




- @m0_65079043
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
1:更新API调用和使用方法(Gemini/glm等),使用魔壶可通过调用API实现提示词反推/翻译等功能。魔壶下载地址:http://129.204.148.21:5000/sharing/8xdPWxtBL。*大家在制作和使用快应用,远程调用ComfyUI等有问题,可联系我们协助,加我QQ或者频道内联系都可。4:增加对Mac支持,需下载Mac安装包。3:快应用管理可通过文件夹管理。2:增加内置
LoRA(Low-Rank Adaptation)是一种高效的微调技术,通过引入可训练的低秩矩阵,冻结大模型的大部分参数,实现低资源消耗下的高效微调。在图像生成领域,LoRA广泛应用于Stable Diffusion等模型,用于快速定制特定风格、角色或材质的图像生成。对比分析SD1.5、SDXL和FLUX三种模型中的LoRA微调技术,SD1.5适合算力有限的用户,SDXL适合追求高质量图像生成的用

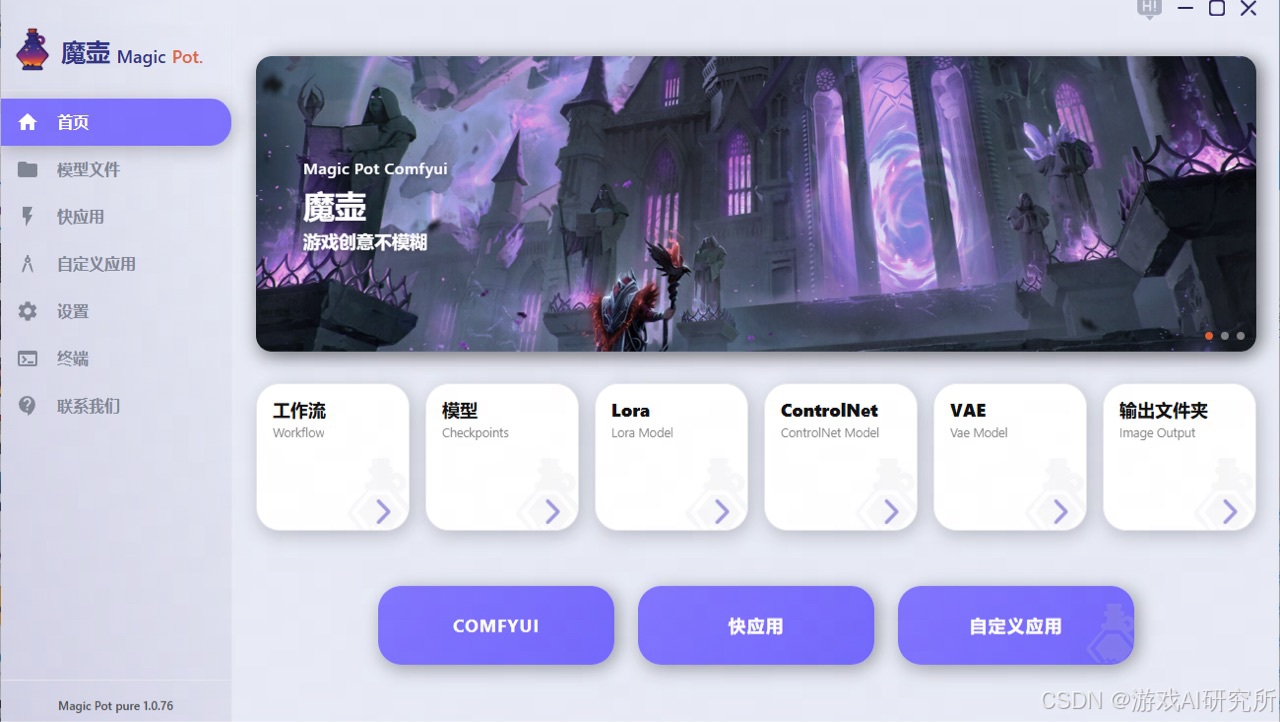
二。VAE 在 Stable Diffusion 中的作用?在 Stable Diffusion 中,VAE 的主要功能包括:1.图像压缩与还原:将图像编码到潜在空间,进行处理后再解码还原,提升生成效率。2.提升图像质量:改善生成图像的色彩饱和度和细节表现,尤其是在面部、手部等细节区域。3.与扩散模型协同工作:在潜在空间中进行扩散过程,提升生成图像的多样性和质量。例如,使用 VAE 可以使生成的图
ComfyUI 里的 Prompt 插值器(prompt interpolation / text encoder 插值方式),不同选项代表不同的提示词解析方式或兼容模式。就是模型在把文字 prompt 转成 embedding 时,怎么处理、怎么混合。
「Stable Diffusion/SDXL框架下AI采样算法性能分析与优缺点评估」——副标题:以不同采样策略在生成质量、效率与资源消耗方面的对比为核心
数量比例:一般为训练数据集的 1:1 到 1:10,根据任务的复杂性进行调整。风格差异:确保风格差异适中,避免过大差异引发过拟合。超参数调整:调整正则化强度与学习率等超参数,确保正则化不影响模型的主学习目标。影响:正则化数据集的增加通常能提升泛化能力,但过多会影响训练效果,特别是模型可能会偏向于正则化数据集的特征。

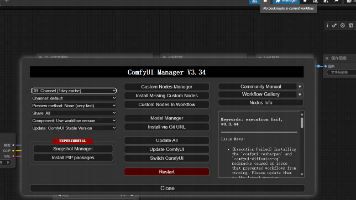
本文介绍了ComfyUI-Manager插件的安装步骤:1)下载并安装GIT;2)进入ComfyUI的custom_nodes目录;3)克隆GitHub仓库或运行便携版脚本;4)安装Python依赖库;5)重启ComfyUI后即可使用管理功能,包括安装节点/模型、更新插件等。该教程由游戏AI研究所社区提供,帮助用户扩展ComfyUI功能。
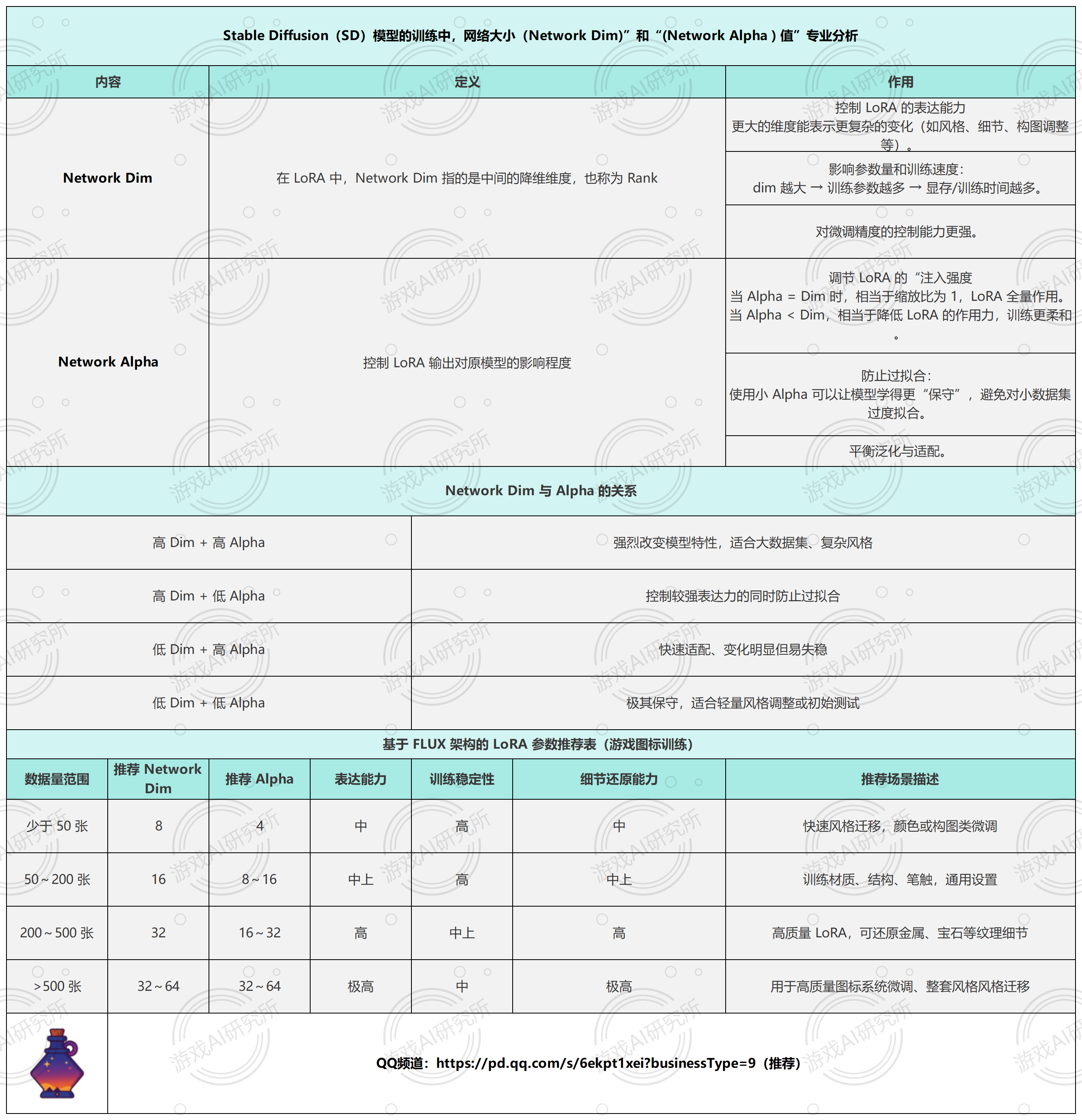
控制 LoRA 的表达能力更大的维度能表示更复杂的变化(如风格、细节、构图调整等)。
在Stable Diffusion(SD)中,步数(Steps) 指的是采样过程中的迭代次数,也就是模型从纯噪声一步步“清晰化”图像的次数。你可以理解为模型在画这张图时“润色”的轮数。

在 LoRA(例如使用 Kohya‑ss)训练中,epochs 和 repeats 分别控制了模型“看”数据的轮数和每张图在一个epoch中出现的频次,两者共同决定训练强度和步骤总数
