




- @m0_73752612
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Datawhale Hello-Agents学习笔记,记录了核心概念、可运行的demo和结果、思考。适合入门AI Agent开发。

Datawhale Hello-Agents学习笔记,记录了核心概念、可运行的demo和结果、思考。适合入门AI Agent开发。
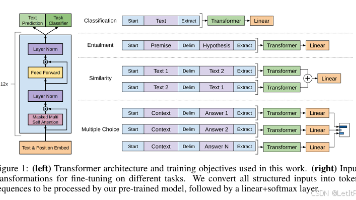
本文系统梳理了GPT系列模型的技术演进路线,从GPT-1到GPT-4的核心技术始终基于Decoder-only Transformer架构。GPT-1首创无监督预训练+微调范式,通过任务特定输入表示实现迁移学习;GPT-2转向纯预训练,探索zero-shot能力;GPT-3突破性地提出few-shot上下文学习,利用1750亿参数实现元学习;GPT-4则实现多模态突破,通过RLHF提升对齐能力。
本文结合实习中 Docker 的学习经历,系统梳理了 Docker 的基本概念、安装及 Windows 与 Linux 环境下的使用差异,并介绍了从编写 requirements.txt、Dockerfile 和 .dockerignore,到执行 build、run、查看日志、进入容器、停止与删除容器的完整流程。同时总结了镜像、容器、端口映射、目录挂载、数据卷、网络、环境变量和清理命令等常用操作

聚焦于pytorch框架下的cnn(含mnist识别手写数字集)、rnn和lstm、解码器编码器、自编码器模型(对MNIST数据集图像的降维和重建)。

从0入门机器学习,本篇分享几种最常用的聚类算法如k-means,参差聚类等等,包括其原理、聚类算法的评价指标,还有对各种距离公式(马氏、欧式、明氏、余弦距离、汉明距离等等)的计算。

本文详细介绍了不同的编码(onehot)、嵌入(word2vec、node2vec)、文本提取(TF-IDF)方式,并介绍了不同的编码器库函数。

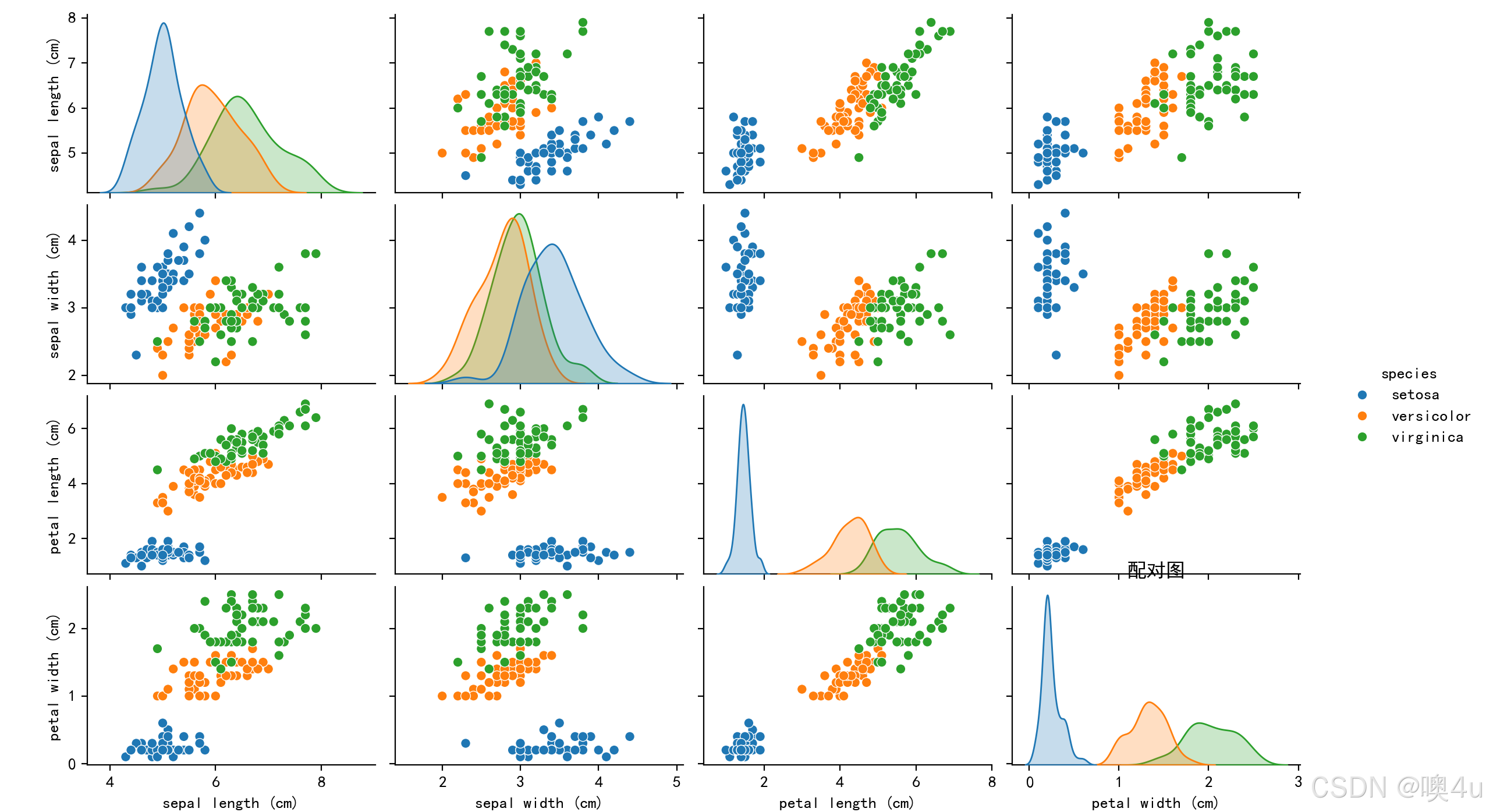
本文介绍了多种数据可视化方法,使用经典数据集如iris或伪数据为例,绘制了以下图表:核密度图、箱线图、小提琴图、气泡图、蜂群图、三维散点图、折线图、雷达图、散点图回归线、条形分布图、堆叠条形图、饼图、配对图、热力图、极坐标图、分面图、区域图、平行坐标图、漏斗图、瀑布图、树状图、甘特图、桑基图、旭日图、蜡烛图、地图,以及文字形式的词云图、网络图等。此外,还介绍了tensorboard的使用以及展示了
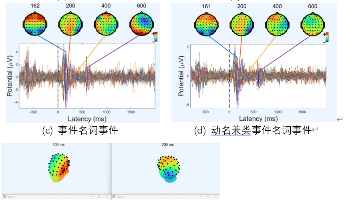
本实验利用EEGLAB分析视觉词性判断任务中的脑电数据,探讨名词、动词、事件名词及动名兼类事件名词在语义加工中的神经差异。实验通过滤波、重参考、ICA等预处理步骤,提取ERP成分及时频特征(ERSP、ITC)。结果显示,不同ERP成分在关键通道(Cz、F3、TP7)上的脑电特征存在显著差异,验证了词性判断过程中的多通道协同机制。实验揭示了词汇加工的时空动态,为视觉刺激任务的神经电生理反馈提供了证据
深入解析:基础概念,动态规划、Q-learning、SARSA、DQN、ac、PD算法,Boltzmann、ϵ-greedy策略,优先级回放技术
