- @liulilittle
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文实现了基于双向链表的数据结构,包含KList和KNode两个核心类。KList提供链表管理功能,包括头尾节点操作(AddHead/AddTail、RemoveHead/RemoveTail)、节点计数和空链表判断。KNode实现双向链表节点,支持前后节点插入(InsertBefore/InsertAfter)、节点移除(Remove)和连接状态检查(IsLinked)。通过头尾哨兵节点优化边界
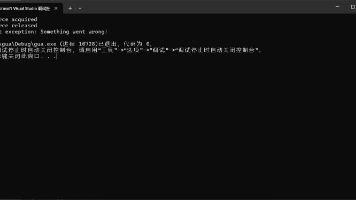
摘要:编译liburing时出现linux/time_types.h缺失错误,是由于内核头文件版本过旧。解决方案包括:1)清理后重新运行configure脚本自动适配;2)手动定义UAPI_LINUX_IO_URING_H_SKIP_LINUX_TIME_TYPES_H宏跳过该头文件。这两种方法无需升级系统内核头文件,即可成功编译liburing库。(149字)
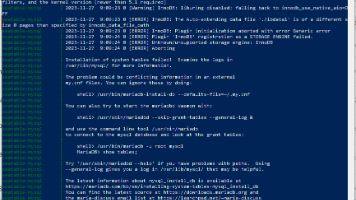
本文介绍了在Linux系统中配置Swap文件的完整流程。首先通过free -h检查现有Swap状态,然后使用dd命令创建指定大小的Swap文件并设置权限。接着用mkswap格式化并swapon启用Swap,通过修改/etc/fstab实现持久化挂载。文章建议调整swappiness值为10以减少磁盘I/O,并提供了Swap大小配置建议(内存小于8GB设为2倍,大于8GB等量或略小)。注意事项包括操

这篇文章是Claude Code AI助手的操作速查表,主要内容包括: 启动与权限模式:介绍不同启动方式和权限模式切换 配置文件管理:说明全局和项目配置的位置及权限设置 会话管理:包括重命名、清空、回溯和删除会话等操作 上下文与Token管理:查看占用情况、压缩上下文等命令 模型切换与技能安装:手动切换模型和安装自定义技能的方法 MCP服务器配置:如何设置和管理MCP服务器 持续工作方法:提供多种

这篇文章分析了@prevalentware/opencode-goal-plugin插件存在的问题及替代方案。主要观点如下: 问题:该插件虽然提供了类似Claude Code的便捷目标管理功能,但会破坏OpenCode的缓存机制,导致缓存命中率降至0%,每次请求成本高达$0.05,是原生方式的4倍。 原因:插件实现不当,包括强制重新注入完整会话上下文、动态更新目标状态信息、可能触发进程重启、与官方

本文档详细阐述了某MMO项目中麻将子游戏系统的分布式架构设计。系统作为畅玩阁(SmallGame)的组成部分,采用五服务器角色(GameServer、PlayServer、GameCenter、MatchCenter、SceneServer)协同工作,实现跨服麻将玩法。架构通过模块化设计分离游戏逻辑与基础设施,客户端和服务端共享部分核心组件但运行不同脚本。文档特别分析了玩家切图导致的"半开闭状态"

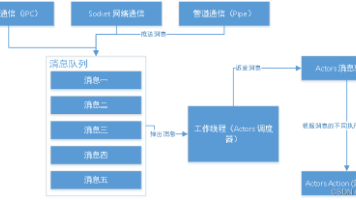
摘要:本文深入剖析基于消息驱动的Actor异步编程模型,重点介绍其在C++中的实现与工程实践。通过线程-执行器拓扑结构和类图展示Actor核心架构,每个Actor绑定独立线程确保线程安全。消息处理机制采用无锁并发队列,包含详细的序列化实现和生命周期管理。与传统线程模型相比,Actor模型通过资源管理器统一处理消息,有效解决共享资源竞争问题。文章提供了完整的消息结构内存布局和C++序列化代码示例,为
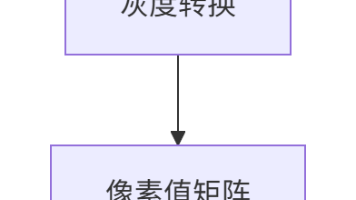
本文深入探讨了C#图像转字符画技术的数学原理与工程实现。首先从线性代数基础出发,详细解析了颜色矩阵变换的数学原理,包括齐次坐标系统、灰度转换矩阵推导和亮度对比度矩阵实现。接着探讨视觉感知模型,分析人眼视觉特性与NTSC灰度转换算法,并给出考虑伽马校正的优化实现。最后介绍了高质量图像缩放的核心算法——双三次插值的数学原理与高效实现方案,为构建完整的图像转字符画系统提供了理论基础和工程实践指导。
C++可变参数打印技术演进 递归模板(C++11):通过类型推导和编译期递归展开参数包,生成多级函数调用栈,可能导致代码膨胀但支持精细类型处理。 初始化列表(C++14):利用std::initializer_list的顺序保证和逗号表达式特性,实现线性展开,避免递归深度问题,适合线程安全场景。 折叠表达式(C++17):直接展开为运算符链,生成最优化的线性代码结构,编译速度快且支持编译期计算,是
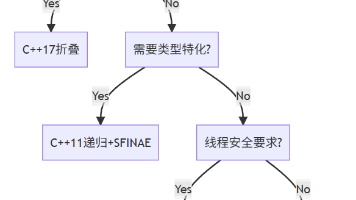
C++工业级异常处理与防御性编程实践 本文系统阐述了C++异常处理的核心机制与防御性编程策略: RAII与异常安全:澄清了throw会触发RAII析构的真相,强调非RAII管理资源的危险性,并演示了智能指针等RAII包装器的正确用法。 契约式设计:详细介绍了前置条件检查、后置条件验证和不变条件维护的实践方法,通过代码示例展示如何构建健壮的接口契约。 异常安全等级:构建了完整的异常安全保证体系,从基