




- @m0_59596990
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
最近这一两周不少公司都已经停止秋招了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。多模态大模型(Multimodal Large Language Models, MLLMs)在视觉问答、OCR等诸多多模态任务上取得了令人印象深刻的表现。然而,已有ML
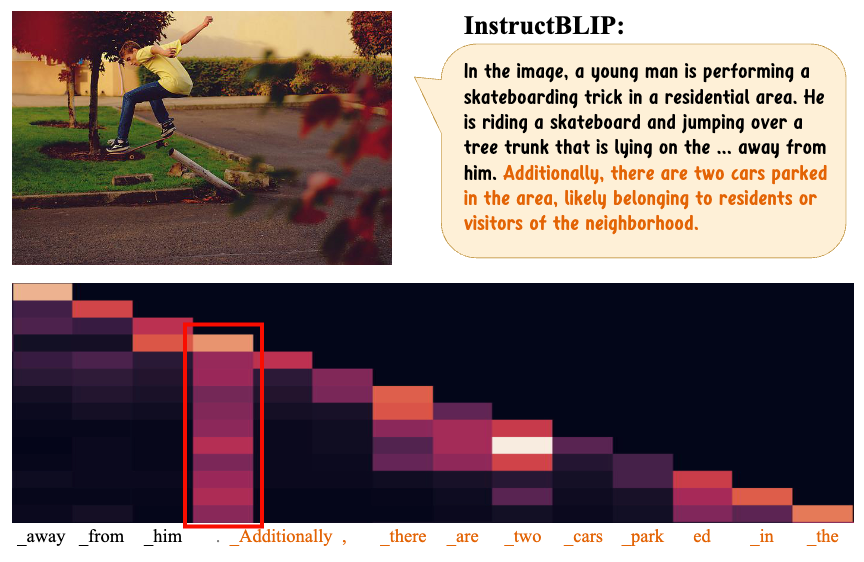
是时候准备面试和实习了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。最近一星球小伙伴跟我聊天,拿到了智谱多模态算法岗 Offer。整个面试过程非常快,两轮技术面加上一轮HR面,三周拿到Offer,效率非常快。今天我给大家梳理出来这家公司的薪资结构、工

强化学习框架怎么选?不如自己定制一个。强化学习(reinforcement learning,RL)是近年来最受关注的人工智能研究方向之一,在机器人、游戏等领域应用甚广。现有的强化学习框架往往无法支持高效、定制化的训练场景的问题。近日,GitHub 上一个名为 JORLDY 的开源、可定制强化学习(RL)框架引发关注。项目地址:https://github.com/kakaoenterprise/
(本文阅读时间:24分钟)编者按:近一年来,Transformer 在计算机视觉领域所带来的革命性提升,引起了学术界的广泛关注,有越来越多的研究人员投入其中。Transformer 的特点和优势是什么?为什么在计算机领域中 Transformer 可以频频出圈?让我们通过今天的文章来一探究竟吧!“统一性”是很多学科共同追求的目标,例如在物理学领域,科学家们追求的大统一,就是希望用单独一种理论来解释
分享展示神经网络的N个利器。1、PlotNeuralNet使用Latex绘制神经网络。传送门:https://github.com/HarisIqbal88/PlotNeuralNetFCN-8模型overleaf上Latex代码:https://www.overleaf.com/read/kkqntfxnvbskFCN-32模型overleaf上Latex代码:https://www.overl
近日,一篇名为《GFlowNet Foundations》的论文引发了人们的关注,这是一篇图灵奖得主 Yoshua Bengio 一作的新研究,论文长达 70 页。在 Geoffrey Hinton 的「胶囊网络」之后,深度学习的另一个巨头 Bengio 也对 AI 领域未来的方向提出了自己的想法。在该研究中,作者提出了名为「生成流网络」(Generative Flow Networks,GFlo
本文首先从深度学习的流程开始分析,对神经网络中的关键组件抽象,确定基本框架;然后再对框架里各个组件进行代码实现;最后基于这个框架实现了一个 MNIST 分类的示例,并与 Tensorflow 做了简单的对比验证。 >>加入极市CV技术交流群,走在计算机视觉的最前沿当前深度学习框架越来越成熟,对于使用者而言封装程
点击蓝字关注我们#TSer#时间序列知识整理系列,持续更新中 ⛳️赶紧后台回复"讨论"加入讨论组交流吧 ????最近,图神经网络技术应用到时间序列的分析,引起了学术界广泛的研究兴趣。本次文章分享两篇最近阅读的,图神经网络用于时间序列异常检测的论文。首先对于多变量时间序列,我们可以将其看作一个矩阵 ,由k个变量,n个时刻组成,由于异常通常是少见的,大部分异常检测方法的套路是采用正
本文带领大家深入了解了GraphRAG技术,这是一种融合知识图谱来强化RAG应用的创新手段。GraphRAG特别擅长处理那些需要跨信息片段进行多步骤推理和全面回答问题的复杂任务。结合Milvus向量数据库后,GraphRAG能够高效地在庞大的数据集中探索复杂的语义联系,从而得出更精准、更深刻的分析结果。这种强强联合的解决方案,使GraphRAG成为众多实际通用人工智能(GenAI)应用中的得力助手

PyG(PyTorch Geometric)是一个基于PyTorch的图神经网络框架,建议先了解PyTorch的使用再学习PyG,要不然看不懂。本文内容角度,喜欢本文点赞支持、欢迎收藏学习。PyG包含图神经网络训练中的数据集处理、多GPU训练、多个经典的图神经网络模型、多个常用的图神经网络训练数据集而且支持自建数据集,主要包含以下几个模块torch_geometric:主模块torch_geome
