




- @m0_50913327
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了基于FunASR框架的音频通话质量分析系统开发实践。作者针对单一语种(中文/英文)的离线音频转写需求,对比了两种语种识别方案,最终选择使用cam++模型进行语种识别。文章详细阐述了FunASR框架的核心功能(包括语音活动检测、自动语音识别等)及其存在的5个主要问题,并分享了开发思路和Python测试流程,包括模型选择、风险分析和部署方案。通过实际案例展示了语种识别和英文音频识别的具体实现

我们不妨先给大家讲一个概念,利用此概念我们正好给大家介绍一个数据库优化的小技巧:需求如下:将一个用户表的数据导出800万条。如果你不假思索,直接一条sql语句搞上去,直接就会内存溢出,因为mysql会将结果记录统一查询出来然后返还给内存:那内存可能直接OOM!@Test// 1、定义资源try {// 获取连接// 获取使用预编译的statement// 关闭资源。

本文推荐五个开源AI与多媒体处理工具:1) TestSpec - 结构化测试工作流工具,支持AI辅助测试用例生成;2) mediamtx-clients-ts - 多媒体流处理客户端,支持WebRTC和QUIC协议;3) RapidOCR-API - 智能OCR识别服务,支持PDF和图像文字识别;4) Qwen3-ASR-GGUF - 高效语音转写工具,实现CPU实时转写;5) mxr-voice
本文介绍了基于FunASR框架的音频通话质量分析系统开发实践。作者针对单一语种(中文/英文)的离线音频转写需求,对比了两种语种识别方案,最终选择使用cam++模型进行语种识别。文章详细阐述了FunASR框架的核心功能(包括语音活动检测、自动语音识别等)及其存在的5个主要问题,并分享了开发思路和Python测试流程,包括模型选择、风险分析和部署方案。通过实际案例展示了语种识别和英文音频识别的具体实现
本文推荐五个开源AI与多媒体处理工具:1) TestSpec - 结构化测试工作流工具,支持AI辅助测试用例生成;2) mediamtx-clients-ts - 多媒体流处理客户端,支持WebRTC和QUIC协议;3) RapidOCR-API - 智能OCR识别服务,支持PDF和图像文字识别;4) Qwen3-ASR-GGUF - 高效语音转写工具,实现CPU实时转写;5) mxr-voice
● 打开代理配置>License管理页面,可以看到系统已经自动为管理员初始化了一条License记录,复制该LicenseKey备用,后续客户端配置需要。,下载最新的release包:neutrino-proxy-server.jar、neutrino-proxy-admin.zip。● 将neutrino-proxy-server.jar、neutrino-proxy-admin.zip上传至服

语音识别技术概述 语音识别(ASR)是将人类语音转换为文本的技术,经历了从早期模式匹配到现代深度学习的发展历程。当前ASR系统通常采用模块化pipeline处理流程,包括语音活动检测(VAD)、主识别模型、标点预测(PUNC)和文本标准化(ITN)等环节。主流的开源方案有阿里的FunASR、小红书的FireRedASR和k2-fsa的sherpa-onnx等。现代端到端模型虽然强大,但在长音频处理
本文介绍了大模型微调的技术要点和参数优化方法。首先说明了项目环境配置,包括镜像设置和关键依赖安装(transformers、peft等)。重点分析了全量微调的计算成本,详细拆解了模型权重、梯度、优化器状态和中间激活值的内存需求。通过数学公式推导了梯度下降原理,解释了优化器(如AdamW)如何通过动量矩和方差矩解决训练中的方向不稳定和参数尺度差异问题。文章为高效微调大模型提供了理论基础和实践指导,特
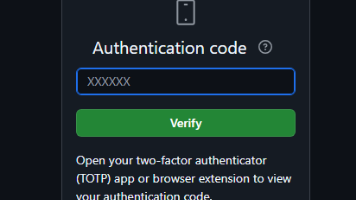
摘要:文章记录了一起GitHub账户双重验证(2FA)恢复案例。用户因删除恢复码且更换手机设备导致无法登录,仅保留账号密码和SSH密钥。主要解决步骤包括:1)登录时遇到设备验证码要求;2)进入双重验证界面;3)选择SSH验证方式(使用ssh -T git@github.com verify命令);4)通过SSH密钥成功完成身份验证。该过程展示了在丢失常规2FA验证方式时,利用SSH密钥恢复账户访问
rabbitmq-plugins enable rabbitmq_delayed_message_exchange-3.8.0.ez修改为rabbitmq-plugins enable rabbitmq_delayed_message_exchange不要加版本号