- @m0_62102955
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
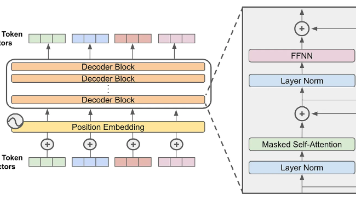
LLM(Large Language Model)大型语言模型LLM)是一种利用自监督机器学习方法,基于海量文本训练而成的语言模型,专为自然语言处理任务而设计,尤其适用于语言生成。
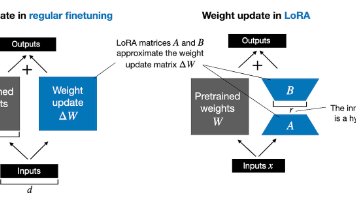
LoRA(低秩自适应)是一种高效的大语言模型微调方法。其核心思想是假设模型适配时的权重更新矩阵具有低内在秩,通过在原始线性层旁路引入低秩矩阵进行参数更新,而不改变预训练权重。该方法将权重更新分解为两个低秩矩阵的乘积,显著减少可训练参数(GPT-3场景下可减少1万倍),同时保持与全量微调相当的效果。LoRA具有三大优势:1)参数高效,显存占用降低3倍;2)训练吞吐量提升25%;3)部署灵活,可合并回
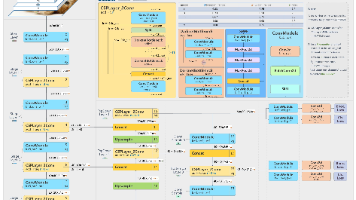
本文详细解析了YOLOv8的模型结构与实现细节。主要内容包括:1. 模型获取方式(下载完整代码或单独yaml文件);2. 网络结构总览,包含Backbone(CSPDarknet)、Neck(PAN-FPN)和Head(解耦检测头);3. Backbone部分详解,重点分析Conv、C2f和SPPF模块的作用及参数设置;4. Neck部分的特征融合机制,解释上下采样的实现原理;5. Head部分的
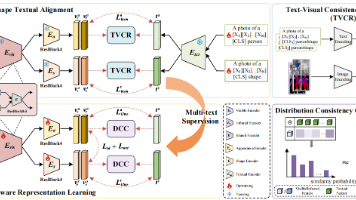
本文提出一种基于身体形状文本对齐(BSaTa)的红外可见光行人重识别方法。针对现有方法忽视人体形状建模的问题,该方法分两阶段进行:首先通过人体解析和CLIP文本编码器将人体形状转换为结构化文本表示;然后利用冻结的文本描述监督视觉特征学习,并结合跨模态分布一致性约束。实验表明,该方法能有效增强形状语义表示,在多个基准数据集上取得优于现有方法的效果。主要创新在于显式建模人体形状信息并将其转化为文本监督
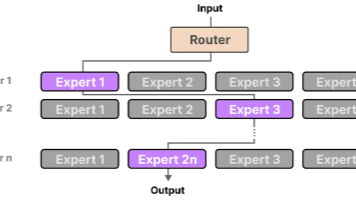
本文对比分析了稠密模型(Dense Model)和混合专家模型(MoE)两种大语言模型架构。稠密模型采用全参数激活机制,而MoE通过"路由选择+专家分工"实现稀疏激活,仅调用部分专家网络处理输入,在保持大容量的同时降低计算成本。MoE的核心流程包括输入、路由打分、专家计算、结果聚合和输出五个步骤,其中路由器根据输入特征动态选择最匹配的专家。文章还详细介绍了MoE的路由机制、专家
LoRA(低秩自适应)是一种高效的大语言模型微调方法。其核心思想是假设模型适配时的权重更新矩阵具有低内在秩,通过在原始线性层旁路引入低秩矩阵进行参数更新,而不改变预训练权重。该方法将权重更新分解为两个低秩矩阵的乘积,显著减少可训练参数(GPT-3场景下可减少1万倍),同时保持与全量微调相当的效果。LoRA具有三大优势:1)参数高效,显存占用降低3倍;2)训练吞吐量提升25%;3)部署灵活,可合并回
pat乙级考试总结帖
本文介绍了YOLO目标检测系统的完整使用流程,包括环境配置、数据标注、模型训练和参数调优。主要内容包括:1)使用conda创建虚拟环境并配置CUDA和PyTorch;2)通过LabelMe进行数据标注并转换为YOLO格式;3)组织标准数据集结构并配置data.yaml文件;4)使用开源数据集进行模型训练,包括初始训练和继续训练;5)调整超参数优化模型性能。文章提供了详细的代码示例和注意事项,适合Y
本文详细介绍了在本地部署Qwen大语言模型的完整流程。通过Docker容器化技术实现模型轻量化部署,利用WSL子系统在Windows环境下搭建Ubuntu环境,并针对常见安装问题提供解决方案。文章包含显存-模型适配对照表、模型下载与测试方法、Docker容器构建步骤,以及使用Tailscale实现内网穿透的分布式部署方案。整个过程涉及环境配置、模型量化、性能测试等关键环节,为开发者提供了从零开始部