




- @m0_44969266
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
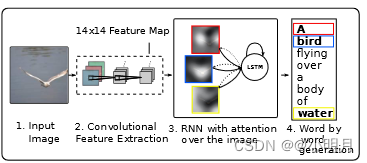
像上一篇show,attend and tell论文中,要求预测生成a,of这些不能与图像中的视觉信息相对应的虚词,量词时,仍然要关注一块区域与这些词对应起来。这种情况其实是没有必要的。本文解决的就是这种问题。在这篇文章中,提出了一种新颖的带有视觉哨兵(visual sentinel)的自适应注意力模型( adaptive attention model)。在每个时间步骤,模型决定是否关注图像(如

3.但是这样还是不能解决这个问题,我的路径好像赋值不够准确(sorry)再进行查看,发现train.py的161行对detections_path用args.features_path进行了赋值,所以要继续查看这个args.features_path,我尝试打印args.features_path的值,果然打印出来是None。(下载真的慢的要死)我忽略了一点,我要用m2release这个虚拟环境的
*解决方法:**在Vscode终端输入:npm install -g vite。下载成功后即可运行npm run dev命令。

复现Show,Attend and tell代码

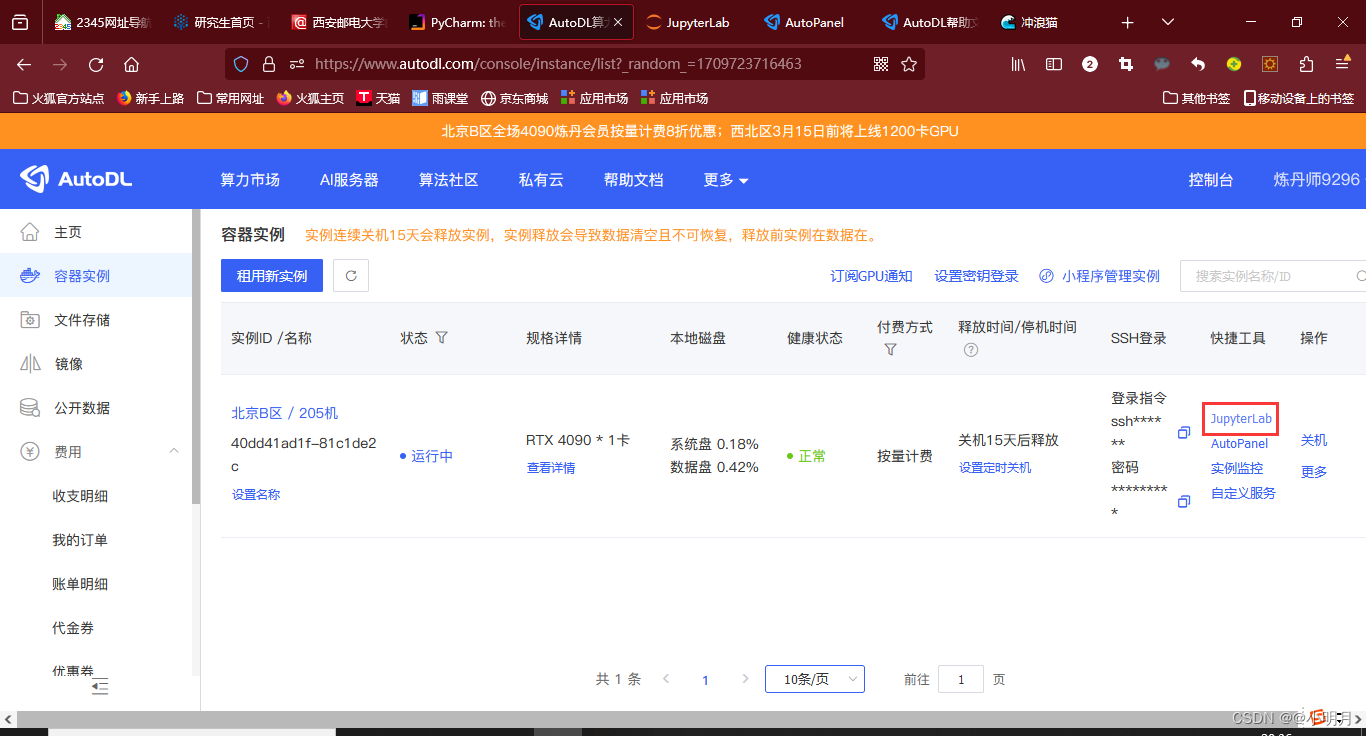
利用Pycharm远程连接AutoDL
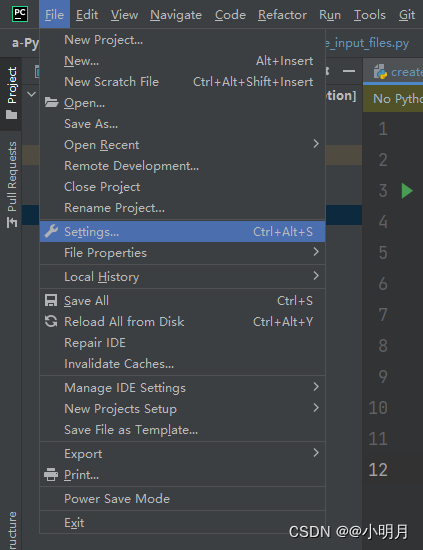
点击File,点击settings,接着选择Python Interpreter,点击Add Interpreter,选择On SHH接下来就要填写SSH的主机,端口号,用户名。从阿里云服务器官网复制自己购买的服务器的公网IP地址,这样就得到了主机。用户名通常是root,但是我在后面重置密码的时候发现我的密码是administrator,端口号用默认的就行,然后点击Next。接着需要填写密码,但是
点击自定义服务,弹出以下界面:运行Windows+R,输入cmd,然后在命令行按照上面的提示操作就可。接着打开浏览器:输入http://localhost:6006,成功显示。
点击File,点击settings,接着选择Python Interpreter,点击Add Interpreter,选择On SHH接下来就要填写SSH的主机,端口号,用户名。从阿里云服务器官网复制自己购买的服务器的公网IP地址,这样就得到了主机。用户名通常是root,但是我在后面重置密码的时候发现我的密码是administrator,端口号用默认的就行,然后点击Next。接着需要填写密码,但是