




- @m0_50180963
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
篇幅有限,其他内容就不在这里一一展示了。

做过CRUD Boy的都懂,你会发现每个实体类都包含create_time、update_by等重复字段。手动维护这些字段不仅效率低下,还容易出错。本文将分享一套经过生产验证的自动化方案,涵盖MyBatis-Plus、AOP、JWT等六种核心策略,助你彻底摆脱公共字段维护的烦恼。痛点总结:代码重复率高(每个Service方法都要设置)维护成本高(字段变更需修改多处)容易遗漏(特别是更新操作)2.2
国内的互联网面试,恐怕是现存的、最接近科举考试的制度。而且,我国的八股文(基础知识、集合框架、多线程、线程的五种状态、虚拟机MySQLSpring相关、计算机网络MQ系列等)确实是独树一帜。以美国为例,北美工程师面试比较重视算法(Coding),近几年也会加入Design轮(系统设计和面向对象设计OOD)和BQ轮(Behavioral question,行为面试问题),今天博主为大家熬断半头青丝捋
小编分享的这份秋招 Java 后端开发面试总结包含了 JavaOOP、Java 集合容器、Java 异常、并发编程、Java 反射、Java 序列化、JVM、Redis、Spring MVC、MyBatis、MySQL 数据库、消息中间件 MQ、Dubbo、Linux、ZooKeeper、 分布式 &数据结构与算法等 25 个专题技术点,都是小编在各个大厂总结出来的面试真题,已经有很多粉丝靠这份

面试,跳槽,每天都在发生,而对程序员来说"金九银十"更是面试和跳槽的高峰期,跳槽,更是很常见的,对于每个人来说,跳槽的意义也各不相同,可能是一个人更向往一个更大的平台,更好的地方,可以通过换一个环境改变自己的现状。而我正是其中一员,投了十多家互联网公司,目前 已收到五个 Offer,其实跳槽是把双刃剑,有好也有坏,要看你是因为什么原因跳槽。如果说你即将准备跳槽,是否准备充足了呢?小编即将分享的正是
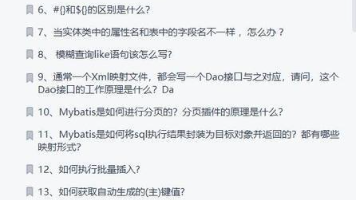
文章写到这里差不多可以停笔了,但是又好像还想说点什么,或许是对同行的你一些小建议,也或许是对整个行业的一些愿景。近几年来,铺天盖地而来的“程序员 35 岁”制造了不少年龄焦虑,试问自己被公司裁员,被社会淘汰真的是年龄导致的吗?实际上,无论你是什么行业,能力不过关,都会被淘汰,而避免被淘汰的唯一办法:坚持学习。最近也是一直有粉丝朋友私信我说,2025金九银十 都快来了,LZ 有没有一份内容全面,题目
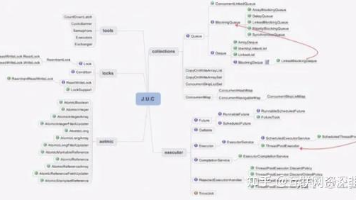
作为一个 Java 程序员,你平时总是陷在业务开发里,每天噼里啪啦忙敲着代码,上到系统开发,下到 Bug 修改,你感觉自己无所不能。然而偶尔的一次聚会,你听说和自己一起出道的同学早已经年薪 50 万,而自己却囊中羞涩。于是你也想看看新机会,找个新平台,好好发展。但是面试的时候,当那个笑眯眯的面试官问出那些你再熟悉不过的 Java 问题时,你只是感觉似曾相识,却怎么也回答不到点上。比如 HashMa
宅在家里,“闭关修炼”的你是不是正在为金九银十跳槽季发愁呢?Java 集合 22 题及答案解析JVM 与调优 21 题及答案解析并发编程 28 题及答案解析Spring 25 题及答案解析23 种设计模式解析Spring Boot25 题及答案解析分布式高并发架构解析(消息队列,分库分表,事务,高可用,微服务架构)MySQL 高频 20 题解析Redis45 题及答案解析。
我相信大多 Java 开发的程序员或多或少经历过 BAT 一些大厂的面试,也清楚一线互联网大厂 Java 面试是有一定难度的,小编经历过多次面试,有满意的也有备受打击的。因此呢小编想把自己这么多次面试经历以及近期的面试真题来个汇总分析,阐述下如何去准备,去回答面试官的提问,可以和面试官有个愉快的交谈。

我相信大多 Java 开发的程序员或多或少经历过 BAT 一些大厂的面试,也清楚一线互联网大厂 Java 面试是有一定难度的,小编经历过多次面试,有满意的也有备受打击的。因此呢小编想把自己这么多次面试经历以及近期的面试真题来个汇总分析,阐述下如何去准备,去回答面试官的提问,可以和面试官有个愉快的交谈。
