




- @m0_62894677
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
首先回顾大模型的训练流程。大模型的训练流程包括预训练和后训练。预训练是使用大规模的训练语料训练模型,主要是让模型获得先验知识,能够完成基本的补全任务(理解:让模型读书,让它学会一些基本预测。比如:第一个字是“中” 学会预测第二个词是“国”)后训练是经过指令微调和偏好优化,让模型的输出具有某些特定格式,能够满足人类偏好。什么是指令微调?指令微调就是用一些人工标注的数据去训练模型,让模型会做题,会根据

🌳🌳🌳前言:本文章针对于如何用IDE和webstorm运行一个别人的vue项目进行步骤记录。

在2019年9月,Google公司发布了TensorFlow2.0版本,紧接着在11月,公布了TensorFlow 2.1的RC版本,兼容之前的流行库,并还引入了众多新库,使得TensorFlow的功能空前强大。在2017年1月,Face-book人工智能研究院(FAIR)推出了PyTorch,并在2018年5月正式公布PyTorch 1.0版本,这个新的框架让开发者可以无缝地将AI模型从研究转到

它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。:全连接层将前一层的所有输出与当前层的每个神经元连接,能够整合前一层的局部或全局特征,生成新的特征表示。Softmax 通过指数运算放大高分值的类别,抑制低分值的类别,使得高分值的类别概率更接近 1,低分值的类别概率更接近 0。RNN不同于
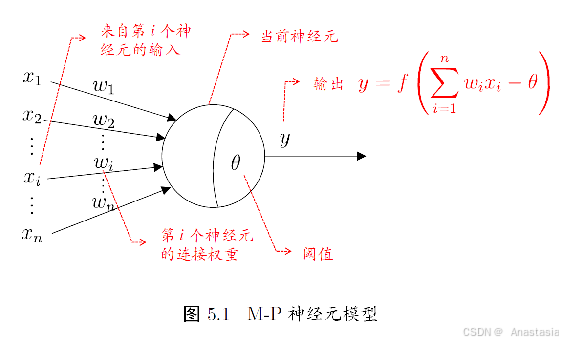
第一个任务是Mask LM(MLM),为了解决GPT完全舍弃下文的问题,不再进行整个句子的预测而是对某个词去做预测,首先屏蔽一定百分比的词,然后通过模型实现对屏蔽词的预测,来进行训练。二是预测的是屏蔽掉的是词而非句子,会使整个句子预训练的收敛速度更慢。N-gram是自然语言处理领域中具有显著历史意义的特征处理模型,基本思想是将文本内容按照字节大小为N的滑动窗口进行操作,形成长度是N的字节片段序列,

首先回顾大模型的训练流程。大模型的训练流程包括预训练和后训练。预训练是使用大规模的训练语料训练模型,主要是让模型获得先验知识,能够完成基本的补全任务(理解:让模型读书,让它学会一些基本预测。比如:第一个字是“中” 学会预测第二个词是“国”)后训练是经过指令微调和偏好优化,让模型的输出具有某些特定格式,能够满足人类偏好。什么是指令微调?指令微调就是用一些人工标注的数据去训练模型,让模型会做题,会根据
安装pytorch

🌳🌳🌳前言:本文章针对于如何用IDE和webstorm运行一个别人的vue项目进行步骤记录。
pycharm连接远程服务器&&解决远程服务器文件不同步问题
