




- @jsjsjeshjsjd
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
修仙(高并发)路上,锁机制(synchronized)太内卷,大家都排队?ThreadLocal 另辟蹊径,直接开启“空间复制大法”,一人一个副本,各玩各的。可惜,此功法有个致命罩门——内存泄漏,一旦停留在线程池这片“长生禁地”,必遭 OOM 天劫。本文为你复盘这场修仙惨剧,看原生 ThreadLocal 如何翻车,以及阿里 TTL 如何用“捕获、重放、还原”三大仙术逆天改命!

在并发修仙界,很多新手以为创建线程像呼吸一样简单?错!随意 new Thread 就像无限制招收外门弟子,早晚导致宗门(服务器)资源耗尽而崩塌。真正的强者懂得利用线程池这座“护宗大阵”——核心线程是内门长老,队列是待办任务堂。但小心!若不懂拒绝策略这道“天劫防线”,一旦任务积压如山,你的系统就会当场走火入魔,抛出 RejectedExecutionException!本文带你参透 ThreadPo

在数据库高并发场景下,海量事务同时读写同一份数据,单纯依赖锁机制相互制衡,只会造成无休止的阻塞等待;脏读、不可重复读与幻读,更如同忍界无解的幻术,牢牢桎梏着系统性能。正如这幅图中,宇智波鼬借 Undo Log 铺展绵延不绝的数据历史分身版本链,佐助则凭借 ReadView 写轮眼,筛选出仅对当前事务可见的数据快照。MVCC 正是数据库世界里独一份的宇智波瞳术,它摒弃锁竞争的对抗思路,依托多版本数据

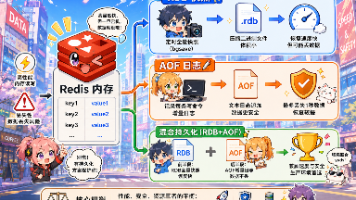
Redis 号称内存数据库中的“速度狂魔”,但你是否想过,当服务器突然宕机或断电时,那些在内存中飞速流转的数据,难道只能眼睁睁看着它们灰飞烟灭?在追求极致性能与保障数据安全之间,Redis 究竟是如何巧妙平衡的?它又是如何通过 RDB、AOF 以及混合持久化,在“定时拍快照”与“逐条记流水账”之间,为你量身定制出一套完美的数据兜底方案?
很多人第一次使用 ChatGPT 时,都会产生一种错觉:“AI 好像真的记得我之前说过的话。但当我真正开始做 RAG 项目后,我才发现:大模型其实根本“不记得”你。所谓的“记忆”,本质上只是:应用层在每次请求时,把历史聊天记录重新发给模型。而这也引出了 AI 应用开发里一个非常核心的问题:如何让模型“看起来有长期记忆”,同时又不让 Token 成本爆炸?
任何工具只要实现了 MCP 协议,就能被任何支持 MCP 的客户端调用,无需关心对方是什么语言、什么平台。这实现了真正的解耦。效果:知识检索不再局限于特定系统,任何支持 MCP 的客户端(如 Claude Desktop、IDE 插件)都能直接调用企业的知识库。发现慢:工具藏在全是 if-else 的代码里,新人和模型都不知道系统到底有哪些能力。优势:模型自动判断何时查知识库,何时调业务 API,
在并发修仙界,很多新手以为创建线程像呼吸一样简单?错!随意 new Thread 就像无限制招收外门弟子,早晚导致宗门(服务器)资源耗尽而崩塌。真正的强者懂得利用线程池这座“护宗大阵”——核心线程是内门长老,队列是待办任务堂。但小心!若不懂拒绝策略这道“天劫防线”,一旦任务积压如山,你的系统就会当场走火入魔,抛出 RejectedExecutionException!本文带你参透 ThreadPo
任何工具只要实现了 MCP 协议,就能被任何支持 MCP 的客户端调用,无需关心对方是什么语言、什么平台。这实现了真正的解耦。效果:知识检索不再局限于特定系统,任何支持 MCP 的客户端(如 Claude Desktop、IDE 插件)都能直接调用企业的知识库。发现慢:工具藏在全是 if-else 的代码里,新人和模型都不知道系统到底有哪些能力。优势:模型自动判断何时查知识库,何时调业务 API,
在关系型数据库中,我们习惯使用正向索引(Forward Index),即通过主键 ID 去查找具体的记录。文档:用来搜索的基础数据单元(如一个商品信息、一篇博客文章),在 ES 中表现为 JSON 格式。,然后在倒排索引中直接找到包含这两个词条的文档 ID 集合,最后取交集返回结果。1)创建Request对象。字段:字段,就是JSON文档中的字段,类似数据库中的列(Column)filter:必须
工具化架构模式(智能调度):将“搜索知识库”视为一个工具,将“查询业务系统”视为另一个工具。大模型不再直接生成答案,而是先分析用户意图,判断该问题属于“静态知识查询”还是“动态业务操作”,进而自动路由至相应的工具。将“知识库检索”与“业务工具调用”统一抽象为工具,利用大模型的意图识别能力作为智能路由器,根据用户问题的性质动态选择执行路径,从而实现从“被动问答”到“主动服务”的架构升级。我们需要告诉