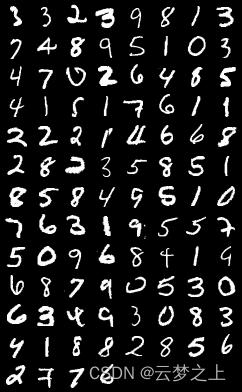- @m0_52985451
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
使用chrome浏览器报错无法找到 www.baidu.com 的 DNS 地址。说明DNS存在问题。我按按如下方法操作可以重新访问了。打开chrome浏览器1.点击设置按钮2.点击隐私设置和安全性,然后点击安全3:找到使用安全DNS,进行重置。(可以先把按钮关掉,然后在打开,也可以切换线面的设置然后换回:使用你当前的服务提供商)4:然后进行重新搜索,发现可以正常搜索了。...
本文分享了两个ComfyUI 的节点,分别是一个负责将ComfyUI的连线变为直线的节点,和一个将ComfyUI的工作流转化为可执行的Python代码的节点。

由复旦、微软、虎牙、CMU的研究团队提出的StableAnimator框架,实现了高质量和高保真的ID一致性人类视频生成。当前的人类图像动画扩散模型很难确保身份 (ID) 的一致性。本文介绍了 StableAnimator,这是第一个端到端保留 ID 的视频扩散框架,它无需任何后处理即可合成高质量视频,以参考图像和一系列姿势为条件。StableAnimator 以视频扩散模型为基础,包含精心设计的

SEEDStory这篇论文提出的StoryStream这个数据集里面的。我们常用的故事可视化的数据的大小为128*128,图像的质量不是很好,本文提出的数据集的大小为854 * 480,数据的质量比较高本数据集包含3个子数据集。

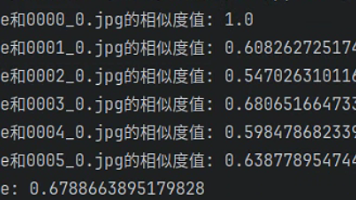
这篇文章介绍了CLIP模型及其图像文本相似度计算方法。主要内容包括: CLIP模型是基于对比学习的跨模态模型,通过计算图像和文本特征的余弦相似度来衡量其匹配程度。 提供了使用CLIP模型计算相似度的代码实现流程。
多功能性:Florence-2能够执行图像描述、目标检测、视觉定位和图像分割等多种计算机视觉任务。

监督学习-Regression一:模型搭建(初始版)这里采用的模型:sklearn.linear_model importLinearRegressionsklearn 库中,线性模型中的,线性回归(最小二乘法)1.1加载数据集from sklearn import datasetsboston=datasets.load_boston()data=boston.data#Xtarget=bost
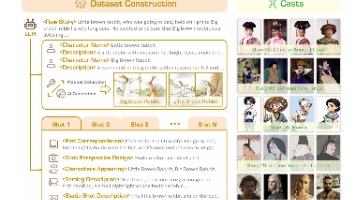
ViStoryBench是一个专为故事可视化任务设计的多样化多模态基准数据集,包含80个涵盖多种类型和视觉风格的故事。数据集通过结构化剧本形式呈现,每个故事包含角色描述、分镜脚本和参考图像,强调角色一致性和叙事连贯性。数据构建流程包括故事收集、角色图像处理、分镜脚本设计和自动化评估指标设计,支持文本到图像序列生成、角色一致性建模等任务。数据集提供中英双语版本,包含完整版和精简版,并开放评估代码和提
研究方向:故事可视化论文链接项目地址故事可视化在人工智能领域得到了越来越多的关注。然而,现有的方法仍然难以保持角色身份保存和文本-语义对齐之间的平衡,这在很大程度上是由于缺乏对故事场景的详细语义建模。StoryWeaver 是一个统一的世界模型,用知识增强来进行故事角色的定制化设计,可以应用在故事绘本领域。不同故事可视化的方法的比较之前的故事可视化方法会面临角色不一致以及语义不匹配的问题。本文提出

通过用minist数据集进行训练,得到一个GAN模型,可以生成与minist数据集类似的图片。GAN是一种生成模型,它的目的是通过学习真实数据的分布来生成新的数据。GAN由两个网络组成,一个是生成器(Generator),一个是判别器(Discriminator)。生成器的任务是从随机噪声中生成类似于真实数据的样本,判别器的任务是判断给定的样本是真实的还是生成的。