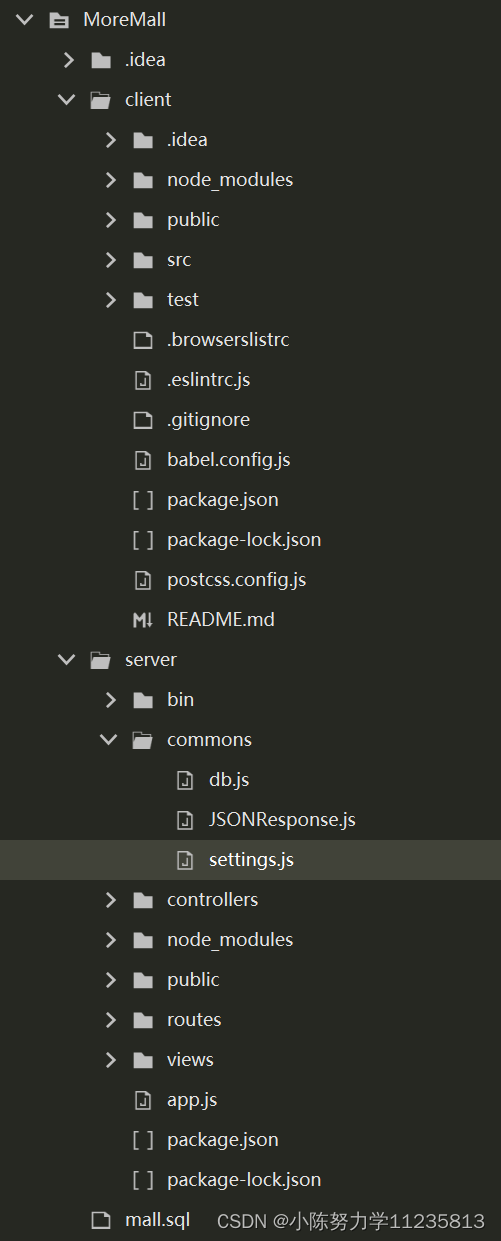
本博客用来介绍一下一个包含前端和后端代码的全栈项目MoreMall,前端部分使用了 Vue.js,后端部分使用了 Node.js。
数据集已经上传到了我的资源里面,对于这个数据集,将进行数据预处理,然后进行k-means聚类、使用线性回归进行回归、使用XGBoost进行回归分析,并且进行分类预测。这篇主要是完成了数据的预处理、特征工程、可视化分析和多种机器学习模型的应用。对这个单车数据进行了聚类、回归、分类并进行可视化。